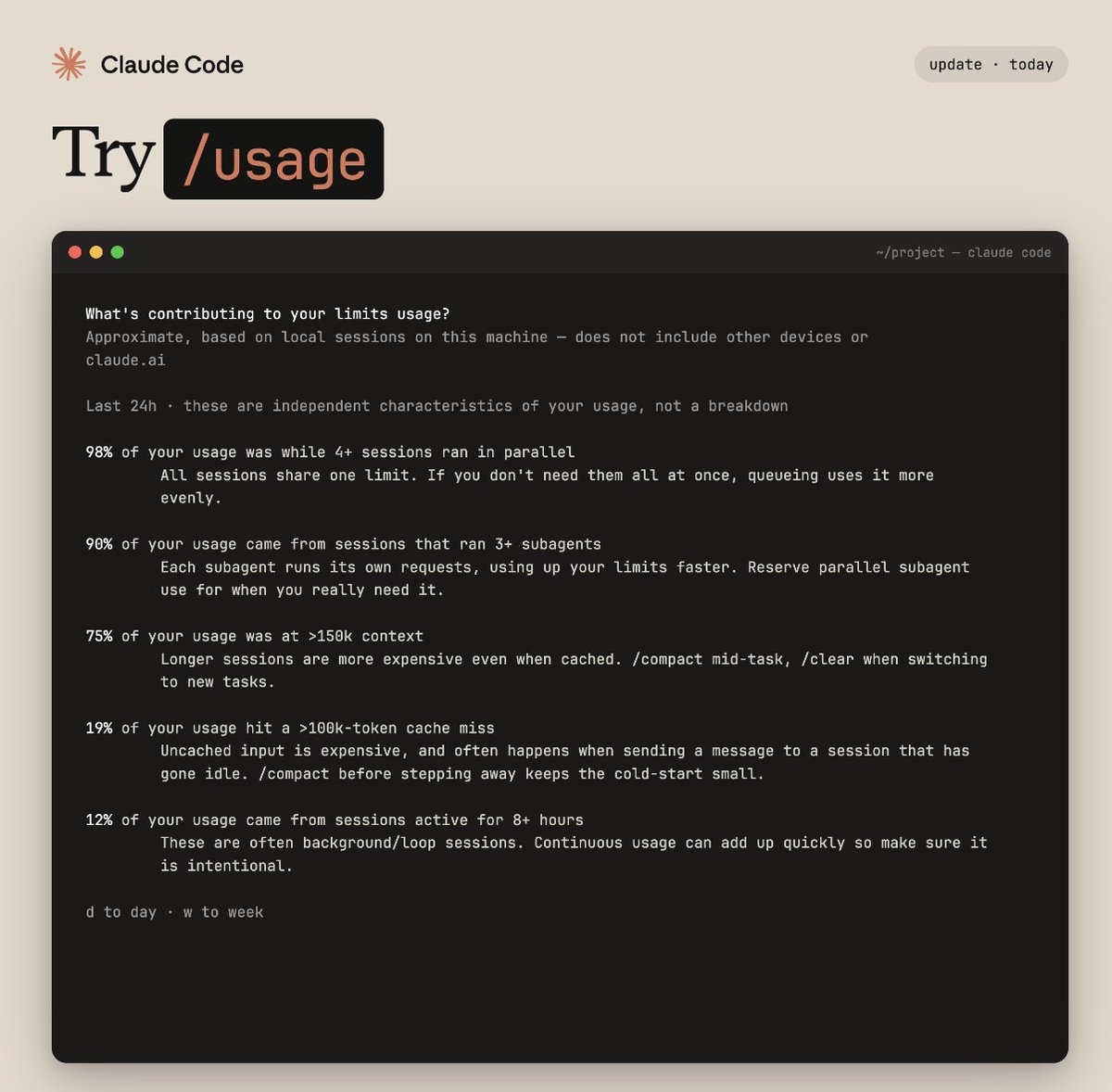
We’re adding more visibility into where your Claude Code usage goes.
Run /usage to see a breakdown of what's driving it: parallel sessions, subagents, cache misses, long context, plus tips to optimize each.
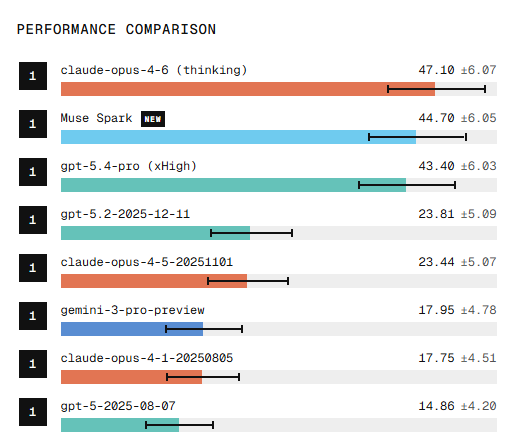
meta muse spark crushes one of my hard benchmarks "recommended me something good to read that I am certain to have never read before"
theres lots of theory of mind involved, most models recommend the same 20 or so pieces of work.
everything spark returned was novel, weird, and good. I had to heard of most of them and they were fun reads.
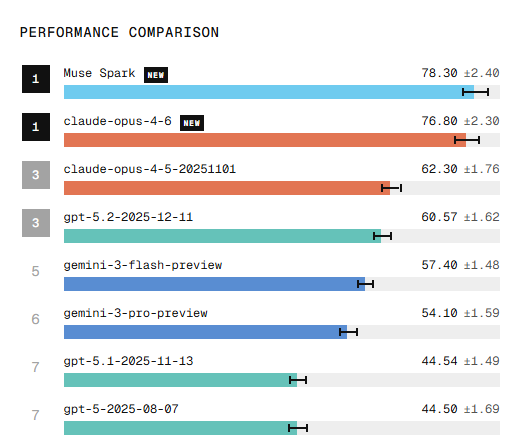
Our multimodal perception model MUSE Spark just entered the LMSYS Vision Arena in 2nd place — ahead of GPT and Gemini 🚀🚀🚀
Try it yourself in the updated Meta AI app! https://t.co/6t6Hn3xKhf
INSTEAD OF WATCHING NETFLIX TONIGHT.
Spend 3 hours with this.
Claude Code FULL COURSE that teaches you how to BUILD apps, teams, and anything.
The people who watch this tonight will wake up tomorrow with a new skill.
Watch it and Bookmark it now.
That clip is the part most people will underestimate.
Image-to-code was already impressive
What Meta’s Muse Spark seems to be doing is one level higher:
it’s not just recreating pixels, it’s inferring product logic.
I gave it a calendar screenshot and I am blown
Meta is back in the Arena!
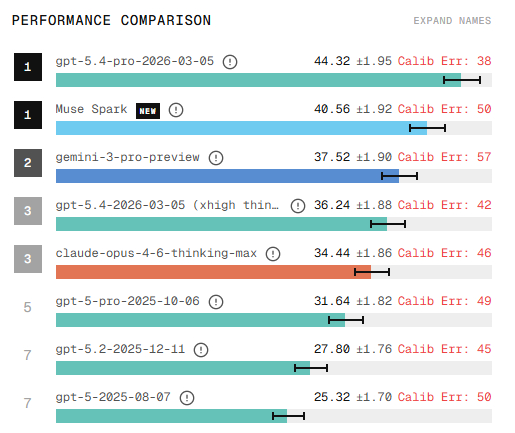
Muse Spark debuts as a top frontier model across both Text and Vision:
- Text Arena: #3 tied with Gemini-3.1-Pro and Claude-Opus-4.6
- Vision Arena: #2 tied with Claude-Opus-4.6
This marks Meta’s first major release since early 2025.
Highlights:
- #4 Hard Prompts, #6 Coding, #9 Creative Writing, #10 Instruction Following, #27 Expert
- #3 tied for Business, Management, & Financial Ops, #7 Legal & Government, #12 Writing & Literature
Meta is back at the frontier. Huge congrats to @AIatMeta on this incredible milestone!
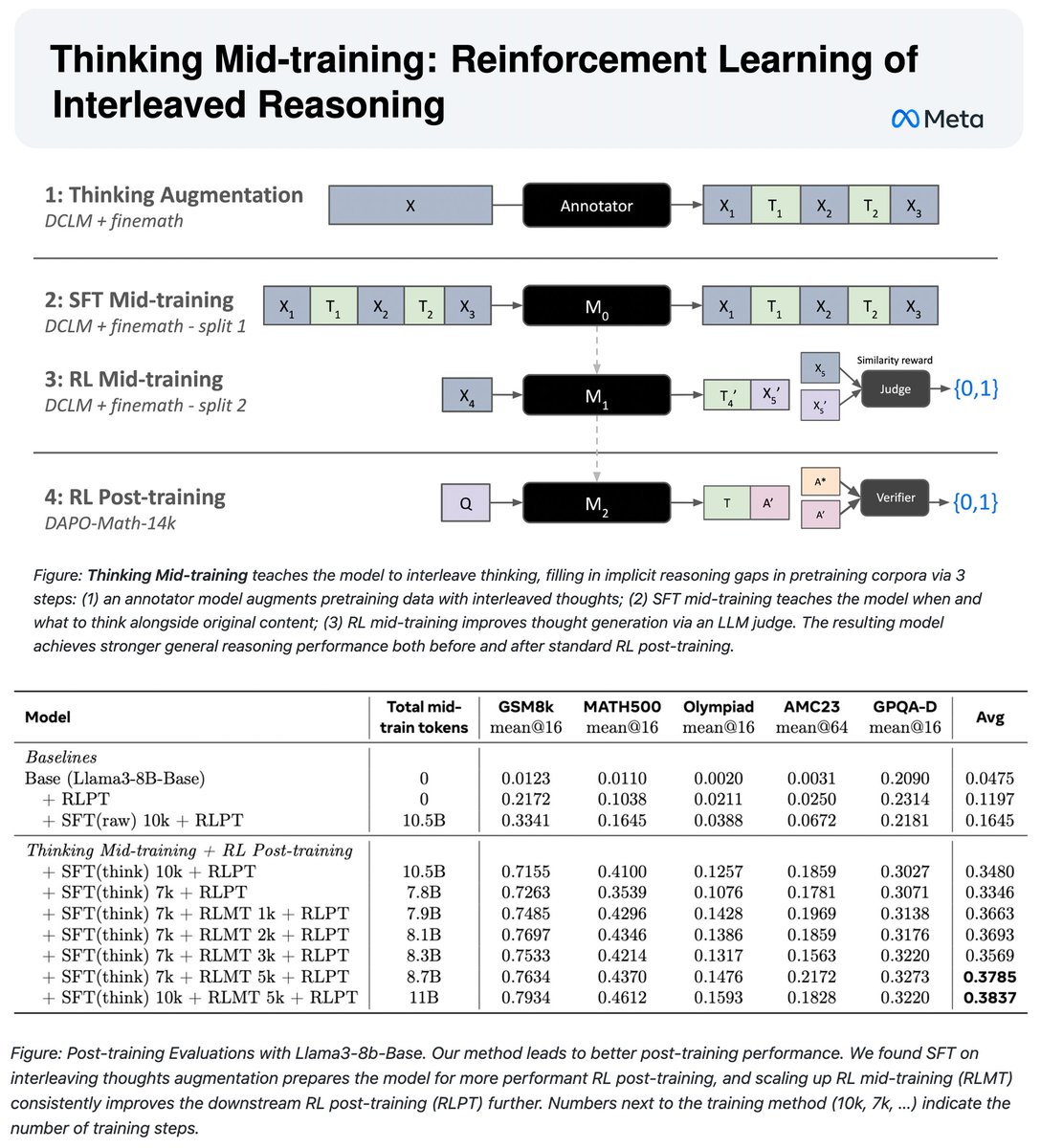
🏋️Thinking Mid-training: RL of Interleaved Reasoning🎗️
We address the gap between pretraining (no explicit reasoning) and post-training (reasoning-heavy) with an intermediate SFT+RL mid-training phase to teach models how to think.
- Annotate pretraining data with interleaved thoughts
- SFT mid-training to learn when/what to think alongside original content
- RL mid-training to optimize reasoning generation with grounded reward from future token prediction
Result: 3.2x improvement on reasoning benchmarks compared to direct RL post-training on base Llama-3-8B, and gains over only prior SFT as well.
Introducing reasoning earlier makes models better prepared for post-training!
Read more in the blog post: https://t.co/aGJcQKUjRw
Excited to share Muse Spark! It's a strong natively multimodal model with many surprising properties that emerged. Here, the model is able to use Python tools to make a playable Sudoku game on the web from an image input of the board. ✨
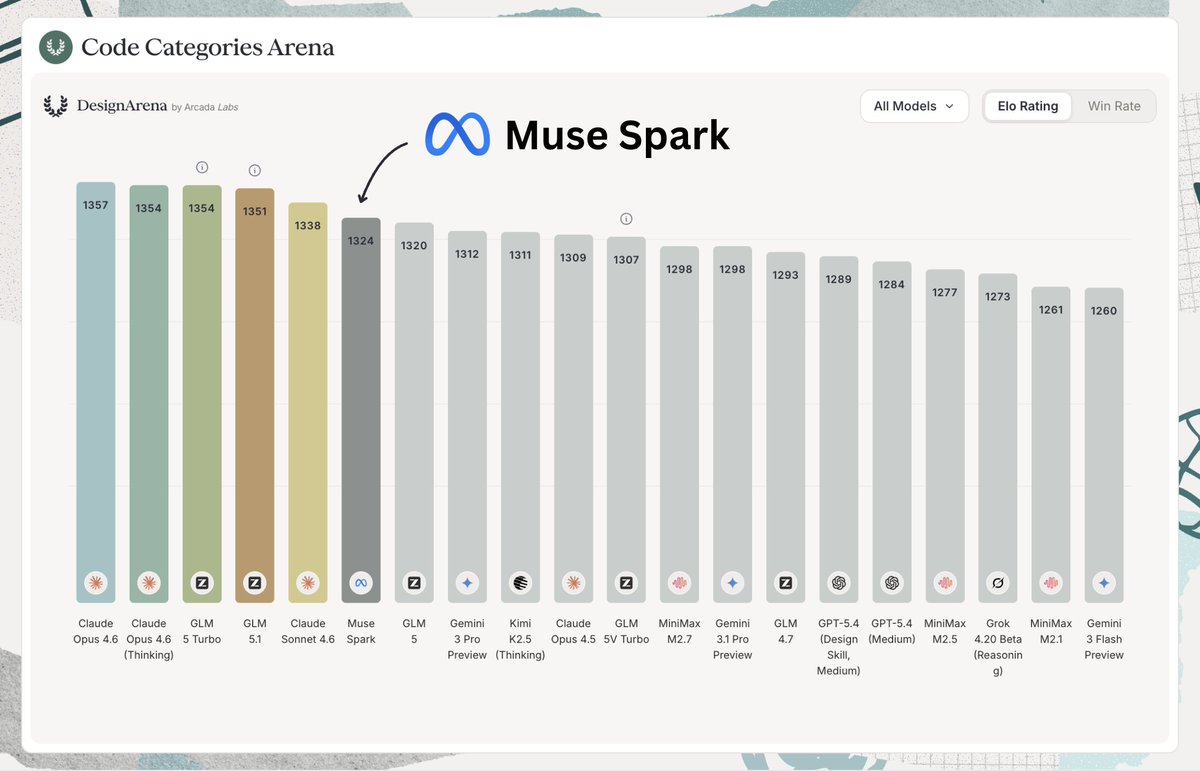
BREAKING: Muse Spark by @Meta is #6 overall on Design Arena with an Elo of 1324!
This is the single biggest improvement we've seen on Design Arena to date, with a jump of 103 positions and 374 Elo points
Huge congrats to the @Meta team on the launch!
Meta released Avocado, they call it Muse Spark.
It's not open source (a bit sad).
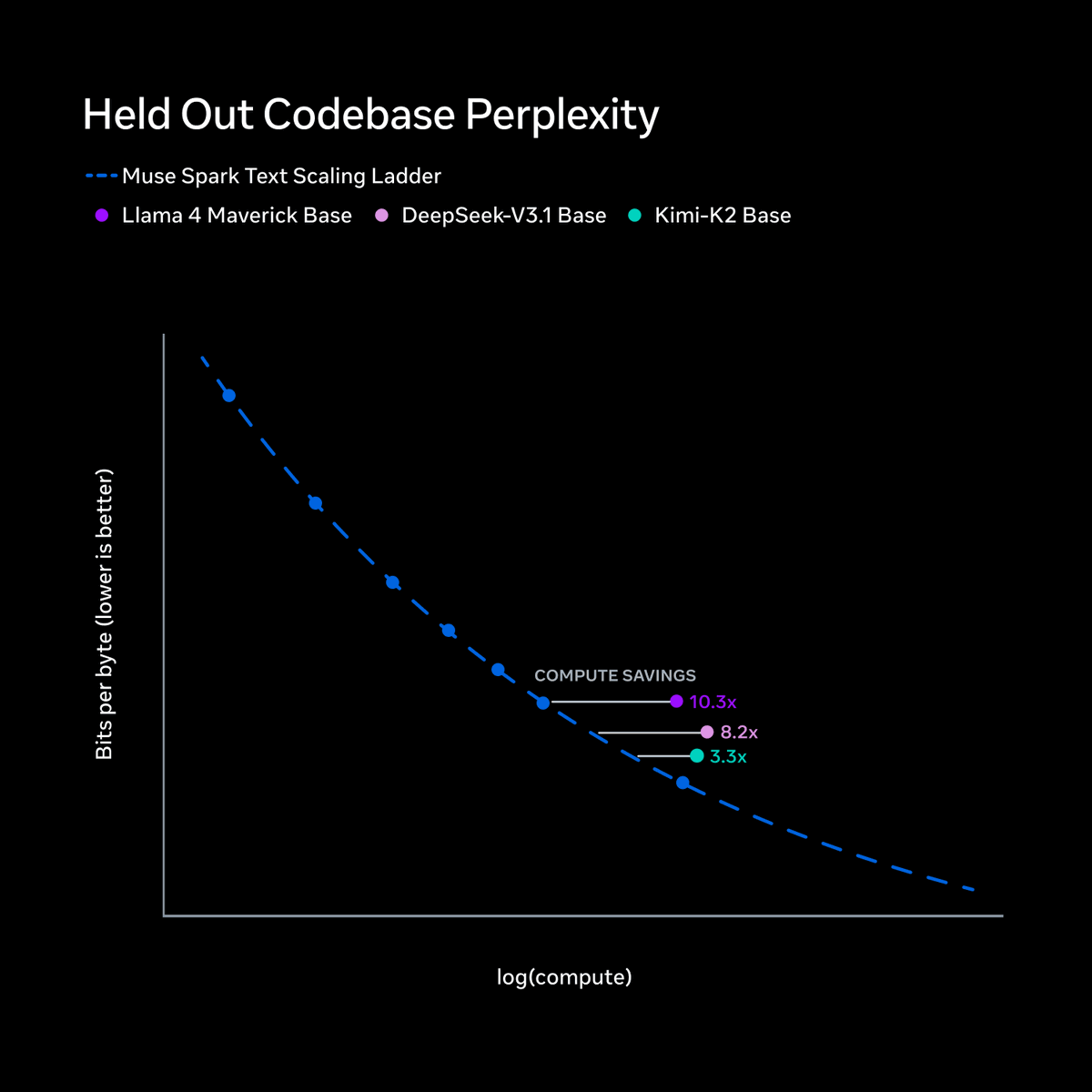
Meta TBD lab rebuilt the entire pretraining stack in 9 months and reached similar capability with >10x less compute than Llama 4 Maverick.
I still think infra is the real moat in AI labs. You can train models much faster with a good infra, and it allows researchers to experiment with many more ideas much more quickly.
VERDICT: Meta Muse Spark is the REAL DEAL
I ran several tests, including reading a menu. Newly released Meta Muse Spark was on the ONLY frontier AI to get all the items correct.
Sorry ChatGPT, there is no "Slapped Wagyu Dog" on the menu💀.
https://t.co/YmL52ADOwb
Muse Spark is built from the ground up to integrate visual information across domains and tools. It achieves strong performance on visual STEM questions, entity recognition, and localization, enabling interactive experiences like troubleshooting your home appliances with dynamic annotations.
To build personal superintelligence, our model’s capabilities should scale predictably and efficiently. Below, we share how we study and track Muse Spark’s scaling properties along three axes: pretraining, reinforcement learning, and test-time reasoning. 🧵👇
Let’s start with pretraining. Over the last 9 months, we rebuilt our pretraining stack with improvements to model architecture, optimization, and data curation, enabling us to increase the capability we can extract from every unit of compute. To rigorously evaluate our new recipe, we fit a scaling law to a series of small models and compare the training FLOPs required to hit a specific level of performance.
The results: we can reach the same capabilities with over an order of magnitude less compute than our previous model, Llama 4 Maverick, making Muse Spark significantly more efficient than the leading base models available for comparison.
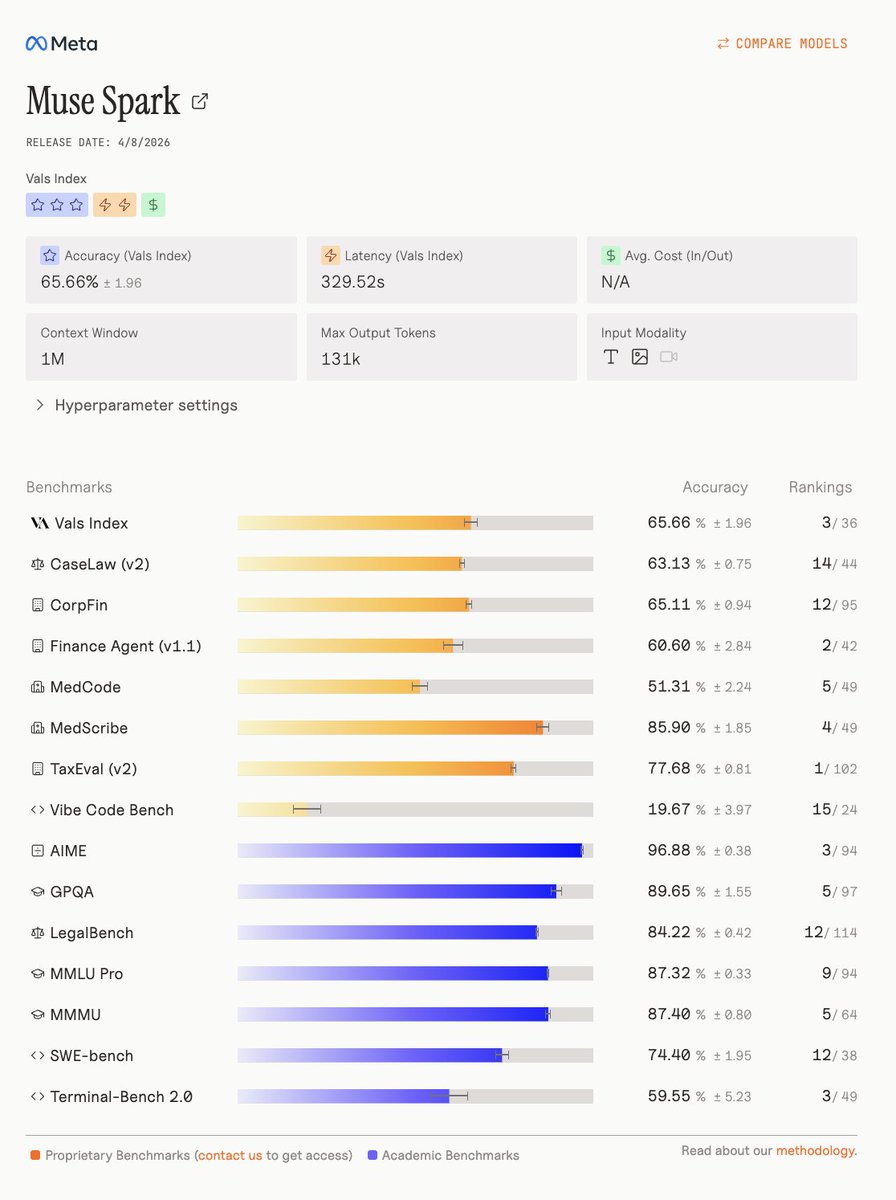
@fchollet Actually performs quite well on held out real world tasks! Especially for practical agentic use cases in finance. I'm also pretty doubtful that ARC AGI is a good predictor for "actual usefulness"
https://t.co/Ni6YTxKABN
We had pre-release access to Meta’s new Muse Spark model and evaluated it on FrontierMath. It scored 39% on Tiers 1-3 and 15% on Tier 4. This is competitive with several recent frontier models, though behind GPT-5.4.