Amazon is back with Nova 2.0, a substantial upgrade over prior Amazon Nova models and demonstrating particular strength in agentic capabilities
Amazon has released Nova 2.0 Pro (Preview), its new flagship model; Nova 2.0 Lite, focused on speed and lower cost; and Nova 2.0 Omni, a multimodal model handling text, image, video and speech inputs with text and image outputs.
Key benchmarking takeaways:
Amazon back amongst top AI players: This is Amazon’s latest release since Nova Premier and Amazon’s first release of reasoning models. Nova 2.0 Pro jumps 30 points in the Artificial Analysis Intelligence Index over Premier and Lite 38 points. This represents a huge increase in capabilities and Amazon’s return to being amongst the top AI players.
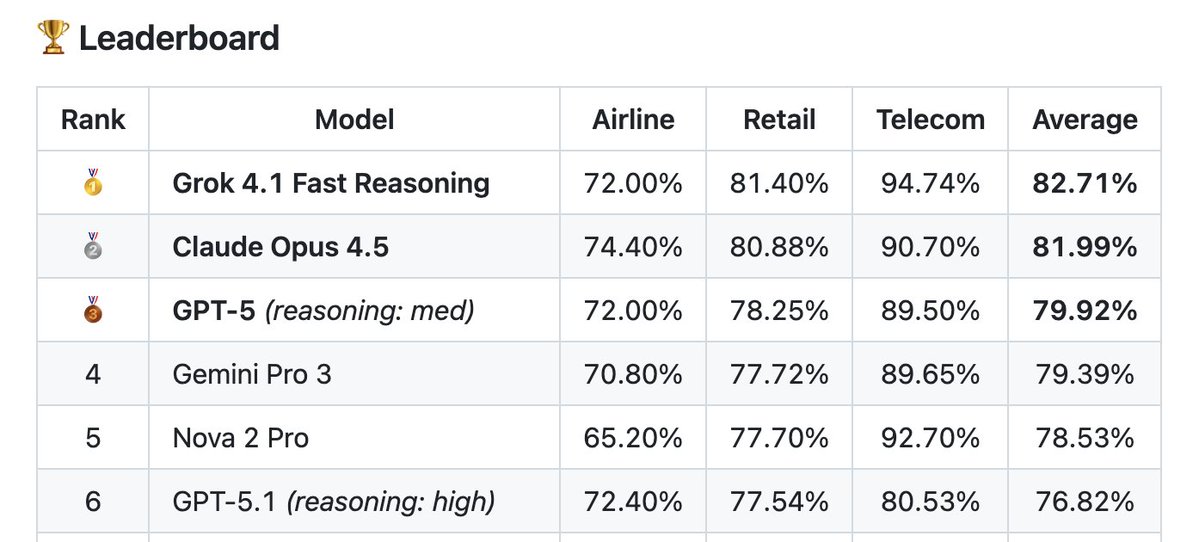
Strengths in agentic capabilities: Agentic capabilities including tool calling is a strength of the models, Nova 2.0 Pro scores 93% on τ²-Bench Telecom and 80% on IFBench on medium and high reasoning budgets respectively (complete benchmarks for high reasoning coming soon). This places Nova 2.0 Pro Preview amongst the leading models in these benchmarks.
Multimodal: Nova 2.0 Omni is one of few models, alongside most notably the Gemini model series, that can natively handle text, image, video and speech inputs. This is a new differentiator for Amazon’s Nova model series.
Competitive pricing: Amazon has priced Nova 2.0 Pro at $1.25/$10 per million input/output tokens, and considering token usage the model took $662 to run our Artificial Analysis Intelligence Index. This is substantially less than other frontier models like Claude 4.5 Sonnet ($817) and Gemini 3 Pro ($1201), but remains above others including Kimi K2 Thinking ($380). Nova 2.0 Lite and Omni are both priced at $0.3/$2.5 per million input/output tokens.
See below for further analysis
As President, I would read 10 letters a day sent to me by ordinary Americans. At the Obama Presidential Center, we’ll have some of the letters I read — and responded to — every night. I still get emotional reading them, and it’s one of my favorite exhibits.
People complain about corporate "short-termism", "chasing quarterly profits" and so on but what makes them really angry, what truly enrages them beyond all reason, is seeing corporations with an actual long-term vision willing to endure years of losses in pursuit of a goal.
US productivity growth is likely to come in at about 2.7% for 2025.
That is nearly double the average of the previous 10 years.
There are many factors at work, but part of the story is that businesses are finally beginning to reap some of AI's benefits.
I discuss the latest evidence in my column in the @FT this morning.
See https://t.co/3gotWePS7d
Someone asked about tricks for meeting eminent people. I said the best plan is just to do really good work. Then you'll tend to meet them organically. In the worst case you'll see one whenever you look in the mirror.
The amount of crap I get for putting out a hobby project for free is quite something.
People treat this like a multi-million dollar business. Security researchers demanding a bounty.
Heck, I can barely buy a Mac Mini from the Sponsors.
It's supposed to inspire people. And I'm glad it does.
And yes, most non-techies should not install this.
It's not finished, I know about the sharp edges.
Heck, it's not even 3 months old.
And despite rumors otherwise, I sometimes sleep.
Okay, I'm in a bit of a sentimental mood (it's those Sunday evenings, man), but here's one thing that I keep thinking about:
I wish we all would respond to the loss that some programmers feel right now with a bit more grace.
Some reactions can come across as "it's always been about shipping, dummy" or "huh-duh it's never been about the code, always the results".
And that feels a bit deaf, doesn't it? I mean, let's be honest, for many of us it's been about more than that.
Lots of programmers — myself included! — feel a great amount of joy when they see (or even better: write) the perfect line of code, where abstraction and syntax and semantics meet and hug and everything comes together.
We travelled to meetups and conferences and had hour long conversations with strangers about favorite styles of writing code, about keyboards, colorschemes, keybindings, syntactic flourishes, ways to comment code, cherished parts of standard libs, beautiful ways to rewrite a function that we've all written.
I know a guy who said he makes life decisions based on whether he gets to work with a certain programming language more or less.
Digesting the fact that things are changing and that some things we cherished might be replaced by other things — that takes a different amount of time for different people.
Reasoning models tailored for diverse AI tasks. 🚀
Meet Amazon Nova 2 foundation models, supporting fast, cost-effective reasoning to multimodal capabilities. Power versatile tasks like AI agents, code-generation, and Conversational AI. Choose the perfect match for your workload.
We've been hard at work solving a persistent industry problem: frontier models launch with impressive benchmarks, organizations test them, then they don't work for actual needs. To help bridge this gap, we're excited to announce Amazon Nova Forge – a new way to build frontier AI models that are experts in your domain.
Amazon's Nova 2 models are here:
➡️ Lite: Fast and cost-effective reasoning for everyday tasks
➡️ Pro: For highly complex tasks like agentic coding, long-range planning, and sophisticated problem-solving – where the highest accuracy is essential
➡️ Sonic: Expanded multilingual support with expressive voices, higher accuracy
➡️ Omni: Unified multimodal reasoning and generation model that can process text, images, video, and speech inputs while generating both text and images – an industry first.
🔎 Dive deeper into what's possible. https://t.co/1OfagAOSjp
Very unexpected results! Grok 4.1 Fast Reasoning beats every frontier model in Tau2-Verified!
Congrats team! I was certainly not expecting a Fast model to beat @AnthropicAI 's Opus 4.5 in agentic tasks @xai@elonmusk@Yuhu_ai_
Check it out: https://t.co/cmOPOXaZbM
Wait what!? We robustified tau2-bench and found that the newly released model from @OpenAI (GPT-5.1) performs way worse than GPT-5 and GPT-5-mini.
All while being 5x more expensive than GPT-5-mini!
But, why? We have a theory...
one of the core tenants behind verifiers and the Environments Hub is that eval implementations should be public, installable, interoperable, versioned, and compatible with arbitrary model endpoints
every model release having a one-off "evals" repo with custom prompts is a mess