we've been waiting for someone to do this since late 2024, when we switched away from hertz-dev and our audio work! huge congrats to our friends at thinky :)
Today we're sharing our work on interaction models. A new class of model trained from scratch to handle real-time interaction natively, instead of gluing it onto a turn-based one.
https://t.co/MoS5s4cm60
Back when we were raising our seed round, Lachy was one of the only people in Silicon Valley who saw our idea, immediately got it, and wrote the check that let us train FDM-1.
Incredibly grateful to have him as an early supporter.
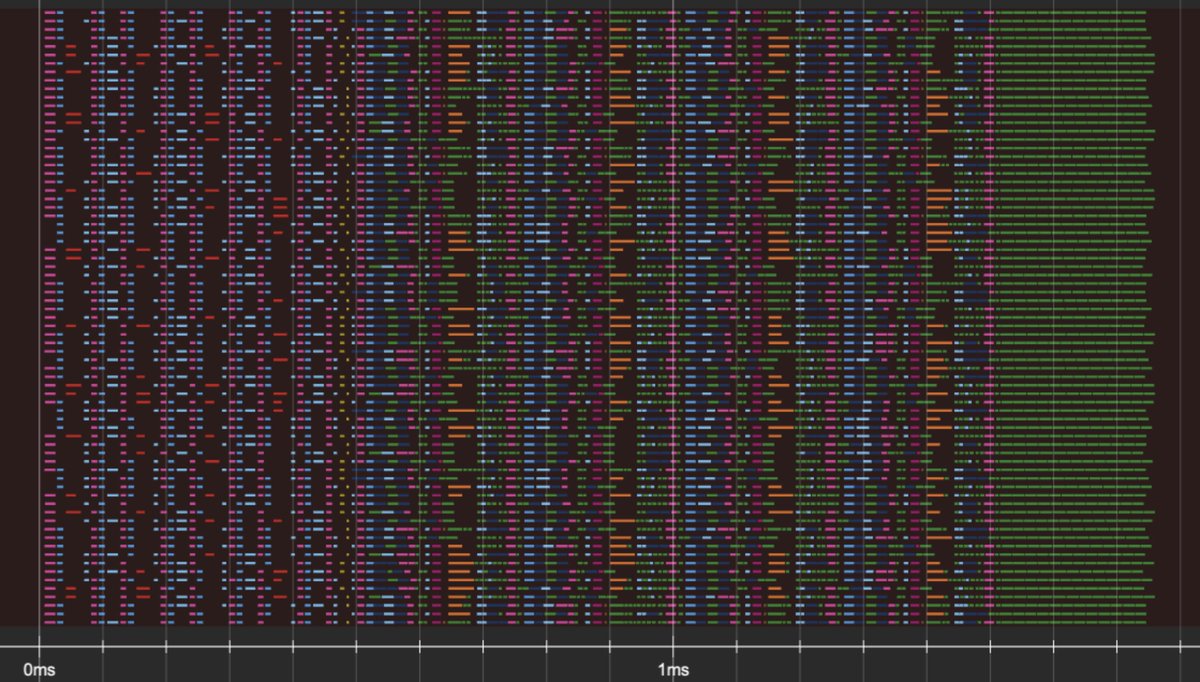
(4/5) One thing we’ve built is a “kittens” virtual machine that takes over the whole GPU and allows new kinds of co-optimization. We can go past the traditional sequential kernel model – for example, fusing entire training runs into a single kernel and even weirder stuff.
.@devanshpandey and Galen are exceptional. Proud to be a small angel on this journey and watch them blow up.
@mcannonbrookes@scottfarkas there is are more than a few interesting partnership angles here.
Lachy called me up on thanksgiving day back in 2024 to offer to lead our seed round. At the time we had a few weeks of runway left and no one else had the conviction for a research bet. He's an incredibly impressive investor and an amazing person.
@si_pbc@sonyatweetybird@MikowaiA@YasminRazavi@tszzl@_milankovac_ VPT (https://t.co/CSxHcXY6Vh) blew my mind back in 2022 so I was very excited to see SI scale up the idea with FDM1, but for knowledge work / computer use. Excited and looking forward to more!
Instead of predicting text tokens, @si_pbc learns to use a computer from raw screen data, predicting the next mouse movement, click, and keystroke from the pixels in front of it.
This is the @Tesla FSD approach applied to knowledge work on computer screens.
Excited to have not one but two @Tesla_AI goats @_milankovac_ and @karpathy join us on the cap table!
@G413N and @devanshpandey and the @si_pbc team have been quietly building on the frontier of a new pre-training paradigm: foundation models that learn from raw video, not language and screenshots. FDM-1, their first model, an 11M-hour computer-action dataset (the largest in the industry), a video encoder ~50x more token-efficient than the alternatives, and a 30-petabyte cluster racked in SF for under $500K. FDM-1, their first model, already extrudes CAD gears in Blender, fuzzes software, and drives a real car around San Francisco after an hour of fine-tuning.
We at @sparkcapital could not be more thrilled to partner with them, alongside @sonyatweetybird and the @sequoia team.
New from me this morning: standard intelligence has raised $75m @ $500m to develop computer use models
Their hypothesis is that video pretraining gives a better action prior than text and screenshots ➡️ continual learning
And their training runs are very brat
We’ve raised 75m in new funding from Sequoia and Spark Capital—partnering with @sonyatweetybird, @MikowaiA, and @YasminRazavi, all of whom are deeply supportive of our long-term mission. We’ve also brought on angels & advisors including @karpathy, @tszzl, and @_milankovac_.
-----
Our early results with FDM-1 moved computer use from a data-constrained regime to a compute-constrained one; this latest round of funding unlocks several orders of magnitude of compute scaling for that work. With the FDM model series we have a path to scale agentic capabilities through video pretraining, and we expect to achieve superhuman performance on general computer tasks in the same way that current language models have superhuman performance on coding tasks.
We’re also now able to invest in the blue-sky research necessary to our long term mission of building aligned general learners. To realize the civilizationally transformative impacts of AI, models must generalize far out of their training distributions, actively exploring and building skills in new environments. This capability represents a substantial shift from the current paradigm of model training. We believe that current alignment techniques are insufficient to predictably and safely steer a model with human-level learning capabilities, and so we’re doing work to study small versions of this problem in controlled environments to develop a science of alignment for general learners.
We’re a team of 6 people in San Francisco. We’re hiring world-class researchers and engineers to help us achieve our mission. If that’s you, please get in touch.
Create gummies was sued in a false advertising class action today.
The plaintiff says Create advertises that each 3-gummy serving contains 4.5g of creatine, but testing shows that the products contain about 10% less than that.
At this point the board of supervisors @sfbos has held multiple hearings about Waymo while human drivers continue to vaporize pedestrians with impunity.