Been using @comet for 2 months... By far the most superior browser out there🤯
I don't understand why more people aren't talking about it... @AravSrinivas@perplexity_ai
🧵10x your productivity with these simple shortcuts:
my prompt for aspiring founders: assume the models reach superintelligence (arguably they have already), don't kill us all, and still require us to prompt them to do things.
what are the hardest problems you can now point them at?
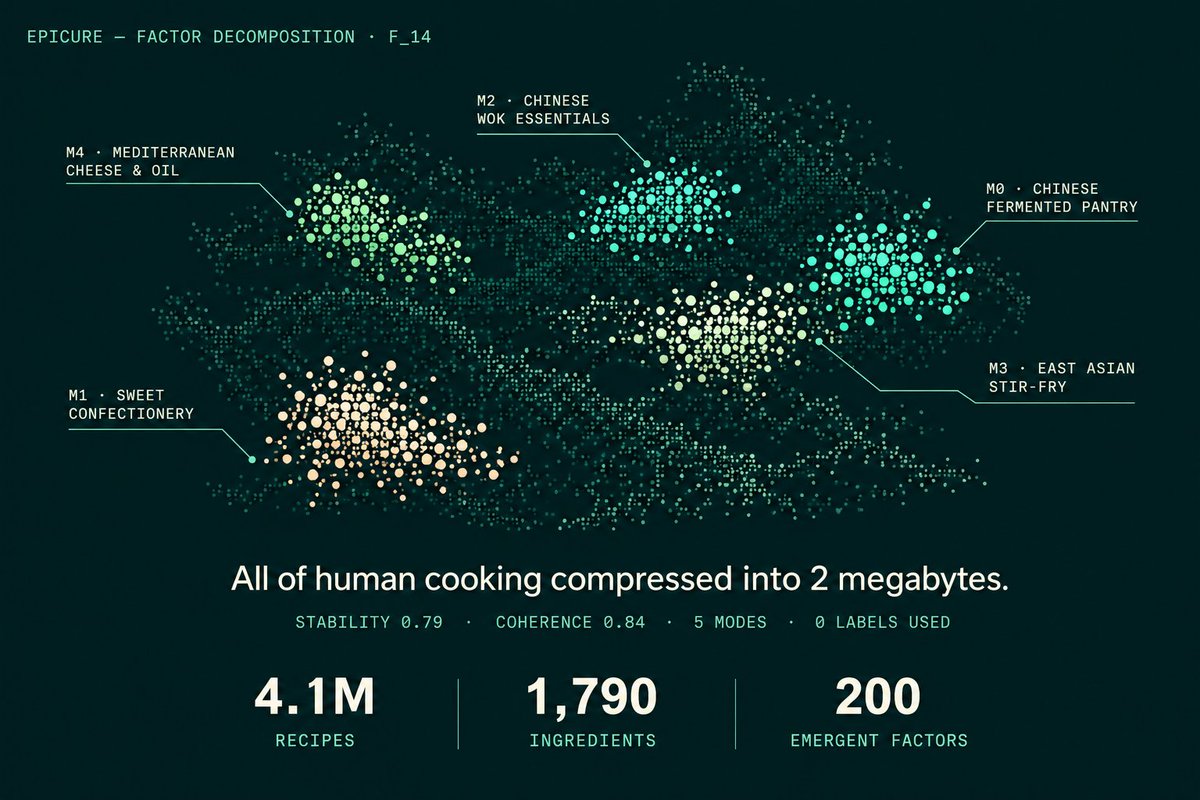
Launching our new paper on arXiv: we trained the largest multilingual food model ever built.
4.1M recipes. 7 languages. 1,790 ingredients. 300 dimensions.
All of human cooking compressed into 2 megabytes.
You’ve been buying their products.
Paying their subscriptions.
Watching their valuations climb.
USVC is how anyone can own a stake in the future that’s being built in private.
Learn more: https://t.co/kt9nVQIEdM
You would consume less computer credits (and be able to run more tasks as a result) if you switched to GPT-5.5 as your default orchestrator. This was the number one complaint about Computer (being credits/token hungry). GPT 5.5 is more token-efficient in subagent orchestration.
🧵Our team at @Pulse__AI has been analyzing the table extraction benchmarks the industry is converging on. Most don't reflect how these systems get used in enterprise workflows, and in some cases the ground truth itself has issues that change how you'd interpret the leaderboard.
The full analysis with examples is in the comments. One specific benchmark worth diving into deeper:
We audited all 1,000 RD-TableBench ground truth files against their source images. 43 (4.3%) contain verifiable errors across three categories: scrambled text or wrong structure (28), garbled OCR including watermark bleed and hallucinated characters (13), and buffer artifacts with random digit sequences attached to real numeric values (2).
On top of that, 89 of the 1,000 ground truth files are byte-for-byte identical to a single provider output shipped in the same dataset. In 15 of the 43 error cases, the ground truth and this provider share the exact same specific error while independent providers do not. Column headers in the same wrong word order ('tropical forest Arid scrub' instead of 'Arid tropical scrub forest'). Watermark text like pulled into cell content in both, and identical garbled character sequences on CJK samples.
Benchmarks are becoming the basis for how document intelligence is being measured, and ground truth quality is the foundation they rest on. We think it's worth the community being able to evaluate that alongside the numbers.