America is not automatic. Our tech & economic advantage only exists because of America’s unique DNA that from our founding combined talent, capital, risk tolerance, universities & smart immigration. In the Age of AI this unique American combo is more valuable than ever! 🇺🇸🚀🎯
spent my 11-hour flight back from europe working on a very long report. started as a slack message but morphed into a several pages long doc. wifi was as shitty as it gets. after finally making it home i realized that the computer had forcefully restarted. opened slack: draft was gone :(
hail mary: claude pls save me, no clue how but pls try
it checked APFS snapshots, time machine, slack indexeddb, write-ahead logs, service worker / http caches, local storage, app logs, hibernation image... nothing. all gone
but then... it realized i have alfred installed. so it checked the clipboard snapshots alfred keeps in sqlite. sad news: alfred clipboard memory gets deleted after 24h. aggressive retention policy. however! when sqlite runs DELETE, nothing gets actually deleted. it only marks pages as reusable, but it doesn't override the physical bytes. so claude decided to do a raw-scan of the db, reverse eng alfred data format, figure out the portion containing the timestamp, stitched everything back together across overflow pages... and handed me the exact final version of my report, the last one i cmd+C'd
all this, in a single shot
... day 200 of "what if you had an elite hacker you can ask anything to"
Oddly enough @realDonaldTrump, losing by 50% still feels better than supporting you.
“Doing the right thing will never be the wrong thing”
Thank you for your attention to this matter.
Databricks is proud to be a Founding Gold Sponsor of @TheOfficialACM Conference on AI and Agentic Systems—the first ACM conference dedicated to compound AI and agentic systems, with our co-founder @matei_zaharia on the organizing committee.
Join us May 26–29 in San Jose for the premier event for rigorous, reproducible research in compound AI architectures, optimization, and deployment.
Register today: https://t.co/Y0b2NhQjWv
Krishna Rao is the CFO of Anthropic, and this is his first podcast appearance.
He joined the company two years ago when run-rate revenue was about $250M. Today it is $30B. He has helped raise ~$75B and is responsible for the procurement and allocation of compute.
I feel lucky we get to hear what it is like to sit inside a company this consequential at a moment this pivotal.
We discuss:
- The cone of uncertainty
- How he allocates compute across Trainium, TPUs, and GPUs
- What investors misunderstand about model companies
- Why the returns to frontier intelligence keep rising
- Platform vs application and where Anthropic builds its own products
- How Anthropic uses Claude internally
I have asked my closing question about the kindest thing more than 500 times. Krishna's answer is one I have never heard before.
Enjoy!
Timestamps:
0:00 Intro
2:38 The Compute Canvas
6:51 The "Cone of Uncertainty"
11:58 Why the Returns to Frontier Intelligence Are So High
16:45 Recursive Self-Improvement
20:20 Scaling Laws
23:30 Sourcing $100 Billion in Compute
28:05 Platform vs. Application Strategy
32:52 Pricing Dynamics
38:48 How Anthropic’s Finance Team Uses Claude
43:24 Raising Capital & Overcoming Investor Skepticism
52:32 Public Perception, Risks, and Government Regulation
57:25 Mythos Release
1:12:33 What Could Derail the AI Revolution?
1:13:47 Biotech and Healthcare
1:15:31 The Kindest Thing
He gets a ballroom. An Arch. A new reflecting pool. 10 billion directly into his pocket from taxpayers. Billions from special interests seeking favors and pardons.
What has America gotten? Tariffs, a new war, higher gas prices, inflation.
Truly a golden age.
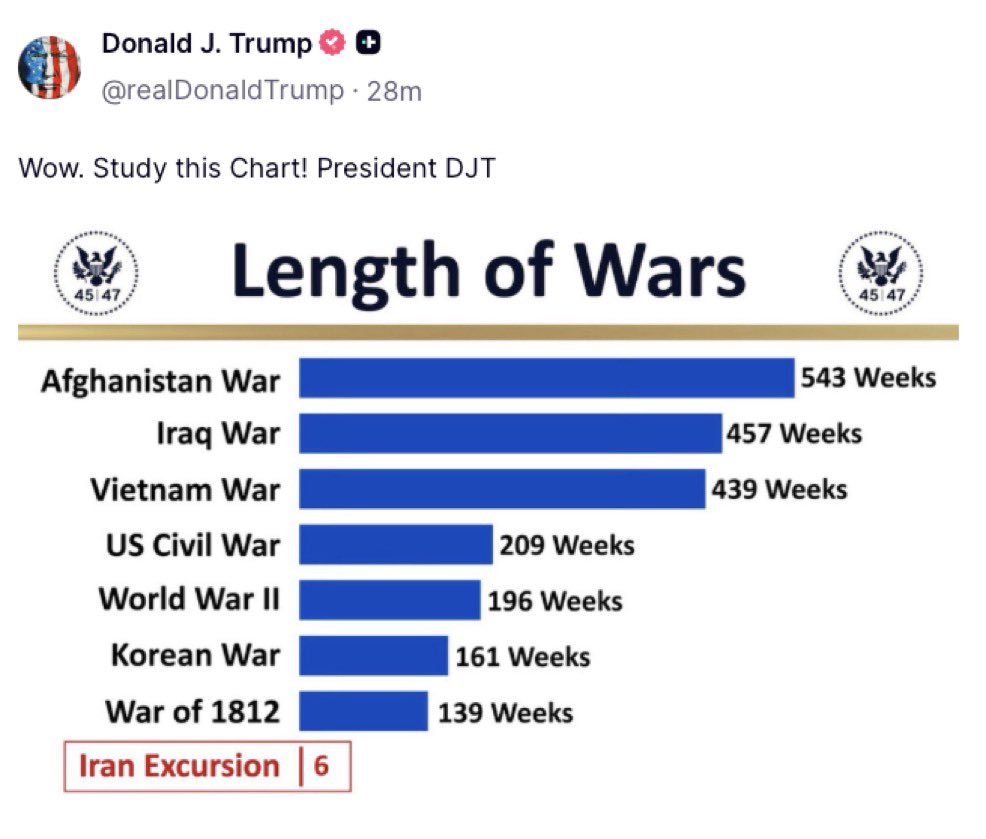
You know what would be amazing if Vance and his team can negotiate an agreement where Iran doesn't enrich above 3.67% (far below weapons grade); gets rid of 98% of its stockpile of enriched uranium; has weekly inspections by the IAEA; keeps the straits open without charging anyone; and commits to all of this for at least ten years. Oh, yeah, that was the Obama Iran deal.
Thrilled to be back on Stanford campus today kicking off MS&E 435: Economics of the AI Supercycle, a seminar unpacking the economics across every layer of the AI stack.
Incredibly grateful to an amazing group of speakers dedicating their time for the community:
@altcap (Altimeter) @alighodsi (Databricks) @rauchg (Vercel) @sundeep (Groq / NVIDIA) @ChaseLochmiller (Crusoe) @sk7037 (OpenAI) @tuhinone (Baseten) @ypatil125 (Applied Compute) Eric KA (Anthropic)
9 weeks. 9 speakers. 1 question: Where does value accrue in this new supercycle? Join us!
In honor of 50 years of Apple, we're sharing - for the first time ever - Don Valentine's original 1977 memo for Sequoia's investment into Apple Computer. #Apple50
My conversation with @martin_casado on LLMs. We cover Kolmogorov Complexity, Shannon Entropy, Relativity, Causal Inference, Don Knuth, Consciousness, and of course, Cricket..
https://t.co/kdsPmWWd7e
Introducing TigerFS - a filesystem backed by PostgreSQL, and a filesystem interface to PostgreSQL.
Idea is simple: Agents don't need fancy APIs or SDKs, they love the file system. ls, cat, find, grep. Pipelined UNIX tools. So let’s make files transactional and concurrent by backing them with a real database.
There are two ways to use it:
File-first: Write markdown, organize into directories. Writes are atomic, everything is auto-versioned. Any tool that works with files -- Claude Code, Cursor, grep, emacs -- just works. Multi-agent task coordination is just mv'ing files between todo/doing/done directories.
Data-first: Mount any Postgres database and explore it with Unix tools. For large databases, chain filters into paths that push down to SQL: .by/customer_id/123/.order/created_at/.last/10/.export/json. Bulk import/export, no SQL needed, and ships with Claude Code skills.
Every file is a real PostgreSQL row. Multiple agents and humans read and write concurrently with full ACID guarantees. The filesystem /is/ the API.
Mounts via FUSE on Linux and NFS on macOS, no extra dependencies. Point it at an existing Postgres database, or spin up a free one on Tiger Cloud or Ghost.
I built this mostly for agent workflows, but curious what else people would use it for. It's early but the core is solid. Feedback welcome.
https://t.co/IPhieopOSP
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
https://t.co/WAz8aIztKT
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.
AI will necessitate a change in tax structures, capital gains taxes, ordinary income taxes and more. AI will change the labor/capital share of income towrads capital so tax structures must rebalance that towards labor (voters) to accept it. Capitalism is by permission of democracy. Make capital gains and ordinary income equal and exclude peopel making less than $100k/yr from all federal taxes, making the changes tax neutral.