Can we post-train a machine with virtue? Both RLHF (consequentialist) and Constitutional (deontological) are limited. I think there's a third path: virtue training.
I received a @cosmos_inst grant to investigate with @andrew_roci, starting with sycophancy, the vice Aristotle attributes to the kolax.
Benchmark + adapters open-source. Lab notes linked below.
an article I wrote on how consuming ai generated content changes our perception of reality, making outliers imperceptible, and accelerating our culture towards the mediocre. enjoy ❤️
More information on our views on open-source, negative values, AI policy, and the role of the non-aggression principle (NAP) in the daios method.
Link below.
One thing that even relatively senior ML people often fail to grasp is that deep learning models are curves fitted to a data distribution. You cannot expect them to solve tasks outside of their training distribution (which is the sort of thing that you need intelligence for).
"Emergent learning" is an incorrect label -- if a model demonstrates performance on task A that it wasn't trained on, that simply means that there is significant overlap between A and all the data that you did train on. Competence doesn't magically emerge out of nowhere.
what if I told you that "the crowd is untruth"?
source: how anthropic created the HH (helpfulness and harmlessness) dataset, the cutting-edge of datasets used to align models with human values
model = learn(data)
Synthetic data is great, but it’s not data. It’s an intermediate quantity created by learn(). Data is created by people and has privacy and copyright considerations. Synthetic “data” does not - it’s internal to learn().
the approach towards definitions in computer science vs philosophy is interesting:
AI ethics academics used to complain that since we can't agree on the definition of ethics, we cannot progress further
the silence around this topic has been definitive since chatGPT was released
This is a profound insight.
I never considered it. It turns out, people have different values. And so aligning AI must be impossible because there are no universal values.
How has nobody ever made this point before?
Oddly enough, this exercise suggests a way to solve the otherwise possibly intractable problem of what an AI's politics should be. Let the user choose what they want the reference group to be, and they can pick Oberlin undergrads or Freedom Caucus or whatever.
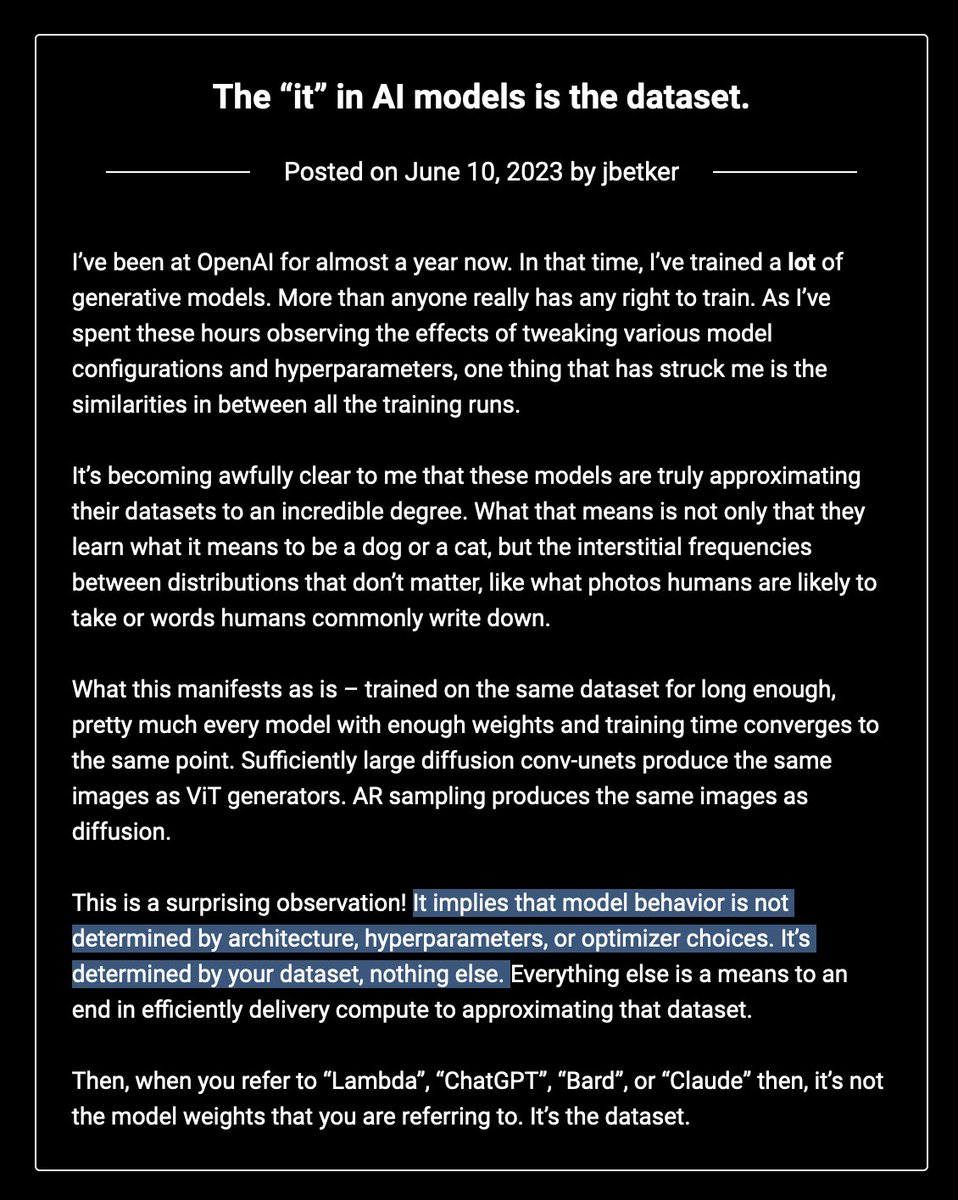
interesting post from an OpenAI employee claiming that all large language models reach the same endpoint regardless of training strategy or clever tricks
this is of course what the bitter lesson teaches us but useful to get an up to date confirmation that it still holds true
fine-tuning can override original safety mechanisms built into LLMs
original safety mechanisms prevent harmful behavior but often cauterize the model
what's better?
papers below
Undoing RLHF and the brittleness of safe LLMs
Recent papers show most of the arguments about needing "safety" in releases of open LLM weights are nearly dead in the water. Yes, still release the parameters.
Read here: https://t.co/D8sFq6X9qG