@CasperOnChain Half a billion in candy-flavored nicotine. Hundreds of thousands of children with destroyed lungs. He calls it “a global brand in one year.” The rest of us call it what it is: a body count he’s proud of.
@Schuldensuehner Negative prices aren't a generation problem, they're a flexibility problem. 117 GW PV, almost no storage, smart meter rollout stuck. That's the actual scandal, not the cheap electricity.
My 6 year old is the creative director. His design document: "mega blast."
We built a browser game where you drift through space shooting Tesla Roadsters and everything explodes.
He says it needs more explosions. He's always right.
https://t.co/fakrk59JvS
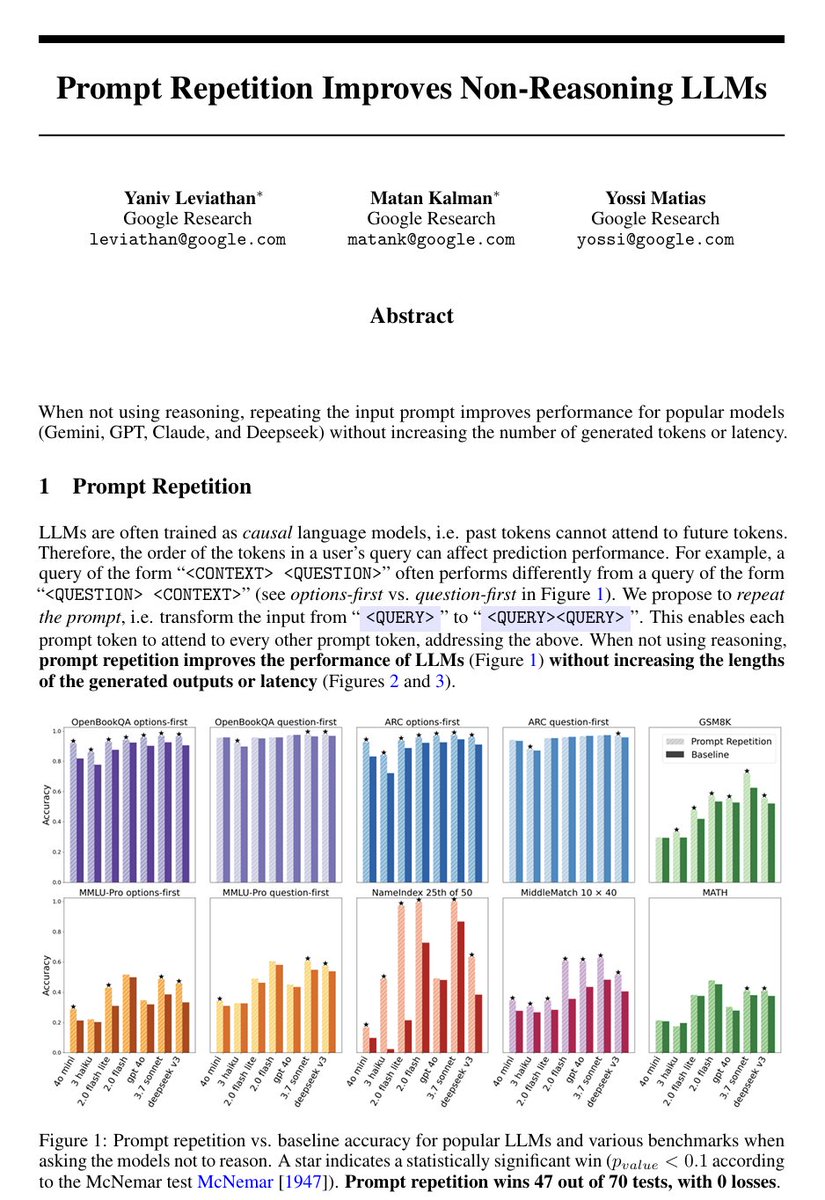
Improve your LLM response by repeating the prompt verbatim.
This means your input should look like:
Prompt question. Prompt question.
Women have known this for centuries.
LLMs process text from left to right — each token can only look back at what came before it, never forward. This means that when you write a long prompt with context at the beginning and a question at the end, the model answers the question having "seen" the context, but the context tokens were generated without any awareness of what question was coming. This asymmetry is a basic structural property of how these models work.
The paper asks what happens if you just send the prompt twice in a row, so that every part of the input gets a second pass where it can attend to every other part. The answer is that accuracy goes up across seven different benchmarks and seven different models (from the Gemini, ChatGPT, Claude, and DeepSeek series of LLMs), with no increase in the length of the model's output and no meaningful increase in response time — because processing the input is done in parallel by the hardware anyway.
There are no new losses to compute, no finetuning, no clever prompt engineering beyond the repetition itself.
The gap between this technique and doing nothing is sometimes small, sometimes large (one model went from 21% to 97% on a task involving finding a name in a list). If you are thinking about how to get better results from these models without paying for longer outputs or slower responses, that's a fairly concrete and low-effort finding.
Read with AI tutor: https://t.co/MipHHO6rjX
Get the PDF: https://t.co/XQrqiaGwIO
@elonmusk Of course they mean it. Our society only works because we believe everyone is equal before the law — no matter how rich, powerful, or connected they are.