Check out our latest work on self-improving VLA & real-world RL “SELF-IMPROVING VISION-LANGUAGE-ACTION MODELS WITH DATA GENERATION VIA RESIDUAL RL”. Thrilled to have worked with an amazing team led by @_wenlixiao 🙌
🌐Project website: https://t.co/7LMFFC4PtW
What if robots could improve themselves by learning from their own failures in the real-world?
Introducing 𝗣𝗟𝗗 (𝗣𝗿𝗼𝗯𝗲, 𝗟𝗲𝗮𝗿𝗻, 𝗗𝗶𝘀𝘁𝗶𝗹𝗹) — a recipe that enables Vision-Language-Action (VLA) models to self-improve for high-precision manipulation tasks.
PLD couples real-world residual reinforcement learning with standard supervised fine-tuning — letting robots discover, recover, and distill their own data flywheel.
Quick 🧵
Real-time Chunking (RTC) is designed to enable smooth asynchronous execution of flow-matching policies. However, it has some critical limitations: its inpainting-based async execution capability comes from inference-time corrections rather than the base policy, yielding little pre-training benefit, specific fine-tuning for better performance (e.g. training-time RTC), heuristic guidance, and extra computation that inflates the latency.
In this work, we observe that discrete diffusion policies, which generate actions by iteratively unmasking, are natural asynchronous executors that resolve all limitations at once, being simpler to implement, faster at inference, and better at execution.
Paper: https://t.co/SbpNCQMBF1
Code: https://t.co/fQyT6NR2eE
Website: https://t.co/jLiCogvxoa
We release Wuji MJLab, an open-source MuJoCo environment for dexterous hand manipulation.
It includes a cube reorientation task, a sim2real pipeline, and the setup needed to reproduce the system.
We will be at ICRA booth 121 with a live demo and welcome discussions on dexterous manipulation.
Code: https://t.co/EpJMcozjnV
Contributors: Jielin Wu, @yaoshzh, @BergerHunger, Li Chengmeng.
This project is based on @kevin_zakka’s mjlab project.
Robotics: coding agents’ next frontier.
So how good are they?
We introduce CaP-X: an open-source framework and benchmark for coding agents, where they write code for robot perception and control, execute it on sim and real robots, observe the outcomes, and iteratively improve code reliability.
From @NVIDIA@Berkeley_AI@CMU_Robotics@StanfordAILab
https://t.co/MVcc6XWQhY
🧵
We developed an RL method for fine-tuning our models for precise tasks in just a few hours or even minutes. Instead of training the whole model, we add an “RL token” output to π-0.6, our latest model, which is used by a tiny actor and critic to learn quickly with RL.
Check out our work on domain-adaptive diffusion policy led by @Outsider_pc. A simple self-supervised approach learns multi-scale dynamics representations that enable context-efficient online adaptation.
Imagine a single policy adapting aggressively across multiple embodiments and different domains—varying friction, mass, limb lengths. Can this be done online and zero-shot, without privileged environment parameters or retraining for each new domain?
We take a step toward this goal with DADP, a diffusion-based policy for domain adaptation. DADP learns domain representations in a self-supervised manner from interaction context and integrates them into the diffusion generation process by biasing the prior distribution and re-formulating the diffusion target.
Paper: https://t.co/cSsPA1Jmfc
Website: DADP: https://t.co/T5AmbLRUGp
Code (w/ Dataset & Checkpoints): https://t.co/RgssL0QJrR
More details below.
Announcing DreamDojo: our open-source, interactive world model that takes robot motor controls and generates the future in pixels. No engine, no meshes, no hand-authored dynamics. It's Simulation 2.0. Time for robotics to take the bitter lesson pill.
Real-world robot learning is bottlenecked by time, wear, safety, and resets. If we want Physical AI to move at pretraining speed, we need a simulator that adapts to pretraining scale with as little human engineering as possible.
Our key insights: (1) human egocentric videos are a scalable source of first-person physics; (2) latent actions make them "robot-readable" across different hardware; (3) real-time inference unlocks live teleop, policy eval, and test-time planning *inside* a dream.
We pre-train on 44K hours of human videos: cheap, abundant, and collected with zero robot-in-the-loop. Humans have already explored the combinatorics: we grasp, pour, fold, assemble, fail, retry—across cluttered scenes, shifting viewpoints, changing light, and hour-long task chains—at a scale no robot fleet could match. The missing piece: these videos have no action labels. So we introduce latent actions: a unified representation inferred directly from videos that captures "what changed between world states" without knowing the underlying hardware. This lets us train on any first-person video as if it came with motor commands attached.
As a result, DreamDojo generalizes zero-shot to objects and environments never seen in any robot training set, because humans saw them first.
Next, we post-train onto each robot to fit its specific hardware. Think of it as separating "how the world looks and behaves" from "how this particular robot actuates." The base model follows the general physical rules, then "snaps onto" the robot's unique mechanics. It's kind of like loading a new character and scene assets into Unreal Engine, but done through gradient descent and generalizes far beyond the post-training dataset.
A world simulator is only useful if it runs fast enough to close the loop. We train a real-time version of DreamDojo that runs at 10 FPS, stable for over a minute of continuous rollout. This unlocks exciting possibilities:
- Live teleoperation *inside* a dream. Connect a VR controller, stream actions into DreamDojo, and teleop a virtual robot in real time. We demo this on Unitree G1 with a PICO headset and one RTX 5090.
- Policy evaluation. You can benchmark a policy checkpoint in DreamDojo instead of the real world. The simulated success rates strongly correlate with real-world results - accurate enough to rank checkpoints without burning a single motor.
- Model-based planning. Sample multiple action proposals → simulate them all in parallel → pick the best future. Gains +17% real-world success out of the box on a fruit packing task.
We open-source everything!! Weights, code, post-training dataset, eval set, and whitepaper with tons of details to reproduce. DreamDojo is based on NVIDIA Cosmos, which is open-weight too.
2026 is the year of World Models for physical AI. We want you to build with us. Happy scaling!
Links in thread:
Introducing DreamZero 🤖🌎 from @nvidia
> A 14B “World Action Model” that achieves zero-shot generalization to unseen tasks & few-shot adaptation to new robots
> The key? Jointly predicting video & actions in the same diffusion forward pass
Project Page: https://t.co/qhygDzu6NY
🧵 (1/10)
Robust humanoid perceptive locomotion is still underexplored. Especially when different cameras see different terrains, paths get narrow, and payloads disturb balance...
Introduce RPL, tackling this with one unified policy:
• Challenging terrains (slopes, stairs and stepping stones);
• Multiple directions;
• Payloads;
Trained in sim. Validated long-horizon in the real world.
Watch the robot walk it all🦿
Details below👇
mjlab v1.0.0 is officially out and considered stable.
Huge thanks to everyone who contributed code, reported issues, and gave feedback. This release wouldn’t have happened without you.
https://t.co/ZJgbwVwuPC
We release Cosmos Policy 💫: a state-of-the-art robot policy built on a video diffusion model backbone.
- policy + world model + value function — in 1 model
- no architectural changes to the base video model
- SOTA in LIBERO (98.5%), RoboCasa (67.1%), & ALOHA tasks (93.6%)
🧵👇
Looking for a clean start for your VLA research? Check out vla-scratch led by @ElijahGalahad — a modular, high-performance framework with VQA co-training support. Excited to have made a tiny contribution, and there’s much more to come as the project rapidly evolves!🔥
Introducing vla-scratch: a modular, performant and efficient stack for VLAs. https://t.co/OJQTui7ls9
I started it because existing codebases were either slow, or hard to extend for co-training with clean data abstractions. This repo is a ground-up attempt to address both.
Here’s the windmill assembly demo we showed at CES 2026 — the one no one saw coming.
North executes a fully autonomous, long-horizon dexterous sequence with sustained hand–eye–tactile coordination and assembly-level precision enabled by tactile feedback.
It’s also robust to disturbance: you can reposition the objects, and North will still identify them and recover the task.
This is powered by CraftNet (VTLA) — using tactile feedback to continuously fine-tune the last-millimeter interaction, enabling reliable execution across 30+ steps.
Read more about CraftNet: https://t.co/RS0hCu1bh9
#Sharpa #SharpaWave #SharpaNorth #CraftNet #System0 #CES2026
One core bottleneck in VLA models is action representation.
Discrete tokens scale beautifully with VLM pretraining—but lose precision.
Continuous actions are precise—but often break VLM reasoning.
In our new work, we resolve this tension at the representation level. 🧵
A proof-of-concept demonstrating that VQA co-training enables task-centric grounding in visual features. Action prediction alone may never be the ultimate solution, even when scaled to sufficient amounts of robotic data. I'm really looking forward to the release.
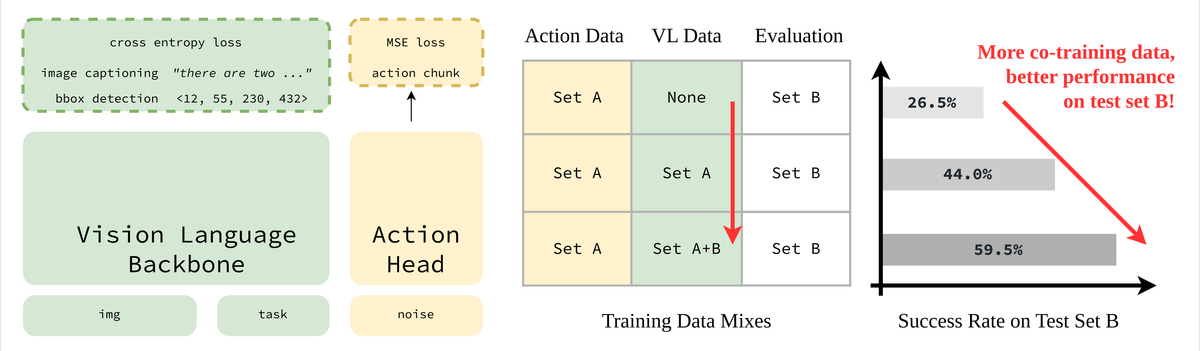
VL data co‑training is widely adopted in SoTA VLAs, but its impact is rarely isolated.
Our controlled experiment reveals that auxiliary VL supervision generalizes policies to tasks seen only in VL data, even when the action head is only trained on a smaller robotic dataset.
We discovered an emergent property of VLAs like π0/π0.5/π0.6: as we scale up pre-training, the model learns to align human videos and robot data!
This gives us a simple way to leverage human videos. Once π0.5 knows how to control robots, it can naturally learn from human video.
What's remarkable to me is how well the representations align as we increase the amount of robot data. To be clear: in this video we are only increasing the amount and diversity of *robot* data, and we see human/robot images mapping to the same place in representation space.
1/ While most RL methods use shallow MLPs (~2–5 layers), we show that scaling up to 1000-layers for contrastive RL (CRL) can significantly boost performance, ranging from doubling performance to 50x on a diverse suite of robotic tasks.
Webpage+Paper+Code: https://t.co/43xwfJEIjh
Generative models (diffusion/flow) are taking over robotics 🤖. But do we really need to model the full action distribution to control a robot?
We suspected the success of Generative Control Policies (GCPs) might be "Much Ado About Noising."
We rigorously tested the myths. 🧵👇