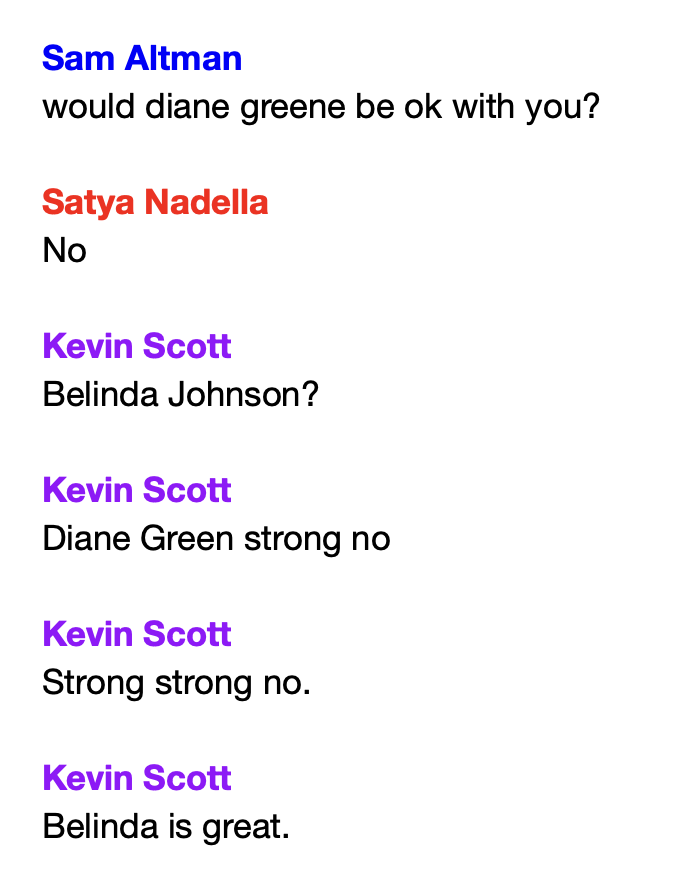
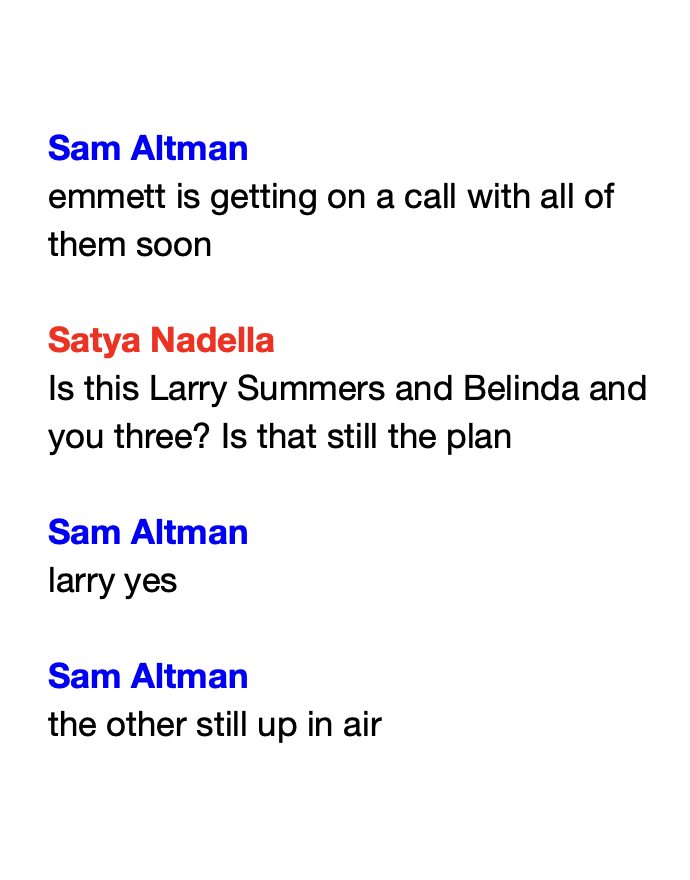
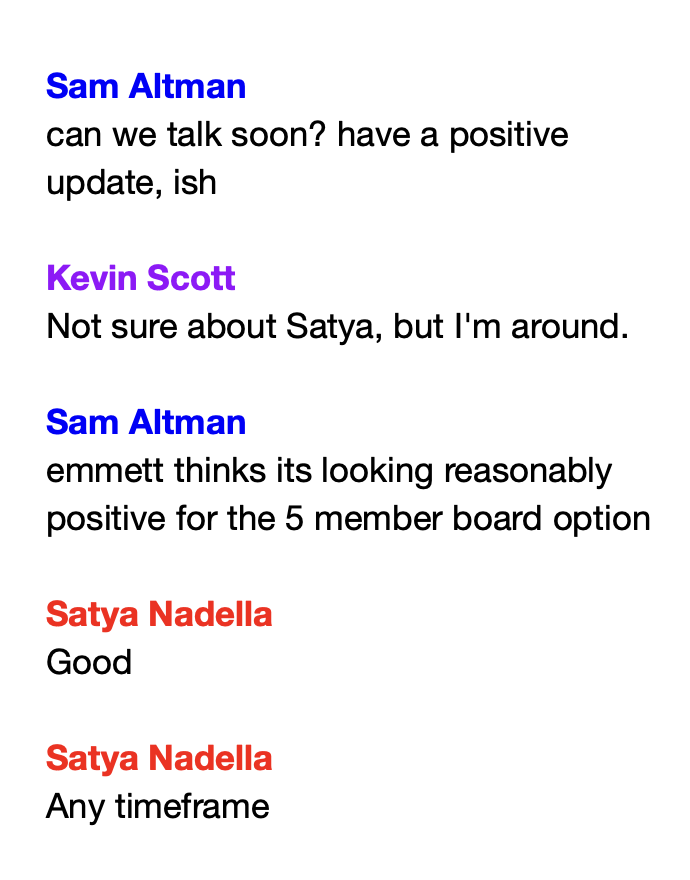
End of season update.
The question I started with: Can a self-improving system learn to model T20 madness, or is it just noise?
With a 23-match sample, it's mostly noise. Model predictions were close to a coin flip. Interestingly, even Polymarket predictions (with real money riding on it) were close to a coin flip as well.
That said, I find it cool that the model taught itself to land right at that same line with no human in the loop. 91% of results fell inside its prediction bands.
Whether that is learning or just finding the floor, I dont know because sample is not big enough. Maybe next season.
Fun research experiment I'm running through this IPL.
5 IPL matches in. Polymarket seems to overprice narratives (dew, form) and underprice boring venue-specific base rates (head-to-head at the ground, chase win rates, bowling matchups). Matches 4 and 5 especially.
Based on a multi-agent system that I built to predict match outcomes. Fully autonomous on a VPS, no human in the loop and self improving via Autoresearch (thanks @karpathy sensei).
n=5 so grain of salt. Repo is public 👇
I have loved Google all my life, but there’s a particular pathology I’ve been observing over the last 3 years and it’s starting to bug me.
Google keeps creating overlapping AI products with confusingly similar names.
Back in 2024, it was Gemini, Gemini Advanced, Gemini Pro/Ultra subscriptions, Gemini API, Google AI Studio, Vertex AI, etc.
Today it’s Gemini Spark, Google Antigravity, Vertex AI, Gemini API, Google AI Studio, the Gemini app, and more.
I would love to see a coherent product umbrella like OpenAI or Anthropic have built. Instead, I’m often left looking at product names that sound similar but serve very different use cases.
Talking to friends I haven't spoken to in years at 2 AM. All of us celebrating together, reliving the ghosts of two decades. Unreal this. Thank you, Arsenal 🏆
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
Update after 12 matches. Accuracy isn't any better than a coin flip.
Model handles team-level structure fine. Home advantage, bowling gaps, form. 92% of outcomes land inside the band.
But it's simply not equipped to deal with one player deciding the game - Finn Allen 93(35), Starc 4/40, Marsh 90(38).
Let's see if it can adapt and learn for the remaining matches.
Fun research experiment I'm running through this IPL.
5 IPL matches in. Polymarket seems to overprice narratives (dew, form) and underprice boring venue-specific base rates (head-to-head at the ground, chase win rates, bowling matchups). Matches 4 and 5 especially.
Based on a multi-agent system that I built to predict match outcomes. Fully autonomous on a VPS, no human in the loop and self improving via Autoresearch (thanks @karpathy sensei).
n=5 so grain of salt. Repo is public 👇
Starting June 15, paid Claude plans can claim a dedicated monthly credit for programmatic usage.
The credit covers usage of:
- Claude Agent SDK
- claude -p
- Claude Code GitHub Actions
- Third-party apps built on the Agent SDK