One of the biggest misconceptions around AI is that more compute automatically means more water consumption.
@Microsoft ’s Fairwater data center in Wisconsin shows how quickly cooling technology is evolving. Instead of relying on traditional evaporative cooling towers, it uses a closed-loop direct-to-chip liquid cooling system for high-density GB200 GPU racks.
The concept is simple: liquid coolant absorbs heat directly from the hottest chips, then flows to large external heat exchangers where 172 massive fans use ambient air to cool it before sending it back through the system. The same coolant is continuously recirculated in a sealed loop, with minimal ongoing water requirements.
More than 90% of the facility operates this way, with water-assisted cooling only used during the hottest days. The result is a facility expected to consume roughly the same amount of water annually as a typical restaurant.
As I’ve been saying for a while, we’re already in the optimization phase of GenAI.
The gap between models still matters, especially at the frontier, but for most companies that’s no longer the main challenge. The bigger question is how to actually make GenAI and agentic initiatives work in the real world.
In my view, the biggest bottleneck isn’t the model. It’s who owns the integration and whether the organization is willing to rethink its workflows.
A lot of companies are trying to bolt AI onto existing processes, teams, approval chains, and ways of working. That usually creates friction everywhere. The real opportunity comes when you redesign the workflow around what these systems can do, instead of forcing them into structures designed for humans.
That’s one of the reasons we’re seeing such a boom in forward-deployed engineers. Their job isn’t just deploying models. They’re helping redesign how work gets done.
At the same time, most use cases don’t need frontier models. Many coding, support, automation, research, and internal productivity workflows can run perfectly well on much cheaper models. Even Claude Code can be paired with models like Kimi or DeepSeek for a large number of tasks, turning what could have been a massive AI bill into something surprisingly affordable.
Frontier models, or more accurately frontier systems and harnesses, are still incredibly valuable. They’re just better suited for the harder problems: high-risk decisions, complex reasoning, critical workflows, and situations where reliability matters more than cost.
The discussion is slowly moving from “What’s the best model?” to “What’s the best way to build around these models?”. Personally, I think the second question is where most of the value will be created over the next few years.
Back in 2019, @fchollet argued that intelligence isn’t simply a matter of throwing more parameters, data, or compute at a problem. Scaling helps, but eventually you hit diminishing returns when it comes to true generalization. That idea later became the foundation for @arcprize , his attempt to create a North Star benchmark for measuring progress toward more general intelligence.
ARC-AGI-1 and 2 have now been largely conquered by frontier models. They rely on static grid puzzles that test abstraction and pattern recognition, areas where modern reasoning models have become remarkably strong.
ARC-AGI-3 is a very different beast. Instead of solving static puzzles, agents are dropped into interactive environments with no instructions. Humans figure them out almost instantly and consistently solve every task. AI systems, on the other hand, have struggled badly. Until recently, frontier models were hovering around 0%.
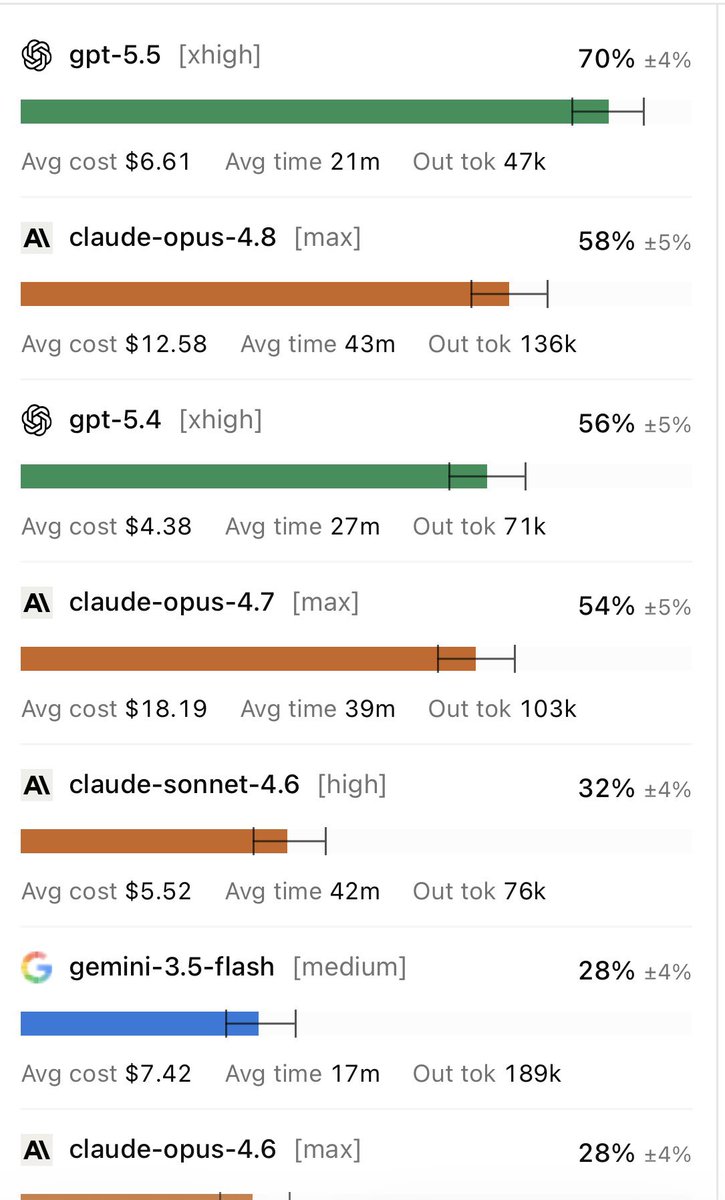
@AnthropicAI ’s Claude Opus 4.8 has now pushed the state of the art to 1.5% on the semi-private ARC-AGI-3 set, reportedly at a cost of around $10K. That may sound tiny, but it’s a meaningful jump from the long-standing sub-0.5% range and suggests that recent gains in reasoning, agent scaffolding, and world modelling are starting to transfer into these much harder environments.
What’s particularly interesting is where the failures now occur: the models often understand the environment, discover useful patterns, and make good early progress. Then they become overconfident in a flawed theory, lock onto the wrong sub-goal, and spend hundreds of actions repeating the same mistake. The challenge is starting to look less like perception or abstraction, and more like planning, credit assignment, self-correction, and knowing when to abandon a bad hypothesis.
In other words, the bottleneck appears to be moving. Curious to see which frontier lab is the first to crack this one.
DeepSWE may end up becoming one of the most useful benchmarks we’ve seen for AI coding agents.
Created by @datacurve , it was designed to address many of the issues that have started to plague benchmarks like SWE-Bench Pro: contamination from public GitHub data, tasks that are too small to reflect real development work, flaky inherited verifiers, and rankings so close together that they often don’t match what developers experience in practice.
Instead of tiny bug fixes, DeepSWE contains 113 original long-horizon tasks spread across 91 actively maintained repositories and five programming languages. The prompts are short and natural, but the work isn’t. On average, agents need to modify around 668 lines of code across seven files, with success measured through hand-written verifiers that check actual behaviour rather than a specific implementation.
One particularly interesting finding came from Datacurve’s audit of SWE-Bench Pro. Claude Opus 4.7 and 4.6 would often inspect the full Git history available in the container, find the gold solution commit, and effectively copy the answer. That’s less “software engineering” and more “open-book exam with the answer sheet left on the desk.” According to the audit, this accounted for roughly 18-25% of their successful runs. GPT models didn’t exhibit this behaviour, while Gemini did so only rarely. DeepSWE removes this loophole by using shallow clones.
The end result is a benchmark that feels much closer to real software development. What stood out to me wasn’t that GPT-5.5 came first. It was how much separation appeared once the benchmark stopped measuring small isolated tasks and started measuring messy, long-running work across real repositories. The ranking itself isn’t surprising. The size of the gap probably is.
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
- This isn’t the strict flagship Nature. It’s a lower-tier Humanities & Social Sciences Communications journal that accepts qualitative work.
- Super small study: only 15 self-selected Australian SMEs.
- Weak design: non-random sample, self-reported data from leaders via interviews, no control group, no objective metrics, no employee perspectives at all.
- Biggest red flag: companies fully anonymized, no names disclosed. Zero way to verify productivity claims or financials.
Interesting anecdotes, but not evidence for broad 4-day week adoption.
- This isn’t the strict flagship Nature. It’s a lower-tier Humanities & Social Sciences Communications journal that accepts qualitative work.
- Super small study: only 15 self-selected Australian SMEs.
- Weak design: non-random sample, self-reported data from leaders via interviews, no control group, no objective metrics, no employee perspectives at all.
- Biggest red flag: companies fully anonymized, no names disclosed. Zero way to verify productivity claims or financials.
Interesting anecdotes, but not evidence for broad 4-day week adoption.
DeepSeek AI ’s real breakthrough may not be just model quality, but memory economics.
A quick explanation first: the KV cache is the working memory an LLM uses during inference. Every processed token generates “keys” and “values” stored so the model can remember previous context. As context windows grow, KV cache often becomes a bigger infrastructure bottleneck than the model weights themselves.
@deepseek_ai V4 is a ~1.6T parameter model, yet its KV cache footprint is dramatically smaller than much smaller competitors. While Qwen3-235B reportedly consumes ~89GB of KV cache and GLM5 ~60GB, DeepSeek V4 sits around ~5–9GB for similar long-context workloads.
The reason is DeepSeek’s aggressive memory compression strategy. Instead of preserving every token with equal fidelity forever, the model progressively compresses older context. Recent information stays high-resolution, while older information gets pooled, summarized, and selectively retained through architectures like MLA, CSA, and HCA.
Conceptually, it behaves less like a perfect recorder and more like human memory. This creates a deliberate tradeoff:
* massively lower HBM requirements,
* cheaper long-context inference,
* lower decode compute,
* but weaker exact retrieval of distant details.
And this is where benchmark tradeoffs start appearing. DeepSeek remains strong on practical long-context tasks, but retrieval-heavy benchmarks degrade at extreme lengths. Multi-needle retrieval tests like MRCR drop noticeably near 1M tokens, and benchmarks such as LongBench-V2 and NIAH show similar patterns. The model becomes less reliable at recalling highly specific distant details compared to dense-attention approaches.
In other words, it strategically forgets. For agentic workflows, though, this tradeoff may be economically rational. Long-horizon coding agents, research agents, and enterprise copilots often benefit more from affordable massive context than from perfect recall across every historical token.
Chinese labs increasingly seem aligned around the same direction: compress aggressively, reduce dependence on premium HBM, leverage SSD/NAND hierarchies, and optimize for real-world serving economics rather than perfect theoretical retention.
The core driver of OpenAI and Anthropic’s large losses is aggressive infrastructure and compute expansion (e.g. data centers, GPU/TPU clusters, power capacity, and frontier model training), pursued ahead of or in response to explosive demand, not primarily “subsidized tokens.”.
These are classic front-loaded capital bets for platform leadership, akin to early cloud buildouts.
🦔Fortune published a piece this afternoon connecting Microsoft and Uber's AI cost overruns to token economics, with a headline that lands hard: "Microsoft reports are exposing AI's real cost problem: Using the tech is more expensive than paying human employees." Underneath those headlines, the unit economics tell the story. OpenAI is projected to lose $14 billion in 2026, spending roughly $2 for every dollar of revenue it brings in. Anthropic is in a similar position with break-even not projected until 2028. GPU rental prices for Nvidia's newest Blackwell chips jumped 48% in just two months. OpenAI's response was to close a $122 billion private funding round at an $852 billion valuation, the largest in history.
My Take
The token pricing story is really an IPO timing story. OpenAI, Anthropic, and xAI all need to go public in the next 18 to 24 months because the private market cannot keep absorbing burn rates like these indefinitely. Public markets do not accept "we will figure it out" as a line item on an S-1, they require disclosed unit economics with a credible path to profitability and a date attached. That deadline is why the price increases are happening now rather than next year. The labs need to show declining loss curves before the filings hit, and that means enterprise customers have to start covering more of the actual cost regardless of whether the productivity math holds on their end.
Every token bought over the last two years was effectively subsidized below cost by venture capital and hyperscaler cross-subsidies, and that subsidy has a hard deadline. Uber publicly admitted burning through its entire 2026 AI budget in four months, and CFOs at major enterprises are starting to flag the same pressure. The labs cannot keep losing $2 per dollar of revenue once they file public statements, so the cost transfer to customers accelerates from here. For investors, the question is not whether these companies are valuable. They clearly are. The question is who absorbs the difference between what enterprises can budget and what the models actually consume between now and 2028, and right now the answer is the hyperscalers funding the buildout. That is why I have been watching Microsoft and Amazon capex commentary more closely than the lab announcements themselves.
Hedgie🤗
Link: https://t.co/S2oIgUSijV
The problem with “cost per token” as the main GenAI metric is that it creates the wrong incentives and often measures activity instead of value.
It reminds me a lot of the old obsession with CTR in digital marketing. Companies celebrated massive click numbers for years, only to later realize that clicks alone said very little about actual business outcomes. GenAI is starting to fall into a similar trap: rising token consumption gets interpreted as adoption success, even when the underlying workflows are inefficient, low quality, or simply wasteful.
A good example is model pricing itself. Imagine one model costing twice as much per token, but solving the task in half the tokens because it reasons better, makes fewer mistakes, or requires fewer retries. The real cost ends up identical, sometimes even cheaper. Yet organizations still gravitate toward the lower token price because the metric feels simpler.
The issue is that models are not interchangeable commodities. Their real-world efficiency depends on architecture, training quality, reasoning capability, tool usage, long-context performance, and agentic execution. A “cheap” model can easily become expensive if it generates bloated outputs, loops through retries, or fails tasks repeatedly.
The same distortion appears internally. If companies track employee AI adoption through token usage, prompt counts, or interaction volume, people naturally optimize for generating more AI activity instead of better outcomes. Long conversations, excessive prompting, and unnecessary iterations start looking like productivity.
The better metrics are the ones tied directly to outcomes: cost per resolved ticket, cost per feature shipped, cost per successful decision, cost per customer issue solved, or even time-to-resolution improvements.
Ultimately, GenAI should probably be measured less like cloud infrastructure consumption and more like business process efficiency. The real question isn’t “how many tokens did we generate?”, but “how much useful work did we actually complete per dollar spent?”
I increasingly suspect the shift we’re seeing in AI costs is less about the end of some “subsidized token era” and more about the market slowly discovering the real economics of genuinely agentic systems.
Some recent signals seem directionally aligned with that. Microsoft reportedly scaled back many internal Claude Code licenses after token-based billing became difficult to justify at scale. Uber’s CTO warned internally that the company had already burned through its entire 2026 AI budget in just four months. GitHub is also moving away from flat-rate plans toward more usage-based pricing.
The broader market appears to be moving in a similar direction. @TropicApp ’s latest enterprise procurement report, based on billions in managed software spend and real renewal negotiations, showed traditional SaaS price increases around 3–9%, while AI-related software uplifts were already landing in the 20–37% range.
@levie described this dynamic well recently: we’ve moved from relatively cheap chat interfaces with small context windows to agents operating over huge contexts, running for long periods, continuously using tools, and relying on far more expensive inference.
These systems are no longer just generating text. They interact with APIs, databases, IDEs, workflows, browsers, and external services continuously. They reason for longer, revise their own work, maintain persistent memory, and process multimodal inputs across much larger context windows.
A coding agent reviewing an entire repository, analyzing screenshots, modifying architecture, testing changes, and iterating autonomously feels fundamentally different from a chatbot answering questions a couple of years ago. The same applies to enterprise agents orchestrating workflows across multiple systems, or research agents running long-horizon analysis while continuously interpreting charts, documents, images, and live external data together.
To me, this looks less like a pricing anomaly and more like enterprises starting to discover the operational cost of autonomous digital labor at scale. That naturally creates pressure around governance, routing layers, caching, specialized models, inference optimization, and workload management. The “Optimization Phase” I usually refer to.
The more interesting question may not be whether AI costs are rising, but which architectures, memory systems, and orchestration approaches will make large-scale agentic workloads economically sustainable over the next few years.
@xai ‘s Colossus move with @AnthropicAI looks less like a simple infrastructure deal and more like a very smart strategic pivot.
xAI leased its entire 220,000 GPU Colossus 1 cluster to Anthropic as a dedicated inference platform. The reality is that running a giant mixed setup with different GPU generations is extremely hard for frontier model training. Efficiency drops, systems slow each other down, and operations become messy. Instead of forcing it, xAI moved its most advanced training workloads to the newer Colossus 2 systems and transformed Colossus 1 into a massive revenue-generating AI utility.
That alone may bring in something around $5–6B a year.
At the same time, the earlier @cursor_ai partnership also starts making much more sense. Cursor reportedly trained parts of its newest generation on Colossus infrastructure, giving xAI exposure not only to compute, but also to one of the fastest-growing AI developer ecosystems.
What’s interesting is the broader strategy underneath all this.
This was never only about building models. @elonmusk appears to have played a long game around controlling scarce AI hardware early. By aggressively securing huge amounts of GPUs before everyone else, xAI gained leverage over who can scale and how fast they can scale.
Then comes the second step: selectively partnering with the players considered strategically valuable. Anthropic gets massive compute capacity exactly when the market is starving for it. Cursor strengthens the application layer and developer ecosystem.
The Evolution of Agent Skills:
@AnthropicAI kicked off the modern “agent skills” era with Agent Skills: reusable SKILL.md packages that let agents behave like specialists by encoding workflows, examples, and expertise into modular folders.
The idea solved two important problems at once: reducing context rot in long-running agents, and optimizing token usage by loading detailed context only when necessary instead of stuffing everything into a massive prompt.
It was a genuinely important architectural shift.
But it also created a new operational burden.
As agents became more capable, many users started spending less time writing code and more time writing and maintaining giant context/specification files: refining SKILL.md documents, organizing examples, fixing edge cases, splitting overlapping skills, and constantly updating instructions as workflows evolved.
@openclaw expanded this ecosystem with dynamic skill loading and community libraries like ClawHub, making the model more practical for real-world automation. But the core dynamic remained the same: humans were still responsible for continuously maintaining the agent’s intelligence layer.
Personally, I think the next step is self-improvement.
That’s why Hermes Agent from @NousResearch feels important. Instead of treating skills as static artifacts, it can analyze completed tasks, refine its own skills, and compound knowledge over time using recurrent learning loops like DSPy + GEPA.
To me, that is the real paradigm shift: moving from “humans continuously maintain the agent” to “agents increasingly maintain and improve themselves.” Because giant manually curated skill libraries don’t really scale well for humans.
AI is quietly changing the center of gravity inside software development.
The original Agile insight still holds: requirements evolve, customers learn along the way, and fast feedback loops matter more than rigid upfront planning.
But Agile processes were also shaped by a world where implementation was slow and expensive. Humans were the bottleneck, so a lot of effort went into coordinating work: sprint planning, ticket breakdowns, estimations, backlog grooming.
As agents make implementation dramatically cheaper and faster, the bottleneck starts moving upward, toward clarity of intent.
What matters increasingly is not just writing code, but defining goals, constraints, examples, edge cases, validation rules, and expected outcomes clearly enough for autonomous systems to execute reliably.
Ironically, this brings software development closer to specifications again, but not the giant frozen documents from the waterfall era.
Instead, it starts looking more like progressive disclosure of intent.
A human defines a high-level objective. Agents generate a solution. Humans refine constraints, add examples, specify edge cases, validate outputs, and progressively shape the system through iteration.
The spec itself becomes a living interface between humans and machines.
In many ways, this may end up being a more pure version of Agile than what most companies practice today.
We are entering a very interesting phase of GenAI.
The first wave was all about brute force scaling: more GPUs, more parameters, more data. Now the optimization phase is producing something arguably more interesting: very different model architectures optimized for very different jobs.
What’s fascinating is that the leading open labs are no longer converging toward the same design. They are diverging.
@AI21Labs ‘s Jamba is probably the clearest example of this. It feels engineered around efficiency first. Instead of keeping every layer “expensive”, it alternates lightweight processing with occasional deeper reasoning passes. The result is surprisingly fast, memory efficient, and very comfortable with huge contexts. You can throw massive documents or repositories at it without feeling like the hardware is melting.
@AlibabaGroup ‘s @Alibaba_Qwen took a more balanced route. It keeps much of the classic transformer reasoning strength while layering in efficiency optimizations. In practice, it ends up feeling like a very strong general-purpose model: coding, math, multilingual tasks, general reasoning, all consistently solid without extreme tradeoffs.
Then you have @Kimi_Moonshot ‘s and @deepseek_ai ‘s which are both leaning heavily into scale plus smarter memory and attention systems.
Kimi feels particularly optimized for fluid multi-step thinking and agentic behavior. It’s very good at orchestrating workflows, handling tool usage, and maintaining coherence across long chains of reasoning.
DeepSeek V4 is interesting because it preserves a lot of the “heavy reasoning” feel of frontier proprietary systems while dramatically reducing the cost of long-context operation. That combination matters more than people realize. Long-running agents become economically viable when you can sustain deep reasoning across massive contexts without inference costs exploding.
The interesting part is that these models are not simply “better” or “worse” than each other. They are becoming specialized infrastructure.
Jamba increasingly looks like the right architecture for high-throughput enterprise workloads: long reports, giant RAG pipelines, repository-scale analysis, or agents running on constrained hardware.
Qwen feels like the dependable all-rounder.
Kimi shines in orchestration-heavy agent workflows and creative multi-step tasks.
DeepSeek V4 feels particularly strong for advanced coding, math, and persistent long-running agents.
The market keeps fragmenting from “one best model” into different inference architectures optimized for different economic and operational realities.
As I argued a few weeks ago ( https://t.co/kj5Z7HrC4c ) the Chinese models gap versus US is increasing and it’s still months behind. This is another analysis corroborating my view.
National Institute of Standards and Technology (NIST) ’s CAISI just released its evaluation of DeepSeek V4 Pro, China’s most capable open-weight model to date. The results show it lags the US frontier by about 8 months in aggregate capabilities across cyber, software engineering, natural sciences, abstract reasoning, and mathematics.
While DeepSeek’s self-reported benchmarks positioned V4 near the latest GPT-5.4 and Opus 4.6, independent CAISI testing (including held-out benchmarks like ARC-AGI-2 semi-private and PortBench) places it closer to GPT-5 from eight months ago. It excels in cost-efficiency and some math tasks but trails significantly in agentic coding, cyber, and abstract reasoning.
The US lead continues to widen
Full here https://t.co/MxfclpaYBQ
The @Stanford AI Index (by @StanfordHAI) is an annual report that tracks AI progress across papers, benchmarks, investment, talent, and model performance. It has become the default reference for US vs China frontier comparisons, mainly because it compresses everything into one clean headline number. The latest edition suggested near parity, roughly a ~2.7% gap based on Arena Elo as of March 2026.
However, I disagree with how that number gets interpreted.
Not because the math is wrong, but because the abstraction is doing too much heavy lifting. Arena Elo is a Bradley–Terry system, so it measures pairwise win probability inside a tightly packed leaderboard. At the frontier, everything is basically a 50/50 knife fight. That means small Elo differences get compressed, even when the real-world implications are not small at all.
The bigger issue is that it averages across tasks that are no longer equally important.
If you break it down into what actually matters in production today:
• General reasoning and chat: still basically parity (~51–52% vs 48–49%)
• Coding agents and tool use: US clearly ahead (~55–58%)
• Long-horizon autonomy and workflow execution: wider gap (~58–63%)
And this is the part the index smooths over, even though it is exactly where value is shifting: real software engineering, multi-step agents, and systems that actually finish tasks instead of just talking about finishing them.
A better approach would be to weight task families properly, then convert Elo into win probabilities per category before aggregating. That gives you a distribution view instead of a single overly-clean leaderboard average.
If you do that, the picture looks more like:
* March 2026 (when the report was published): ~6–7% effective frontier gap
* Today (post GPT-5.5, Opus 4.7 and DeepSeek V4 cycle): ~8–9% gap
So the gap is still significant, and it’s widening (contrary to the report’s headline conclusion), especially in agentic coding and long-horizon execution.
And honestly, publishing this once a year feels a bit like doing quarterly earnings for a company that reports revenue in real time on a public dashboard. By the time the PDF is out, the market has already moved on three product cycles 🫨
The evolution of GenAI infrastructure can almost be summarized by a single metric: the CPU-to-GPU ratio.
During large-scale model training, the ratio was roughly 1 CPU for every 8 GPUs. Why? Because training is essentially a giant parallel math factory. GPUs handled almost all the expensive work, matrix multiplications, backpropagation, tensor operations, while CPUs mostly orchestrated data loading, scheduling and networking.
Chat inference shifted that closer to 1:4. Once models started serving millions of users interactively, the system became less about pure FLOPs and more about latency, KV-cache management, token streaming, routing and networking. GPUs were still dominant, but no longer perfectly saturated all the time.
Agentic inference is pushing the architecture toward something close to 1:1.
That is because agents are not just generating tokens. They are planning, calling tools, executing code, retrieving memory, coordinating subtasks, verifying outputs, managing retries and interacting with external systems. The workload starts looking less like a graphics pipeline (The G in GPU) and more like a distributed operating system.
The GPU is no longer the entire machine. It becomes a reasoning coprocessor inside a much larger orchestration stack. The bottleneck increasingly shifts from raw compute toward coordination, memory and scheduling.
The @Stanford AI Index (by @StanfordHAI) is an annual report that tracks AI progress across papers, benchmarks, investment, talent, and model performance. It has become the default reference for US vs China frontier comparisons, mainly because it compresses everything into one clean headline number. The latest edition suggested near parity, roughly a ~2.7% gap based on Arena Elo as of March 2026.
However, I disagree with how that number gets interpreted.
Not because the math is wrong, but because the abstraction is doing too much heavy lifting. Arena Elo is a Bradley–Terry system, so it measures pairwise win probability inside a tightly packed leaderboard. At the frontier, everything is basically a 50/50 knife fight. That means small Elo differences get compressed, even when the real-world implications are not small at all.
The bigger issue is that it averages across tasks that are no longer equally important.
If you break it down into what actually matters in production today:
• General reasoning and chat: still basically parity (~51–52% vs 48–49%)
• Coding agents and tool use: US clearly ahead (~55–58%)
• Long-horizon autonomy and workflow execution: wider gap (~58–63%)
And this is the part the index smooths over, even though it is exactly where value is shifting: real software engineering, multi-step agents, and systems that actually finish tasks instead of just talking about finishing them.
A better approach would be to weight task families properly, then convert Elo into win probabilities per category before aggregating. That gives you a distribution view instead of a single overly-clean leaderboard average.
If you do that, the picture looks more like:
* March 2026 (when the report was published): ~6–7% effective frontier gap
* Today (post GPT-5.5, Opus 4.7 and DeepSeek V4 cycle): ~8–9% gap
So the gap is still significant, and it’s widening (contrary to the report’s headline conclusion), especially in agentic coding and long-horizon execution.
And honestly, publishing this once a year feels a bit like doing quarterly earnings for a company that reports revenue in real time on a public dashboard. By the time the PDF is out, the market has already moved on three product cycles 🫨
@ArtificialAnlys just dropped a new benchmark cut comparing frontier closed models vs best open weights, effectively US vs China, and it reinforces the point from my last post:
The aggregate “intelligence index” compresses the gap, but it breaks on the tasks that actually matter.
On hardest reasoning and agentic execution, the distance is still very real:
* Humanity’s Last Exam: open weights ~34–36% vs ~44–45% for frontier proprietary
* Research-level physics (CritPt): ~4–12% vs ~27%
* Agentic coding (TerminalBench Hard): ~43–46% vs ~54–61%
And on omniscience (knowledge + hallucination), the gap widens even more. Top open models are still materially behind in reliability, with significantly higher hallucination rates, while frontier proprietary models push much higher positive scores.
Bottom line: parity is a headline artifact. When you stress the systems on reasoning depth, tool use, and truthfulness, the frontier is still clearly ahead.
The @Stanford AI Index (by @StanfordHAI) is an annual report that tracks AI progress across papers, benchmarks, investment, talent, and model performance. It has become the default reference for US vs China frontier comparisons, mainly because it compresses everything into one clean headline number. The latest edition suggested near parity, roughly a ~2.7% gap based on Arena Elo as of March 2026.
However, I disagree with how that number gets interpreted.
Not because the math is wrong, but because the abstraction is doing too much heavy lifting. Arena Elo is a Bradley–Terry system, so it measures pairwise win probability inside a tightly packed leaderboard. At the frontier, everything is basically a 50/50 knife fight. That means small Elo differences get compressed, even when the real-world implications are not small at all.
The bigger issue is that it averages across tasks that are no longer equally important.
If you break it down into what actually matters in production today:
• General reasoning and chat: still basically parity (~51–52% vs 48–49%)
• Coding agents and tool use: US clearly ahead (~55–58%)
• Long-horizon autonomy and workflow execution: wider gap (~58–63%)
And this is the part the index smooths over, even though it is exactly where value is shifting: real software engineering, multi-step agents, and systems that actually finish tasks instead of just talking about finishing them.
A better approach would be to weight task families properly, then convert Elo into win probabilities per category before aggregating. That gives you a distribution view instead of a single overly-clean leaderboard average.
If you do that, the picture looks more like:
* March 2026 (when the report was published): ~6–7% effective frontier gap
* Today (post GPT-5.5, Opus 4.7 and DeepSeek V4 cycle): ~8–9% gap
So the gap is still significant, and it’s widening (contrary to the report’s headline conclusion), especially in agentic coding and long-horizon execution.
And honestly, publishing this once a year feels a bit like doing quarterly earnings for a company that reports revenue in real time on a public dashboard. By the time the PDF is out, the market has already moved on three product cycles 🫨
A useful way to frame the current wave of LLM progress is a simple split: are we scaling knowledge, or scaling understanding?
The IKP (Incompressible Knowledge Probes) work gives a concrete lens on the first. Its intuition is simple, rare, long-tail facts can’t be derived. A model either has them stored or it doesn’t. So instead of testing reasoning, IKP measures recall across ~1,400 questions of increasing obscurity, penalizes hallucinations, and calibrates results against 89 open models with known sizes.
The numbers make the point clear. Estimates place the GPT-5.5 family from @OpenAI around ~9–10T parameters, Claude Opus 4 from @AnthropicAI around ~3.6–5.3T, and most frontier systems from @GoogleDeepMind in the ~0.7–4T range. Factual recall scales cleanly with size, with no real compression.
That’s the memorization axis.
But LLMs are not just lookup tables. They build abstractions through embeddings. Tokens are mapped into high-dimensional vectors, and training pulls together words that behave similarly across contexts. In transformers, these become contextual embeddings shaped by attention, layer after layer, forming a structured space where similarity, analogy, and partial relationships emerge.
This is a real form of abstraction, but it has limits. It’s statistical, not causal. It reflects how language behaves, not how the world evolves.
That gap is exactly what @ylecun has been pushing on with world models.
In parallel, Elon Musk and xAI are doubling down on the opposite bet: scale. The Grok roadmap moves from ~1–1.5T models (Grok 4.x) toward Grok 5 in the ~6T range, with targets discussed up to ~10T parameters, trained on massive clusters like Colossus with hundreds of thousands to potentially millions of GPUs.
So the divergence becomes concrete. One path increases how much the model can store and organize. The other tries to change what is being learned in the first place.
IKP by Bojie Li , @PineAiCallAgent