@adamlewisgreen So, of course, when downsampling is done properly, you will see same performance with 1M cells or 100M.
If people would do experimental design properly, large-scale scRNA data would be *very* useful. But most of the data is trash.
@adamlewisgreen 200 (not broad, not coarse) cell types
x 100 perturbations/diseases/…
x 10 cells (~1 metacell)
x 10 dev. stages
= 2M cells
We should do deeper, multi-modal sequencing of fewer cells/experiment. We don’t because 10XG decided that more cells per experiment is most profitable.
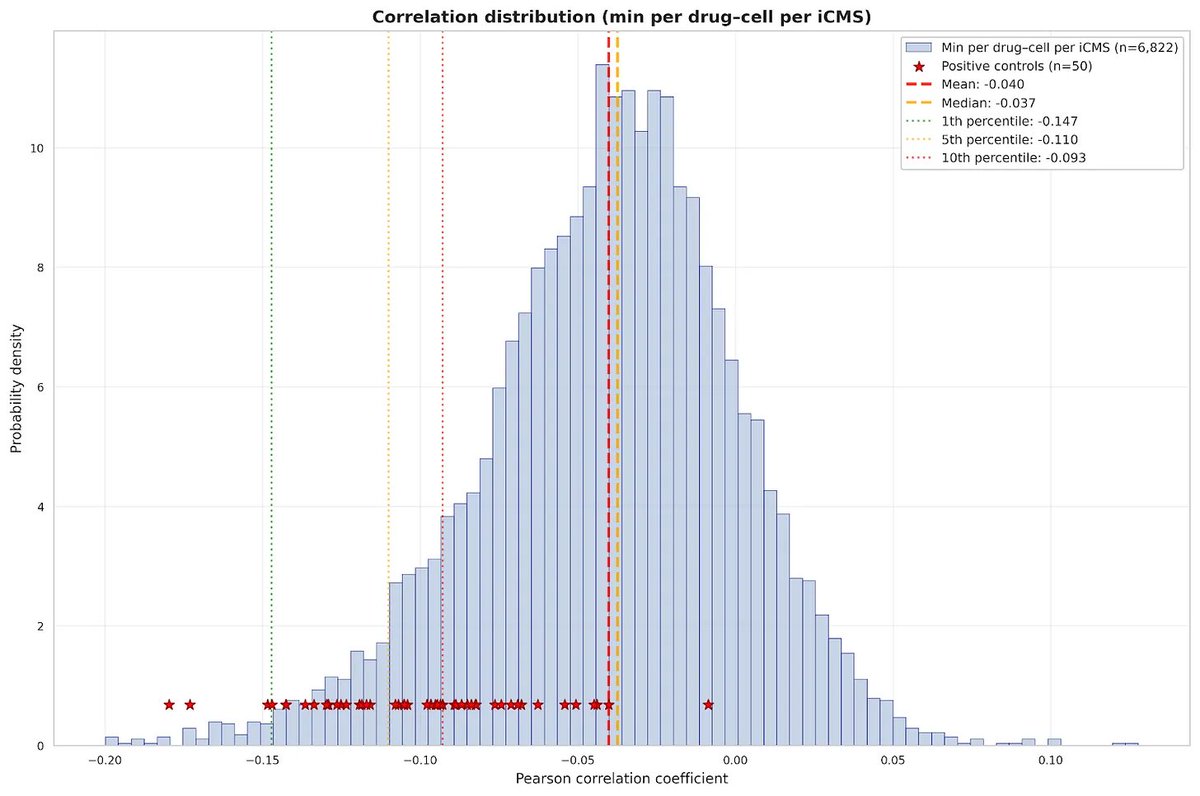
How much value will virtual cell models add compared to querying the training data with DeSeq2 and Pearson correlations? Have people seen virtual cell demos with better enrichment of positive controls than Fig. 1?
@rryssf No, it’s not. The scRNA-seq example is trivial; if you need 200 agents running for >8 hours for that, you’re probably not a good bioinformatician.
Also, don’t claim to be an “autonomous” AI tool when 90% of your notebooks depend on tools created and maintained by humans.
Microsoft researchers introduce MatterGen, a model that can discover new materials tailored to specific needs—like efficient solar cells or CO2 recycling—advancing progress beyond trial-and-error experiments. https://t.co/z9yOaV7VGo
Today, Illumina and @NVIDIA join forces to expand the availability of AI tools for multiomic analysis. This partnership paves the way for the next frontier of biological discovery, in which data and AI will play a crucial role. https://t.co/gQE4h9D3wO
#JPM25
🧬 Want to implement Open-ST in your lab?
We've published a detailed guide that takes you from tissue sections to 3D molecular maps
https://t.co/IrpTFnnoe9
when i joined #twitter in 2013, i wrote in my profile “.. trying to find out if twitter can improve life”. 12 years later i am appalled by what it has become- murderous insults & hate everywhere, & given all the lies & fakes a disinformation machine of grotesque size & power.
And rg my statement about “Foundation Models”: many studies claim that it is possible to predict neighborhood (whatever that means) from (spatial) single-cells. This is not new, and FMs are overkill.
Doing this from ST is problematic. There should be other goals for these data.
We warned about this (Schott et al. 2024), but it’s good to see more people noticing it:
“Segmentation errors […] generate artifactual signal in predicting association between cell state and adjacent presence of another cell type.”
Be careful with “Foundation Models”
Also because this ignores:
- RNA outside of cells
- Localization
- All techs have sources of noise that we don’t quite understand nor explicitly model (even sequencing-based ones)
- No one can explain what a neighborhood is
I have read few papers as immediately useful and important as this one on Cacio e Pepe phase behavior.
Tl;dr: the starchy pasta water is absolutely critical to avoiding “mozzarella phase”
I have read few papers as immediately useful and important as this one on Cacio e Pepe phase behavior.
Tl;dr: the starchy pasta water is absolutely critical to avoiding “mozzarella phase”