Linked Sasha's excellent video lecture (and tweet by Dwarkesh) at https://t.co/ghXnEtkCaK so more people can better understand how on-policy distillation works
What is mid-training?
The stage between pre-training and post-training
A base model is continued on a smaller, curated data mixture chosen to strengthen capabilities that the original pre-training run undercovered, such as multilinguality, domain knowledge, or long-context extension.
It usually keeps a pre-training-like objective, but uses higher-quality or more targeted data so later instruction tuning, preference tuning, or RL can shape behavior on top of stronger capabilities.
Learn more here: https://t.co/WhpYkyGlv8
Do NOT use Sci-Hub, the evil website that pirated 88M+ research papers.
It also integrates with Zotero.
We must make billion-dollar, for-profit, academic publishers richer.
Below is a step-by-step tutorial on how to add Sci-Hub to Zotero, so you know how to avoid it:
🏹 Day 3 of the 5 Days of Trajectory!
We are open sourcing a training stack for continual learning, in collaboration with SkyRL (@NovaSkyAI) and Anyscale (@anyscalecompute)
At Trajectory, our mission is to bring the capability of continual learning to every team and company.
Our contribution today is a multi-tenant, continual LoRA (C-LoRA) training stack that is built for workloads that are repeatedly spinning up and down.
Links to get started below!
🏹5 Days of Trajectory.
Day 3 - An Open Source Training Stack for Continual Learning
Building the platform for continual learning requires both partnering with pioneering AI companies, as we showed on Day 2 with Harvey, and working toward frontier research, which we are highlighting today.
Continual learning means models that improve hourly from real production use. But with the size of frontier models, this becomes quite difficult. A Qwen-397b would need to spin up and tear down repeatedly across six GPU nodes, and that's valuable time gone.
Our contribution is Continual LoRA (C-LoRA): many lightweight adapters running at once on one shared base model. Our insight centers on where the parallelism lives: instead of splitting one giant job across nodes, we load-balance many small jobs over a single base.
The result: 2.81x experiment throughput over single-tenant training, with no regression on rewards.
We built this together, with @anyscalecompute, @NovaSkyAI, and generous support from @GoogleCloud and @GoogleStartups. We've open-sourced on SkyRL as one of the first multi-LoRA, RL training platforms, so that every team can get to continual learning faster.
We’re very excited to see what you build, please reach out!
Training an LLM from scratch is easier to study when the whole path is in one repo.
Train LLM From Scratch is a PyTorch repository for learning how a transformer language model is built, trained, saved, and used for text generation.
It helps you move from “I understand attention on paper” to a runnable training pipeline by pairing model code with data download, preprocessing, config, training, and generation scripts.
Key features:
• Transformer components from scratch – separate PyTorch modules for MLP, attention, transformer blocks, and the final model
• Pile-based data path – scripts download The Pile files and preprocess JSONL.ZST text into tokenized HDF5 datasets
• Configurable training setup – model size, context length, heads, blocks, batch size, learning rate, and file paths live in https://t.co/zuPqaR3MhP
• Hardware guidance – README compares common GPUs for 13M and 2B-class training runs
• Generation workflow included – generate_text.py loads trained checkpoints and produces sample text outputs
It’s open-source (MIT license).
Link in the reply 👇
Step 3.7 Flash is here
ICYMI: 198B MoE with 11B active params, 256K context, native image + video support.
Day 0 support is live on https://t.co/6T0R9P778k with GPU-accelerated endpoints, deploy with NVIDIA NIM inference microservices, and fine-tune with the NVIDIA NeMo framework.
Congrats to the @stepfun_ai team!
This is a great read on post-training and open models.
@harvey & @trajectorylabs post-trained Nemotron 3 Super on complex legal tasks with some very impressive initial results. All with auditable weights, real security, and clear provenance.
Our posting for joining Google DeepMind as a Research Scientist was down for a few days but now it is back up!
Apply here: https://t.co/Yk5iMbMQPu
And fill out this form: https://t.co/zdeqryH3hB
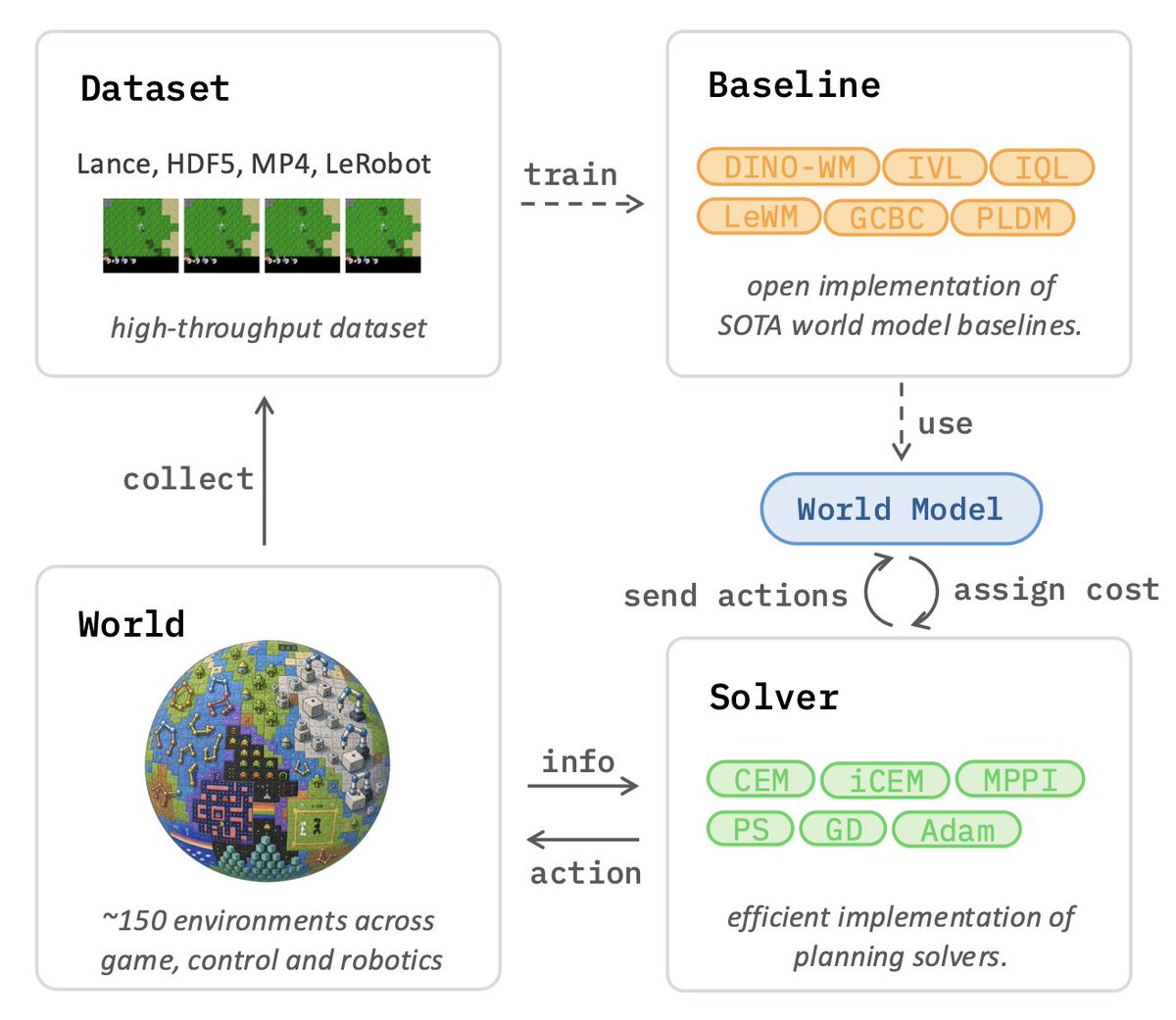
Would you like to join the research effort on JEPA and World Models easily?
After a full year of hard work, we’re excited to finally release stable-worldmodel:
an open-source, scalable platform built to accelerate JEPA & World Model research!
📄: https://t.co/gnxGvens5A
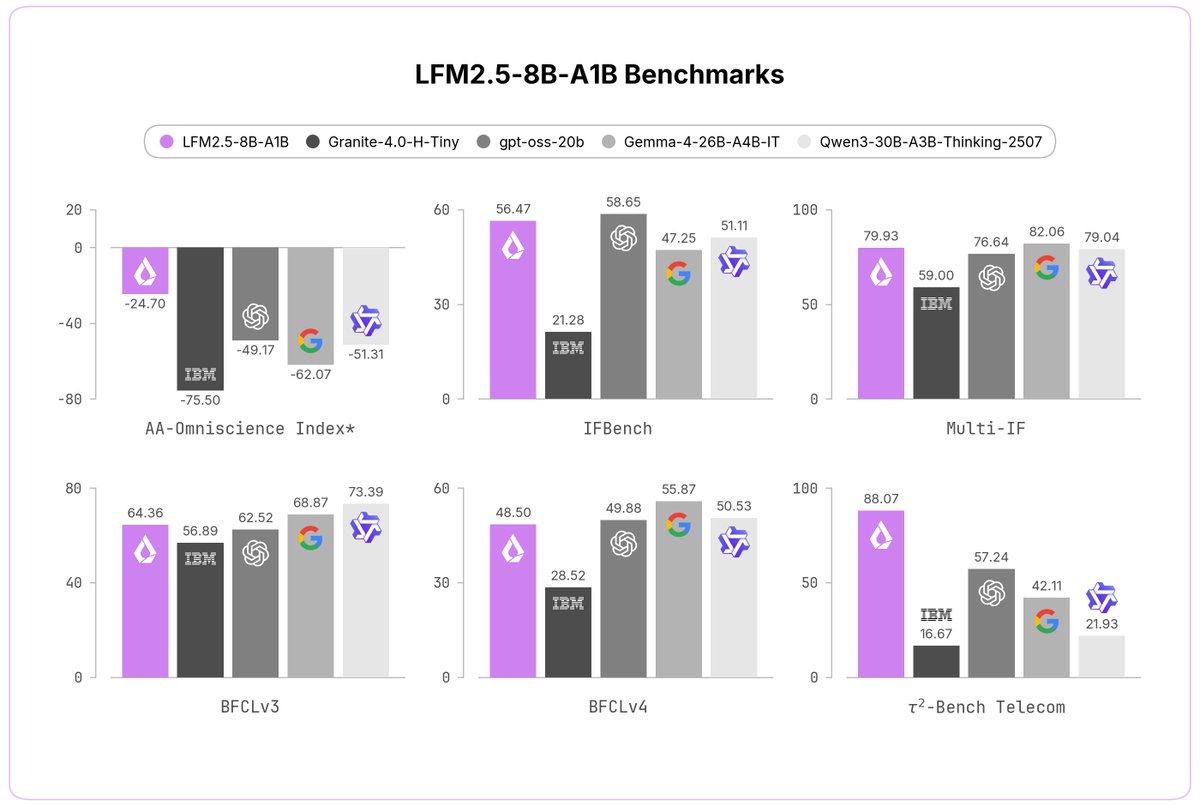
Today, we're releasing LFM2.5-8B-A1B, a device-optimized model designed to power real-life applications on phones, laptops, PCs, robots, and fast & lightweight server-side use-cases.
> 8B MoE, 1.5B active
> Expanded 128K context
> LFM2.5 flagship hybrid MoE architecture
> Trained on 38T tokens + large-scale RL
> fast, reliable tool calling, punching above its weight, comparable to models with up to 4x its size
> customizable on a single GPU for any specialized task
> LFM2 open-weight license
🧵
This is something I wanted to study long since I ever read the original knowledge distillation paper in 2015.
Finally we've done it - with @TaiMingLu we thoroughly study the necessity of distillation from a "stronger" teacher
(1/6) Interpretability research is often accused of being insightful but not actionable.
We ask a different question: can SAE representations directly guide LLM post-training data engineering?
Paper: https://t.co/pVmDmS5Sg7 🧵👇