Two economists just published a mathematical proof that AI will destroy the economy.
Not might. Not could. Will — if nothing changes.
The paper is called "The AI Layoff Trap." Published March 2, 2026. Wharton School, University of Pennsylvania. Boston University. Peer reviewed. Mathematically modeled.
The conclusion is one sentence.
"At the limit, firms automate their way to boundless productivity and zero demand."
An economy that produces everything. And sells it to nobody.
Here is how you get there.
A company fires 500 workers and replaces them with AI. A competitor fires 700 to keep up. Another fires 1,000. Every company is behaving rationally. Every company is following the incentives correctly. And every company is building a trap for itself.
Because the workers who were fired were also customers.
When they lose their jobs faster than the economy can absorb them, they stop spending. Consumer demand falls. Companies respond by cutting costs — which means automating more workers — which means less spending — which means more falling demand — which means more automation.
The loop has no natural exit.
The researchers tested every proposed solution. Universal basic income. Capital income taxes. Worker equity participation. Upskilling programs. Corporate coordination agreements.
Every single one failed in the model.
The only intervention that worked: a Pigouvian automation tax — a per-task levy charged every time a company replaces a human with AI, forcing them to price in the demand they are destroying before they pull the trigger.
No government has implemented this. No major economy is seriously discussing it.
Meanwhile the numbers are already tracking the curve. 100,000 tech workers laid off in 2025. 92,000 more in the first months of 2026. Jack Dorsey fired half of Block's workforce and said publicly: "Within the next year, the majority of companies will reach the same conclusion."
Nobody is doing anything wrong. Companies are following their incentives perfectly. That is exactly the problem.
Rational behavior. At scale. Simultaneously. With no mechanism to stop it.
Two economists built the math. The math leads to one place.
Source: Falk & Tsoukalas · Wharton School + Boston University ·
Two economists just published a mathematical proof that AI will destroy the economy.
Not might. Not could. Will — if nothing changes.
The paper is called "The AI Layoff Trap." Published March 2, 2026. Wharton School, University of Pennsylvania. Boston University. Peer reviewed. Mathematically modeled.
The conclusion is one sentence.
"At the limit, firms automate their way to boundless productivity and zero demand."
An economy that produces everything. And sells it to nobody.
Here is how you get there.
A company fires 500 workers and replaces them with AI. A competitor fires 700 to keep up. Another fires 1,000. Every company is behaving rationally. Every company is following the incentives correctly. And every company is building a trap for itself.
Because the workers who were fired were also customers.
When they lose their jobs faster than the economy can absorb them, they stop spending. Consumer demand falls. Companies respond by cutting costs — which means automating more workers — which means less spending — which means more falling demand — which means more automation.
The loop has no natural exit.
The researchers tested every proposed solution. Universal basic income. Capital income taxes. Worker equity participation. Upskilling programs. Corporate coordination agreements.
Every single one failed in the model.
The only intervention that worked: a Pigouvian automation tax — a per-task levy charged every time a company replaces a human with AI, forcing them to price in the demand they are destroying before they pull the trigger.
No government has implemented this. No major economy is seriously discussing it.
Meanwhile the numbers are already tracking the curve. 100,000 tech workers laid off in 2025. 92,000 more in the first months of 2026. Jack Dorsey fired half of Block's workforce and said publicly: "Within the next year, the majority of companies will reach the same conclusion."
Nobody is doing anything wrong. Companies are following their incentives perfectly. That is exactly the problem.
Rational behavior. At scale. Simultaneously. With no mechanism to stop it.
Two economists built the math. The math leads to one place.
Source: Falk & Tsoukalas · Wharton School + Boston University ·
It’s never been easier to design your dream house.
Draw a shape. Define your rooms. Set your constraints.
@DraftedAI generates complete floor plans, elevations, and 3D home designs in seconds.
Over the last month, 120,000 people generated 325,000+ home designs with https://t.co/XqC0LP5n3y.
If AI becomes the new electricity, do we want a closed-source grid or a decentralized, transparent one? The case for open-source sovereignty is stronger than ever. #OpenSourceAI#LLM
The most common failure mode in Enterprise AI: treating a model like a product instead of a component. If you aren't building a data pipeline, you aren't building an enterprise system
@BusinessTechSA Credit is only beneficial if you can generate a return on investment and repay it. The problem here is that the people being given credit know how to consume, but not how to produce
@LinkedInHelp this is getting ridiculous. 5 cases closed, months of waiting, valid passport submitted, still no access. My account was hacked, renamed “Leona Adam,” and locked with 2FA. Your system is failing me. Please escalate to a human reviewer ASAP. Ref: 260413-029201
@abra55513382 I think CSPs are the next big disruption target. Distributed compute in a world of AI seems like an obvious outcome. We’re just waiting for its “Hello world” moment so we know it is possible.
@elonmusk@elonmusk Free internet alone won't move the needle, SA's telecoms already offer limited connectivity to some schools. The real opportunity? Starlink-connected devices with AI(Grok) embedded natively, built specifically for SA's curriculum and languages.
Quantum-linked stocks are skyrocketing:
South Korean firms ICTK and Axgate soared +30% and reached their daily trading limit during Wednesday’s session.
At the same time, China's GuoChuang Software and QuantumCTek, along with Japan's Fixstars, each surged at least +8%.
Over the last week, ICTK and Axgate are up +60% and +141%, respectively.
This comes as NVIDIA, $NVDA, launched a new collection of open-source AI models on Tuesday, aimed at accelerating quantum computing and making it scalable for practical use.
Meanwhile, the global quantum computing market is projected to more than QUADRUPLE to over $11.0 billion by 2030, from ~$1.7 billion in 2024.
Quantum computing is accelerating.
Hey @LinkedInHelp ! My account was hacked, my name was changed to 'Leona Adam', and the hacker locked me out with 2FA. I've submitted my ID verification twice (Cases: 260413-029201 & 260319-024512) but your automated system keeps rejecting me. I need a real human to review this
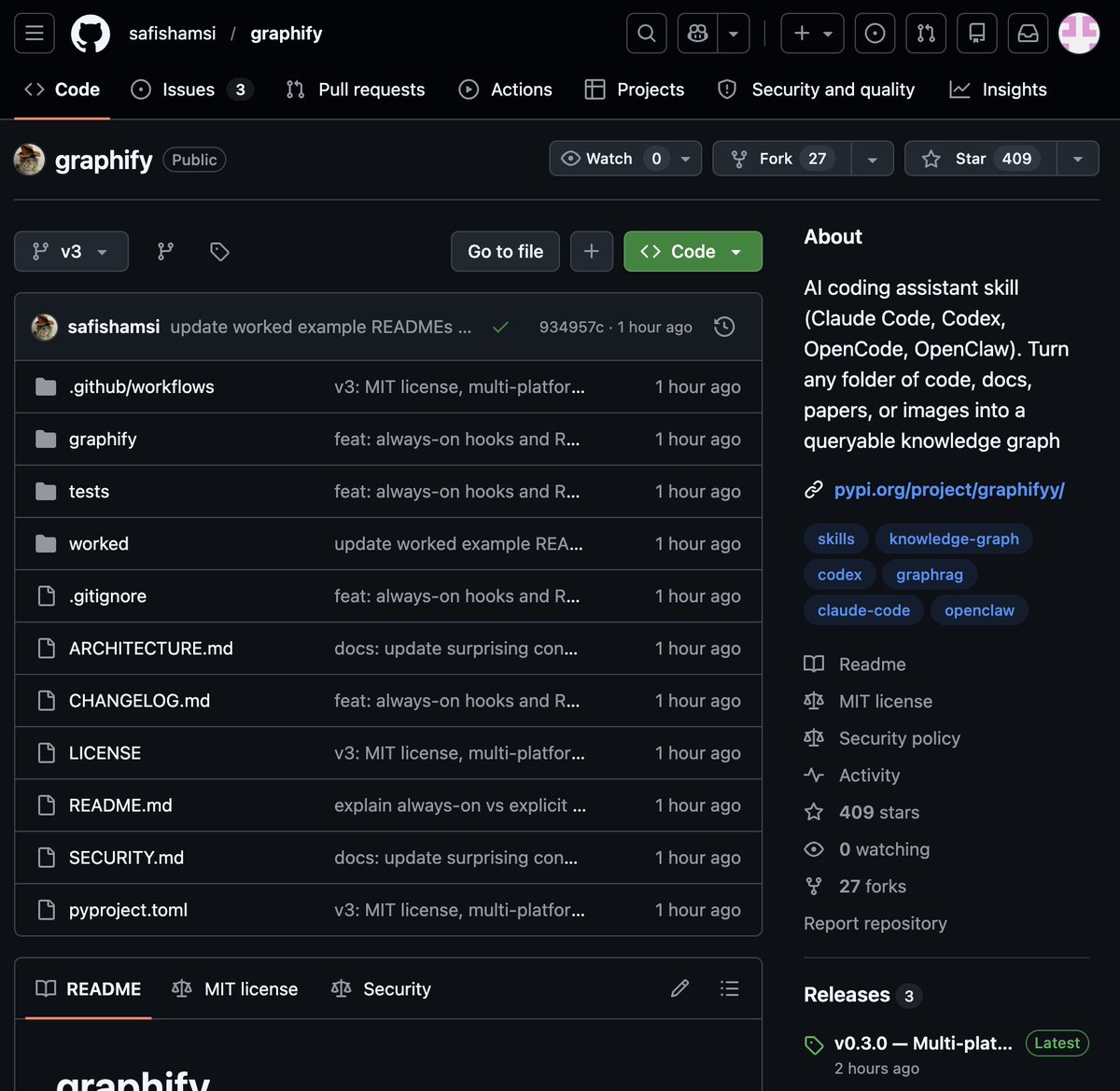
🚨 BREAKING: Someone just built the exact tool Andrej Karpathy said someone should build.
48 hours after Karpathy posted his LLM Knowledge Bases workflow, this showed up on GitHub.
It's called Graphify. One command. Any folder. Full knowledge graph.
Point it at any folder. Run /graphify inside Claude Code. Walk away.
Here is what comes out the other side:
-> A navigable knowledge graph of everything in that folder
-> An Obsidian vault with backlinked articles
-> A wiki that starts at index. md and maps every concept cluster
-> Plain English Q&A over your entire codebase or research folder
You can ask it things like:
"What calls this function?"
"What connects these two concepts?"
"What are the most important nodes in this project?"
No vector database. No setup. No config files.
The token efficiency number is what got me:
71.5x fewer tokens per query compared to reading raw files.
That is not a small improvement. That is a completely different paradigm for how AI agents reason over large codebases.
What it supports:
-> Code in 13 programming languages
-> PDFs
-> Images via Claude Vision
-> Markdown files
Install in one line:
pip install graphify && graphify install
Then type /graphify in Claude Code and point it at anything.
Karpathy asked. Someone delivered in 48 hours.
That is the pace of 2026.
Open Source. Free.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Today is a monumentous day for quantum computing and cryptography. Two breakthrough papers just landed (links in next tweet). Both papers improve Shor's algorithm, infamous for cracking RSA and elliptic curve cryptography. The two results compound, optimising separate layers of the quantum stack. The results are shocking. I expect a narrative shift and a further R&D boost toward post-quantum cryptography.
The first paper is by Google Quantum AI. They tackle the (logical) Shor algorithm, tailoring it to crack Bitcoin and Ethereum signatures. The algorithm runs on ~1K logical qubits for the 256-bit elliptic curve secp256k1. Due to the low circuit depth, a fast superconducting computer would recover private keys in minutes. I'm grateful to have joined as a late paper co-author, in large part for the chance to interact with experts and the alpha gleaned from internal discussions.
The second paper is by a stealthy startup called Oratomic, with ex-Google and prominent Caltech faculty. Their starting point is Google's improvements to the logical quantum circuit. They then apply improvements at the physical layer, with tricks specific to neutral atom quantum computers. The result estimates that 26,000 atomic qubits are sufficient to break 256-bit elliptic curve signatures. This would be roughly a 40x improvement in physical qubit count over previous state-of-the-art. On the flip side, a single Shor run would take ~10 days due to the relatively slow speed of neutral atoms.
Below are my key takeaways. As a disclaimer, I am not a quantum expert. Time is needed for the results to be properly vetted. Based on my interactions with the team, I have faith the Google Quantum AI results are conservative. The Oratomic paper is much harder for me to assess, especially because of the use of more exotic qLDPC codes. I will take it with a grain of salt until the dust settles.
→ q-day: My confidence in q-day by 2032 has shot up significantly. IMO there's at least a 10% chance that by 2032 a quantum computer recovers a secp256k1 ECDSA private key from an exposed public key. While a cryptographically-relevant quantum computer (CRQC) before 2030 still feels unlikely, now is undoubtedly the time to start preparing.
→ censorship: The Google paper uses a zero-knowledge (ZK) proof to demonstrate the algorithm's existence without leaking actual optimisations. From now on, assume state-of-the-art algorithms will be censored. There may be self-censorship for moral or commercial reasons, or because of government pressure. A blackout in academic publications would be a tell-tale sign.
→ cracking time: A superconducting quantum computer, the type Google is building, could crack keys in minutes. This is because the optimised quantum circuit is just 100M Toffoli gates, which is surprisingly shallow. (Toffoli gates are hard because they require production of so-called "magic states".) Toffoli gates would consume ~10 microseconds on a superconducting platform, totalling ~1,000 sec of Shor runtime.
→ latency optimisations: Two latency optimisations bring key cracking time to single-digit minutes. The first parallelises computation across quantum devices. The second involves feeding the pubkey to the quantum computer mid-flight, after a generic setup phase.
→ fast- and slow-clock: At first approximation there are two families of quantum computers. The fast-clock flavour, which includes superconducting and photonic architectures, runs at roughly 100 kHz. The slow-clock flavour, which includes trapped ion and neutral atom architectures, runs roughly 1,000x slower (~100 Hz, or ~1 week to crack a single key).
→ qubit count: The size-optimised variant of the algorithm runs on 1,200 logical qubits. On a superconducting computer with surface code error correction that's roughly 500K physical qubits, a 400:1 physical-to-logical ratio. The surface code is conservative, assuming only four-way nearest-neighbour grid connectivity. It was demonstrated last year by Google on a real quantum computer.
→ future gains: Low-hanging fruit is still being picked, with at least one of the Google optimisations resulting from a surprisingly simple observation. Interestingly, AI was not (yet!) tasked to find optimisations. This was also the first time authors such as Craig Gidney attacked elliptic curves (as opposed to RSA). Shor logical qubit count could plausibly go under 1K soonish.
→ error correction: The physical-to-logical ratio for superconducting computers could go under 100:1. For superconducting computers that would be mean ~100K physical qubits for a CRQC, two orders of magnitude away from state of the art. Neutral atoms quantum computers are amenable to error correcting codes other than the surface code. While much slower to run, they can bring down the physical to logical qubit ratio closer to 10:1.
→ Bitcoin PoW: Commercially-viable Bitcoin PoW via Grover's algorithm is not happening any time soon. We're talking decades, possibly centuries away. This observation should help focus the discussion on ECDSA and Schnorr. (Side note: as unofficial Bitcoin security researcher, I still believe Bitcoin PoW is cooked due to the dwindling security budget.)
→ team quality: The folks at Google Quantum AI are the real deal. Craig Gidney (@CraigGidney) is arguably the world's top quantum circuit optimisooor. Just last year he squeezed 10x out of Shor for RSA, bringing the physical qubit count down from 10M to 1M. Special thanks to the Google team for patiently answering all my newb questions with detailed, fact-based answers. I was expecting some hype, but found none.
Hey @LinkedInHelp! My account was hacked, my name was changed to 'Leona Adam', and the hacker locked me out with 2FA. I've submitted my ID verification twice (Cases: 251207-012108 & 260112-024200) but your automated system keeps rejecting me. I need a real human to review this