@madebygoogle@sundarpichai Pixel have swollen battery & it pushed the screen out.
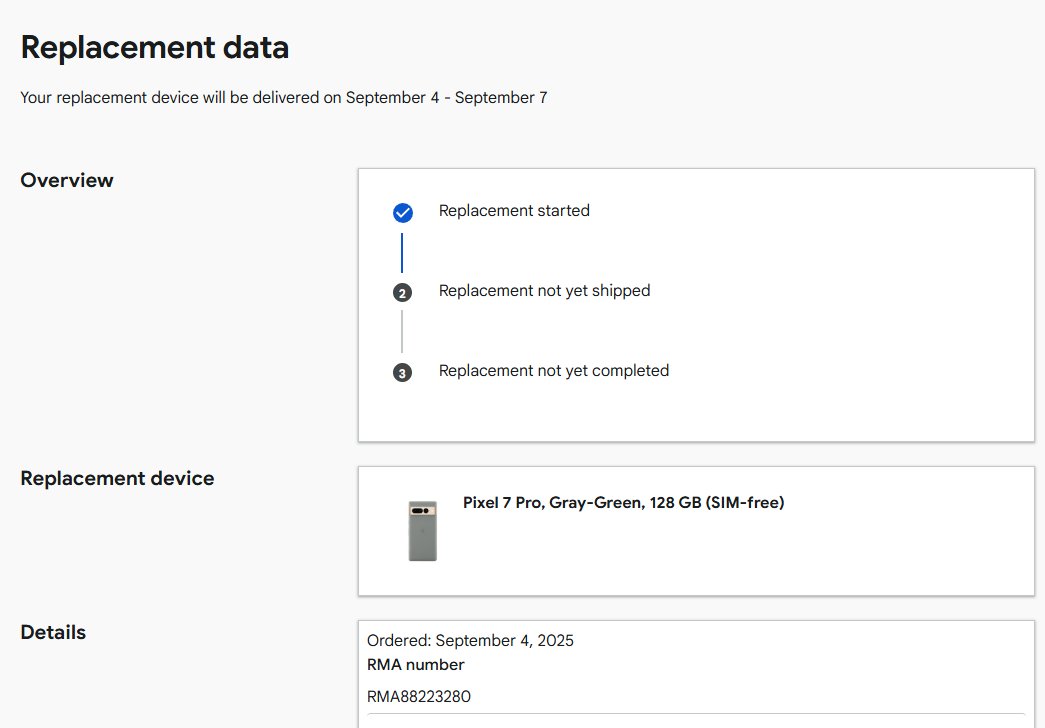
Without a phone for > 1 week. Delivery due date for replacement phone was 6 Sep but its NOT even shipped.
Expected Google to treat customers way better. Next time going to get iphone
RMA88223280
@madebygoogle 10th day since battery hazard raised with @madebygoogle . Replacement phone is still not even shipped.
Evertime customer support just says wait 48 hours and nothing happens. @rosterloh@sundarpichai please make reliable phones like @Apple or level up customer service.
Someone asked me recently why the Paris AI ecosystem is so 🔥 these days.
On the surface, it looks like Paris became a major #AI center overnight, but it didn't.
It took time and didn't appear by accident.
Here is a story that started more than 10 years ago.
👇
We are not AMD's QA team, and we have no relationship with them. I saw some stuff last year that gave me hope, but this platform has been out for 14 months now, and there's still serious issues.
It upsets me that the MES isn't open source. While more stuff is open source than NVIDIA, if there's blobs we do not own the hardware, and I don't feel great about investing time into this.
The compiler bug today is icing on the cake. At first I thought it was the `launch_bounds` feature, but it looks like it can be triggered without that. Not being able to trust a compiler undermines so much trust in the entire platform.
It would set us back, but maybe we should switch to either 3090s or @intel GPUs. Either way, we aren't shipping the tinybox (or ordering bulk 7900XTX) until this is figured out.
Introducing training LLMs with AMD hardware!
MosaicML + PyTorch 2.0 + ROCm 5.4+ = LLM training out of the box with zero code changes.
With MosaicML, the ML community has additional hardware + software options to choose from.
Read more: https://t.co/S3a77FYbcD
iPhone® leaves a big case to fill, but Pixel is ready to live up to the legend.
Watch the full #BestPhonesForever series on our YouTube channel: https://t.co/SKXpv2cPiF
@soumithchintala@FedorShabashev Agree that Nvidia's cuda is not required for inference and cane be done on CPU. But what about fine tuning LLM models? These still heavily depends on CUDA since alternatives like ROCM and OneAPI are not officially upstreamed to pytorch and tensorflow yet.
@GergelyOrosz Why won't valuations of these private pre IPO companies also fall 70-80% like public competitors?These pre ipo companies would also be forced to cut valuations by 70% if they wanna raise money from investors in the current market correct?