90% of all people have no idea how technology works.
It’s our moral and ethical obligation as Software Engineers to be transparent about risks instead of bullshitting the advantages.
I've got an agent in a loop optimizing a renderer with the goal to minimize frame times (and tests to measure). It got times down from 88ms to 2ms and allocations down from ~150K to 500. Sounds good, right? Wrong. This is exactly why agent psychosis is a big fucking problem.
As an experiment, I rewrote the Ghostty core render state in Go, with access to identically laid out data structures as Ghostty and the exact same validation tests. I made a purposely naive renderer (simple, correct, but slow). 88ms per frame with 150,000 allocations (horrendous, lol)!
I then kickstarted a Ralph loop to bring the frame times down. I told it it can't modify input data structures or the public API or tests (they're correct), but it can do anything else it wants. It got to work.
It has worked for about 4 hours. I've spent around $350 on this experiment so far. The results?
88ms => 1.5ms
150K allocs => ~500 allocs
Incredible right? Nope.
My hand-written renderer I ported has frame times (same benchmark) of ~20us (0.020ms) and 0 allocations in the update path.
This is the problem with psychosis and lacking systems understanding. If you don't understand the system, you're going to accept that this is an incredible result. If you understand the system, you'll see better solutions immediately and can do roughly 75x better on throughput.
The people who blindly trust agent output are in the former camp. They're sheeple, overdrinking from a fountain of mediocrity.
Standard disclaimer: I use AI all the time. I like AI. The point I'm making is to not blindly accept results. Think. Analyze. Learn.
AI has successfully made it harder and more expensive to create digital art for your business, because when you go to shop for an artist, you have to wade through the 95% of the "maker profiles" that are full-on slop cannons pretending to be human
One of the biggest problems with using LLMs as a google replacement for programming, is that getting zero relevant results on google used to be a signal that you had the wrong idea about the root cause. Whereas LLMs will happily indulge any terrible idea you suggest.
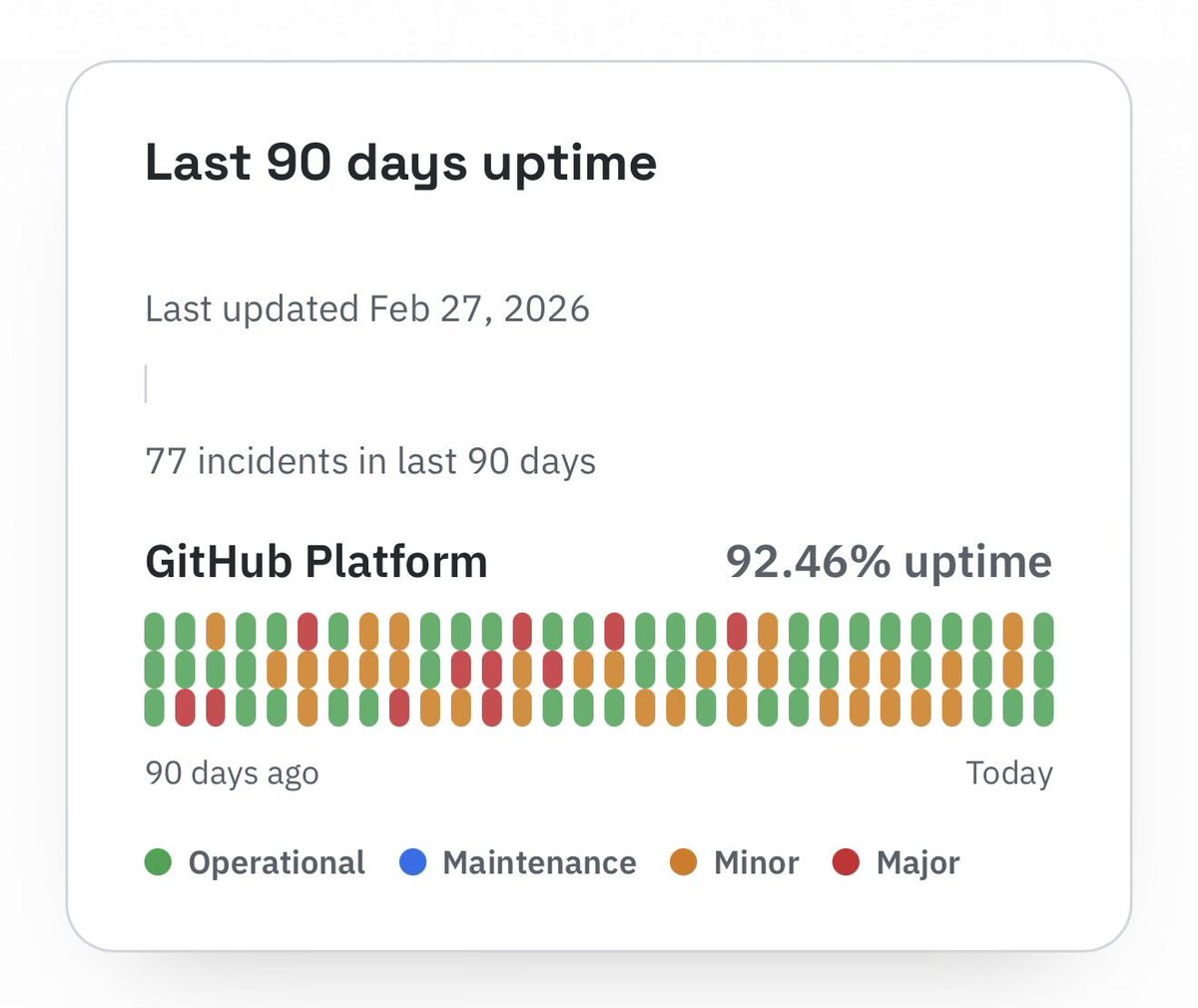
To be a little less vague, I suspect that we're likely (not certain, but likely) to be entering into a period of unprecedented software degradation, and we're going to be seeing an increasing frequency of outages like this across many high profile products.
But IMO the cause is actually not just the-one-thing-that-everyone-is-always-talking-about, it's a number of things that have all been bubbling away at just below critical levels for a long time. Some of the things off the top of my head:
- Poorly designed / optimised software has been getting a free ride on hardware improvements pretty much since the invention of the computer. That chapter is now coming to an end, and will only be worsened by the enormous industry-wide pivot to producing & innovating on AI specific hardware, rather than general purpose CPUs etc.
- The ZIRP era created a temporary suspension of reality in our industry, and now that it's ended we need to deal with the hangover. Companies that spent years making no profit, paying extravagant compensation to employees / shareholders and giving away server time for free are now pivoting into extraction mode, which is putting further pressure on their low quality software. QA is being laid off, hardware budgets are being reduced, timelines for shipping features are becoming more aggressive, etc.
- The enormous amount of free money incentivised too many new people to join the industry too quickly. This has led to an abundance of poor quality education programs (bootcamps, uncertified colleges etc) and an influx of people into the industry who frankly aren't interested in programming. If you compared the average person in the industry now to 20 years ago, I suspect the difference in motivations would be stark. I'm not saying it's these people's fault necessarily, it's simply an inevitable result of the absurd compensation / performance expectations ratio that our industry has enjoyed for the last 15+ years. Working for a tech company has also become socially prestigious, which further adds to the problem.
- Because computer programming was once an incredibly niche area of interest, many of our fundamental systems are built on trust. We're now starting to see that if systems like open source, public supply chain, discussion spaces, education etc become flooded with bad actors, we have no real mechanisms to deal with them.
- Our hiring / recruitment pipeline has totally misaligned incentives. Even before the AI resume / AI HR-filtering arms race disaster that we're experiencing now, the widespread adoption of the leetcode style interviews IMO selected for a very narrow personality type, and filtered candidates that would have made great contributions to the industry long term.
- The pivot from purchasing long term stable releases of software, to paying a subscription for constantly updating software has done huge damage to software quality as a whole. Companies have lost their incentive to get their software "right" because they can just "fix it later", and for the consumer - you can't just go back to the version of github that still works because the new one has problems.
This was all happening well before AI entered the picture. I won't belabor the point because there has been endless discussion about it. But to me personally, there are two additional and deeply worrying problems with AI code generation.
- It's undeniable at this point that it negatively affects the people who use it. It stops juniors from getting better, and it burns seniors out and makes them hate their jobs. Like it or not, humans are still the core of this industry, and I don't see this ending well.
- It's completely unfit for purpose in the most important, high-stakes situations. One of the reasons that we excuse all the small errors it makes, is because it's low effort to type "do it again and fix this bug". That kind of thing doesn't fly when you only get one attempt because a mistake results in data loss or an outage. The damage is done.
All the above has led to a silent exodus of many of our most experienced and impactful people. There are so many amazing programmers who made enough through stock options / compensation that they didn't need to work anymore, and were only doing it because they enjoyed it. Many of these people have just quit the industry and switched to doing hobby projects in the last 5 years. These are the types of people who have the experience and foresight to prevent the types of outages that we're seeing at github today.
It's very easy to assume that the proverbial straw that broke the camel's back is entirely to blame here. But I think it's a reckoning that has been on the horizon for a very long time.
We all knew this was coming… but today I heard about it actually happening.
A seed stage company backed by a well known VC openly admitted (in a board deck) that their strategy is to get access to a large incumbent’s software from a customer, clone the entire thing using Claude Code, and offer it at 90% less.
Not “build something better.” Just copy it and offer it for less.
The VC endorsed this as the GTM strategy. And even wrote back in writing that it was a good idea.
Using a customer’s licensed access to reverse engineer a product and clone it is ethically bankrupt. I don’t know how else to put it.
It likely violates terms of service. It may violate trade secret law as well (but I’m certainly not a lawyer).
And a reputable VC putting this in writing in a board deck is genuinely insane.
But it’s going to happen anyway.
Everywhere… all the time.
I don’t know where this ends, but we all knew this was coming and now it’s here.
Pocket (@Heypocket) sold 30,000 units in 5 months recording doctor visits, legal calls, and board meetings. So I did my due diligence like I always do.
Their Google Play listing says "No data collected."
Their own privacy policy lists audio recordings, transcripts, device IDs, ad identifiers, cookies, IP location, and behavioral inferences.
One of those is wrong.
They brand themselves "open source".
Their GitHub org (https://t.co/I7cdDBIHIO) contains exactly 4 repositories:
- Raspberry Pi Zero prototype called icecream-project [from the CEO's prior Omi work],
- FFmpeg Flutter fork,
- docs repo,
- org profile page.
The actual Pocket device firmware, mobile app, backend infrastructure, and audio processing pipeline are NOT here.
There is NO Pocket source code to audit.
Recordings go to unnamed "cloud/AI vendors" with no disclosure of which LLMs process your audio, what jurisdiction they operate in, or how long they retain it. Users can't choose their provider or bring their own keys.
If you cancel your $19.99/month subscription, your recordings get processed by whichever default model Pocket selects.
The contact mic is marketed for recording phone calls without speakerphone.
In 11+ US states including California (where Pocket is based) -- that requires all party consent. The device has NO consent mechanism.
Their terms cap liability at the amount you've paid or $100 (whichever is greater) - for data breaches involving your medical appointments, legal consultations, and proprietary meetings.
A third‑party LobeHub skill has already reverse‑engineered Pocket’s web API and can pull recordings, transcripts, summaries, and action items using short‑lived Firebase bearer tokens extracted from the user’s browser session.
Their privacy policy confirms that if Pocket is acquired -- every recording, transcript, and summary transfers to the buyer.