"मैं अपनी फ़ेवरेट हूँ!"
फ़िल्म जब वी मेट (2007) का यह चुलबुला संवाद जब गीत ट्रेन की सीट पर बैठे-बैठे पूरे आत्मविश्वास से कहती है-
"मैं अपनी फ़ेवरेट हूँ!"
तो हम मुस्कुरा देते हैं।
पहली नज़र में यह एक बेफ़िक्र, थोड़ी नटखट और आत्ममुग्ध लड़की का संवाद लगता है। लेकिन यदि इस दृश्य को कुछ क्षणों के लिए रोककर उसके पीछे छिपे मनोविज्ञान को देखें, तो यह आधुनिक मनुष्य के सबसे बड़े संकट-स्वीकृति की भूख (Validation Seeking)-पर सीधा प्रहार करता हुआ दिखाई देता है।
क्योंकि हममें से अधिकांश लोग अपने बारे में वही मानते हैं जो दुनिया हमारे बारे में मानती है।
दर्पण की तलाश में भटकता मन
सुबह से लेकर रात तक हम अनगिनत अदृश्य दर्पणों में स्वयं को खोजते रहते हैं।
किसी ने हमारी प्रशंसा कर दी तो दिन अच्छा हो जाता है।
किसी ने आलोचना कर दी तो आत्मविश्वास डगमगा जाता है।
एक पोस्ट पर अधिक लाइक्स आ गए तो हम प्रसन्न हो जाते हैं।
कम आए तो भीतर कहीं हल्की-सी कमी महसूस होने लगती है।
धीरे-धीरे हमारी पहचान हमारे भीतर नहीं रहती; वह दूसरों की राय में बसने लगती है।
मानो हमारा रिमोट कंट्रोल हमारे हाथों में नहीं, संसार के हाथों में हो।
बाहरी खोज यही है-
खुद को स्वीकार करने के लिए भी किसी और की अनुमति का इंतज़ार करना।
सोचना कि जब कोई हमें योग्य, सुंदर, सफल या प्रेम के योग्य घोषित करेगा, तभी हम वास्तव में वैसे होंगे।
लेकिन गीत का संवाद इस पूरी व्यवस्था को एक झटके में उलट देता है।
वह स्वयं को किसी और की नज़रों से नहीं देखती।
वह अपने पागलपन, अपनी कमियों, अपनी विचित्रताओं और अपनी जीवंतता-सबको स्वीकार करती है।
और शायद इसी कारण वह स्वतंत्र दिखाई देती है।
प्रेम और आत्ममुग्धता का अंतर
यहाँ एक सूक्ष्म अंतर समझना आवश्यक है।
स्वयं को पसंद करना और स्वयं को संसार का केंद्र मान लेना-दो अलग बातें हैं।
आत्ममुग्धता (Narcissism) कहती है-
"मैं सबसे बेहतर हूँ।"
आत्मस्वीकृति (Self-Acceptance) कहती है-
"मैं जैसा हूँ, वैसा होने की अनुमति खुद को देता हूँ।"
पहले में तुलना है।
दूसरे में सहजता है।
पहले में अहंकार है।
दूसरे में आत्मीयता है।
गीत का "मैं अपनी फ़ेवरेट हूँ" वास्तव में तुलना की घोषणा नहीं, बल्कि आत्मस्वीकृति की घोषणा है।
• वेदांत की दृष्टि से: आत्मरति
वेदांत इस विचार को और भी गहरे स्तर पर ले जाता है।
बृहदारण्यक उपनिषद का प्रसिद्ध वाक्य है-
"आत्मनस्तु कामाय सर्वं प्रियं भवति।"
अर्थात् संसार में जो कुछ भी हमें प्रिय लगता है, वह वास्तव में इसलिए प्रिय है क्योंकि उसके माध्यम से हम अपने ही आत्मस्वरूप के आनंद का स्पर्श करते हैं।
वेदांत कहता है कि मनुष्य जीवनभर प्रेम, सम्मान, स्वीकृति और आनंद की खोज बाहर करता रहता है।
कभी संबंधों में।
कभी उपलब्धियों में।
कभी प्रसिद्धि में।
कभी प्रशंसा में।
लेकिन जिसकी तलाश है, उसका स्रोत भीतर ही है।
अहंकार हमेशा परनिर्भर होता है।
उसे स्वयं को महत्वपूर्ण महसूस कराने के लिए किसी दूसरे की आवश्यकता पड़ती है।
वह लगातार तुलना, प्रतिस्पर्धा और स्वीकृति की तलाश में रहता है।
लेकिन आत्मा आत्मरति में स्थित होती है।
आत्मरति का अर्थ है-स्वयं में ही रमण करना, स्वयं में ही संतुष्ट होना।
यह अकेलेपन की अवस्था नहीं है।
यह आंतरिक पूर्णता की अवस्था है।
तब व्यक्ति संसार से प्रेम माँगता नहीं, बल्कि प्रेम बाँटता है।
तब वह दूसरों की स्वीकृति पर जीवित नहीं रहता, बल्कि अपनी उपस्थिति से दूसरों को स्वीकार करना सीखता है।
• एक ठहराव
आज जब आप आईने के सामने खड़े हों, तो केवल अपना चेहरा मत देखिएगा।
कुछ क्षण अपनी ही आँखों में झाँकिएगा।
और स्वयं से पूछिएगा-
यदि संसार के सारे लाइक्स, प्रशंसाएँ और प्रमाणपत्र मुझसे छीन लिए जाएँ, तो क्या मैं तब भी स्वयं के साथ सहज रह पाऊँगा?
क्या मैं सचमुच अपने ही साथ बैठ सकता हूँ?
क्या मैं स्वयं का मित्र हूँ?
क्योंकि जो व्यक्ति स्वयं के साथ रहने में असहज है, वह पूरी दुनिया के बीच भी अकेला रहेगा।
और जो स्वयं से मैत्री कर लेता है, उसके भीतर एक ऐसा घर बन जाता है जहाँ उसे बार-बार लौटने की आवश्यकता नहीं पड़ती-वह कभी वहाँ से जाता ही नहीं।
शायद यही कारण है कि स्वतंत्रता की शुरुआत तब होती है, जब भीतर से एक सरल-सी आवाज़ उठती है-
"मुझमें कमियाँ भी हैं, खूबियाँ भी हैं। मैं अभी पूर्ण नहीं हूँ, फिर भी स्वयं को स्वीकार करता हूँ।"
और शायद उसी क्षण, गीत की मुस्कान के पीछे छिपा जीवन-दर्शन समझ में आने लगता है-
"मैं अपनी फ़ेवरेट हूँ।"
|| ॐ नमो नारायण ||
~ अतरंगी
#musings
मैं एक बच्चे के सामने झुकना चाहता हूँ
कि प्यार की ऊँचाई नाप सकूँ
और तानाशाह के आगे तनना चाहता हूँ
ताकि ऊँचाई के बौनेपन को देख सकूँ!
बस चाँद रोएगा • मदन कश्यप
@IGLConnect there is a worst management at sector 142 Noida filling station,
Machines are not working, employees are not talking to customers properly. I just came out from the filling station and raise my concern over there also
@Igl_Care I sent you my contact details, is there anything you will be doing?
Another point -
1. What we are not able to find details on IGL website where we can complaint?
2. Don’t you think you have costumer care number to make any complaint
@IGLConnect there is a worst management at sector 142 Noida filling station,
Machines are not working, employees are not talking to customers properly. I just came out from the filling station and raise my concern over there also
Built for application developers. Designed for DBAs.
Databricks Lakebase modernizes OLTP with:
- Familiar Postgres semantics for developers
- Automatic scaling and recovery for admins
- Separation of compute and durable state
- One platform for operational, analytical, and AI workloads
Now Generally Available:
https://t.co/NFGuFldfQX
Microsoft & LinkedIn released a professional certificate in Generative Al🤩
No prerequisites or fees required.
Here are 21 FREE courses you don't want to miss:
1️⃣ 𝐈𝐧𝐭𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧 𝐭𝐨 𝐀𝐥: An overview of AI tools for project managers, executives, and students starting their AI career.
👉 https://t.co/xcy1ElMB9h
2️⃣ 𝐖𝐡𝐚𝐭 𝐈𝐬 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐯𝐞 𝐀𝐥?: Learn about the basics, history, working principles, and ethical implications of Generative AI.
👉 https://t.co/mrBBWaBz2s
3️⃣ 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐯𝐞 𝐀𝐥: The Evolution of Thoughtful Online Search:
👉 https://t.co/iZganAsFsg
4️⃣ 𝐒𝐭𝐫𝐞𝐚𝐦𝐥𝐢𝐧𝐢𝐧𝐠 𝐘𝐨𝐮𝐫 𝐖𝐨𝐫𝐤 𝐰𝐢𝐭𝐡 𝐁𝐢𝐧𝐠 𝐂𝐡𝐚𝐭:
👉 https://t.co/mYgugj8R63
5️⃣ 𝐄𝐭𝐡𝐢𝐜𝐬 𝐢𝐧 𝐭𝐡𝐞 𝐀𝐠𝐞 𝐨𝐟 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐯𝐞 𝐀𝐥
👉 https://t.co/YveSdExqSZ
6️⃣ 𝐌𝐢𝐜𝐫𝐨𝐬𝐨𝐟𝐭 𝐀𝐳𝐮𝐫𝐞 𝐀𝐈 𝐅𝐮𝐧𝐝𝐚𝐦𝐞𝐧𝐭𝐚𝐥𝐬
👉 https://t.co/SW5F4N4dAL
7️⃣ 𝐈𝐧𝐭𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧 𝐭𝐨 𝐌𝐚𝐜𝐡𝐢𝐧𝐞 𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠
👉 https://t.co/SqCdZOv08O
8️⃣ 𝐀𝐈 𝐟𝐨𝐫 𝐁𝐞𝐠𝐢𝐧𝐧𝐞𝐫𝐬 - By Microsoft
👉 https://t.co/KoBf6sL6Wg
9️⃣ 𝐀𝐈 𝐟𝐨𝐫 𝐄𝐯𝐞𝐫𝐲𝐨𝐧𝐞
👉 https://t.co/YBemAFKNBW
🔟 𝐃𝐞𝐞𝐩 𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠 𝐒𝐩𝐞𝐜𝐢𝐚𝐥𝐢𝐳𝐚𝐭𝐢𝐨𝐧
👉 https://t.co/M8xvvwxb0r
11. 𝐈𝐧𝐭𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧 𝐭𝐨 𝐋𝐚𝐫𝐠𝐞 𝐋𝐚𝐧𝐠𝐮𝐚𝐠𝐞 𝐌𝐨𝐝𝐞𝐥𝐬
👉 https://t.co/hhkeZrnG10
12. 𝐈𝐧𝐭𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧 𝐭𝐨 𝐑𝐞𝐬𝐩𝐨𝐧𝐬𝐢𝐛𝐥𝐞 𝐀𝐈.
👉 https://t.co/esVz8uBDYd
13. 𝐈𝐧𝐭𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧 𝐭𝐨 𝐈𝐦𝐚𝐠𝐞 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐨𝐧.
👉 https://t.co/9jDVP9p5id
14. 𝐂𝐫𝐞𝐚𝐭𝐞 𝐈𝐦𝐚𝐠𝐞 𝐂𝐚𝐩𝐭𝐢𝐨𝐧𝐢𝐧𝐠 𝐌𝐨𝐝𝐞𝐥𝐬.
👉 https://t.co/zb7ciYQQUR
15. 𝐈𝐧𝐭𝐫𝐨𝐝𝐮𝐜𝐭𝐢𝐨𝐧 𝐭𝐨 𝐆𝐞𝐧𝐞𝐫𝐚𝐭𝐢𝐯𝐞 𝐀𝐈 𝐒𝐭𝐮𝐝𝐢𝐨.
👉 https://t.co/ijF3RbCSqh
16. Microsoft Power BI Data Analyst Professional Certificate
👉 https://t.co/2SOFInYTnZ
17. Microsoft 365 Fundamentals Specialization
👉 https://t.co/A8Tjt3H7ty
18. Microsoft Cybersecurity Analyst
👉 https://t.co/hq63zWq3y5
19. Python for Data Science, AI & Development
👉 https://t.co/geZZsOhRUA
20. Successful Negotiation: Essential Strategies and Skills
👉 https://t.co/GmrloHMsQF
21. Introduction to Artificial Intelligence (AI)
👉https://t.co/rmAVyU7ZTJ
Happy Learning 🌟
-------------------------------------
If you found this post helpful:
1. Join Telegram for more Free AI Courses: https://t.co/mKUXQ8JcG4
2. Follow @manishkumar_dev for more such content.
#ai #aicourses #upskill #freecourses #microsoft
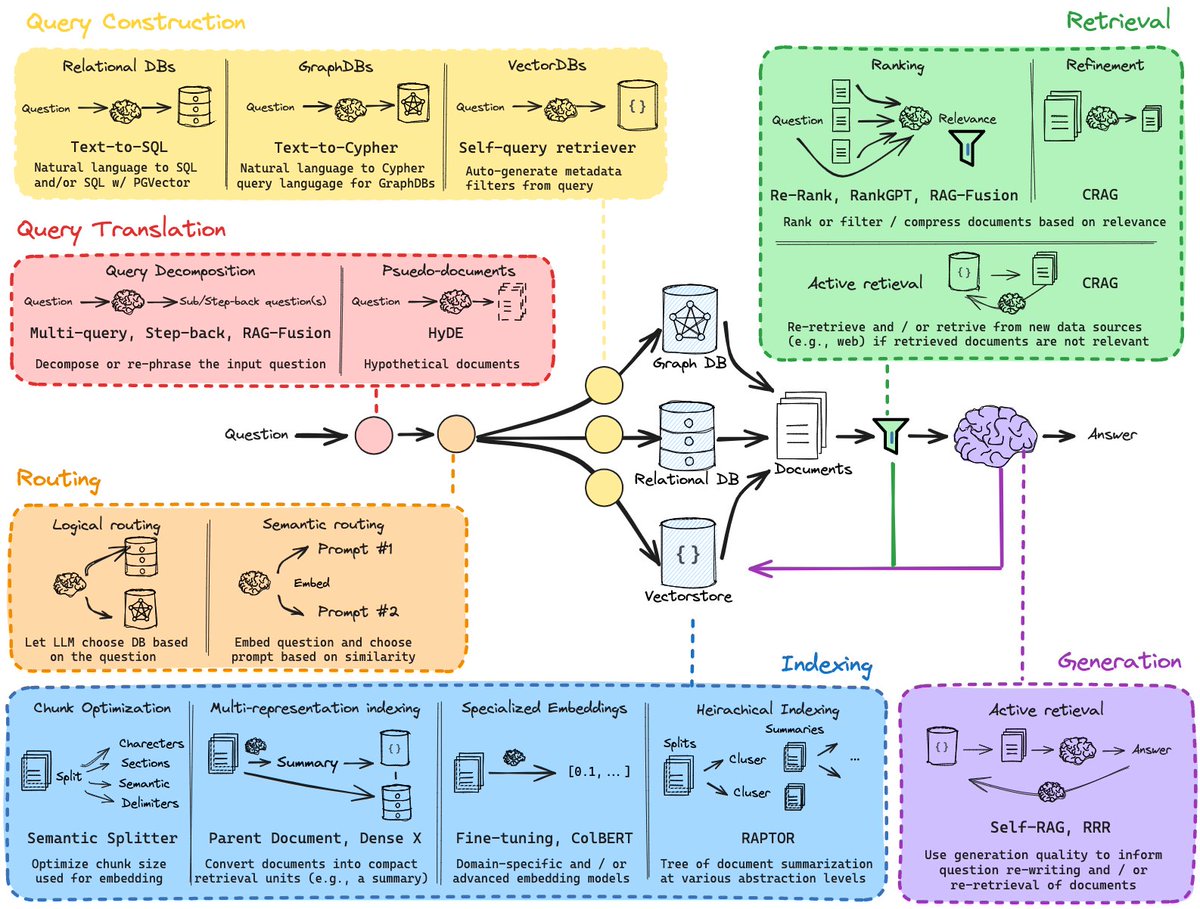
💡📚 Understanding RAG and other concepts 📚💡
Retrieval is a deep topic, and there are many strategies to improve performance.
To help guide you, @RLanceMartin has completely revamped our retrieval docs! We now categorize key strategies for retrieval into seven different categories:
Query Translation: Reviewing/rewriting inputs
Routing: Mapping incoming queries to specific data sources
Query Construction: Taking advantage of the underlying structure of a database and metadata filters
Indexing: Ingest-time strategies to improve later performance
Search methods: Considering techniques beyond vector similarity search
Post-processing: Filtering, reranking, etc.
Generation: Self-correcting and sanity checking retrieved documents
We've also updated other parts of our conceptual docs to help you more deeply understand important ideas behind building with LLMs. Check it out below, and stay tuned for more!
🐍: https://t.co/3UCyr6BbyN
☕: https://t.co/Octkn8weZE
Some of the skills you need to start building AI applications:
• Python and SQL
• Transformer and diffusion models
• LLMs and fine-tuning
• Retrieval Augmented Generation
• Vector databases
Here is one of the most comprehensive programs that you'll find online:
Building and operating a #KnowledgeGraph brings a plethora of design decisions. This article compares two methods: #RDF from the original 1990s Semantic Web research and the property graph model from the modern graph database
Your opinion?👇
https://t.co/hYAW2hKnkV
@jimwebber
1/n Similarity is Dead. Long Live Utility: A New Era for AI Knowledge Retrieval
Imagine asking a digital assistant about a complex topic, only to be bombarded with a jumble of loosely related facts, leaving you more confused than before. This frustrating scenario highlights a critical limitation of even the most advanced language models – their reliance on simple similarity when retrieving information. While finding documents with matching keywords might seem sufficient, it often leads to an overload of irrelevant data, obscuring the truly valuable insights. This paper delves into a novel approach that transcends the limitations of mere similarity, introducing a framework that equips retrieval-augmented generation with the ability to discern not just what looks relevant, but what is truly useful.
This paper identifies a crucial flaw in traditional RAG: while similarity between a user's query and a document is important, it doesn't guarantee the document's actual usefulness in answering the query. A document stating "George RR Martin is an author" might rank highly in similarity for the query "Tell me about author George RR Martin," yet it pales in comparison to a document discussing his renowned works, even if the latter scores lower in pure similarity. This over-reliance on similarity often leads to the retrieval of numerous documents with high lexical similarity but low actual utility, overwhelming the LLM and hindering its ability to generate accurate and informative responses.
To address this challenge, the paper introduces METRAG, a novel framework that moves beyond similarity-based retrieval by incorporating "multi-layered thoughts" – specifically, utility and compactness. METRAG tackles the lack of utility by introducing a "utility model" trained under the supervision of a powerful LLM. This model learns to assess the actual helpfulness of a document in answering the query, moving beyond surface-level similarity to capture the semantic essence of relevance.
Furthermore, METRAG addresses the information overload issue by incorporating a "task-adaptive summarizer." This component condenses the information from multiple retrieved documents into a concise summary, ensuring the LLM receives the most pertinent information without being bogged down by irrelevant details. This summarizer is not simply a generic tool; it is explicitly trained to retain information relevant to the specific downstream task, making it highly effective in enhancing performance.
While prior work in RAG has explored LLM-augmented retrieval and task-oriented summarization, METRAG distinguishes itself through its multi-layered approach. It doesn't simply rely on the LLM's judgment for retrieval or employ generic summarization techniques. Instead, it combines the strengths of both similarity and utility-based retrieval while utilizing a specifically trained task-adaptive summarizer, leading to more accurate, efficient, and robust knowledge-augmented generation.