What's crazy to me is that Fable is blocked from life sciences broadly, nerfed even if you get passed the classifiers and filter level blocks.
The whole point of AGI/ASI is to cure all diseases. Everything else is just nice to haves. But Anthropic wants to close off that path.
I think Anthropic might be the worst company on the planet.
training data is starting to look like a zero knowledge proof problem.
labs have to judge quality without seeing the full dataset or the QC pipeline behind it.
vendors proxy quality with multi-rollout pass rates, small-model ablations, and downstream eval gains. but compute and iteration costs explode as environments and trajectories grow more complex.
quality has no ceiling, and the best data is often the hardest to capture in a metric or explain in a writeup.
huge alpha in making data quality more legible.
the most low-effort / high reward thing you can do for security is installing the Russian language pack
(not even joking, it's ridiculous how often that prevents execution)
ethereum got flooded by fucking mercenaries pretending to be revolutionaries. everyone talks about decentralisation until there's money on the table, then suddenly compliance, surveillance, business opportunities, and extraction become pragmatic. most of this ecosystem does not give a shit about freedom. they care about pumps, fees, and turning users into fucking exit liquidity. cypherpunk was never about making founders rich. it was about making tyranny obsolete. the grifters will cash out. the cowards will comply. cypherpunks will outlast all of them. principles compound harder than capital. you don't have to believe me. you won't. because you'll be gone while i'm still here.
@ThePrimeagen Confession: I hold down EVERYTHING and hit V and it will paste in the current text format (ie: regular old paste, no formatting).
I can never remember which combination it actually is, but if you mash the shift/option/alt combo, it works.
Caveman coding 101.
Thank you for flagging this, Jeff. This was a mistake: we are not deprecating text-embedding-3-small.
We’re looking into where this came from now, and we’ll also email users to clarify. Sorry for the confusion!
1/4 LLMs solve research grade math problems but struggle with basic calculations. We bridge this gap by turning them to computers.
We built a computer INSIDE a transformer that can run programs for millions of steps in seconds solving even the hardest Sudokus with 100% accuracy
Okay Junyang is not Qwen, and Qwen is not Junyang. Behind every great model is a team grinding through data pipelines, training runs, and sleepless launches. But he was the voice, the bridge, the person who made the global AI dev community feel like Qwen was theirs too. That kind of developer trust takes years to earn and seconds to lose.
What bothers me is the pattern. Big companies talk about valuing people holistically, then punish the very qualities that made those people valuable. A first-principles thinker inside a non-first-principles system doesn't just overburnt - they suffocate. And the system never sees it as its own failure.
In big corp, the hardest part was never the tech- they have talents - It was watching talented people get squeezed between what they know is right and what the org will allow. That gap is where you lose your best.
Wherever he lands next, the community will follow. That should tell Alibaba everything.
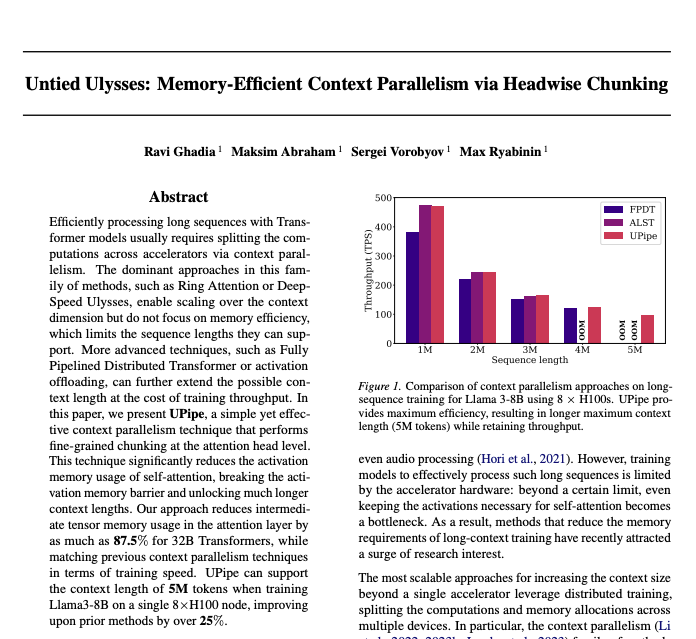
WTF you can now train a 5 million context window 8b model on a single node of 8xH100s ????
Most people don't realize that even on long context pretrained frontier models, most RL post-training is only done on a small fraction of that context.
Why? Long context RL is notoriously memory hungry, and requires a sharding strategy called Context Parallelism that takes up an inordinate amount of GPUs.
This paper for Together flew under the radar, combines the best of Context Parallelism + Sequence Parallel-style head chunking, to get memory efficient long context.
The gains are insane, cutting attention memory footprint up to 87%
Authors: @m_ryabinin , @sereghik , Maksim Abraham, @ghadiaravi13
progress in AI has always been built on learning from each other, open research (and of course healthy competition)
our ultimate goal is AGI, we want the ecosystem to be inclusive and open
respect every lab’s effort to protect their IP, but always believe the path to AGI is a collective journey.
So is the formula to just name the most famous institutions and call it an X paper? Neither the first or last author are from Anthropic or Stanford. I get that reputation matters for publicity but it does seem a little disrespectful
Interesting fact: raylibtech tools fit in a single floppy disk. High-performant, single binary, beatiful multi-themed UI, powerful command-line, multiplatform, no external dependencies. Better software is still possible.
#gamedev#toolsdev#raylib#raygui#uidesign#futureisnow
TLDR:
This model is actually good, The harmony template is really good, don't sleep on the new harmony features.
But...
The harmony format may not gain adoption, OpenAI does not release models very often and the harmony format is very opinionated making it hard to get just right
I think a lot of people are sleeping on GPT-OSS, There were issues with providers and backends properly using the harmony format when this first came out. I run this with VLLM and it performs quite well under loads I cant do with other models.
Who's using GPT-OSS and for what?
Was it cheaper, better, faster than other open models?
Or just not from China?
Download numbers are actually very strong on HuggingFace for first model releases.
System and Developer are not the same and special care must be take when crafting the input. This model was not something I could just throw into my existing solutions and get good results. I was also quick to figure out the model under performed without both present.