Santander acoge este fin de semana una oportunidad perfecta para quienes tienen dudas sobre dar el salto al coche eléctrico.
Porque hay una pregunta que solo tiene una forma de responderse:
¿Me compraría este coche?
Y la respuesta no está en YouTube.
Ni en los foros.
Está detrás del volante.
+ 30 vehículos eléctricos disponibles para pruebas gratuitas en #ElectricGoSantander.
📍 Campos de Sport de El Sardinero (Santander)
📅 12, 13 y 14 de junio
👉 Plazas limitadas, reserva en https://t.co/M6J98s1O4f #publi
A teenager in the United States started publishing software at 14 in 1998, built the entire online infrastructure for the Occupy Wall Street movement in 2011, joined Google as a software engineer, quit in 2018, and then spent five years writing a C library that does something the entire industry said was impossible.
Then she combined it with llama.cpp and shipped the easiest way on the planet to run a large language model on any computer.
Her name is Justine Tunney.
Here is the story, because almost nobody outside the low level systems world knows what one engineer has built.
Justine was born in 1984. She started writing and publishing software at 14, back when distribution meant uploading binaries to BBS systems and chat networks. She picked up the handle jart, which she still uses on GitHub today. She did the work most teenagers her age were not doing. She read the systems programming literature. She studied compilers. She fell in love with C.
In July 2011 she registered the @occupywallst Twitter handle and the occupywallst dot org domain. Within weeks the protest movement that began in Zuccotti Park in New York had become a global phenomenon, and her infrastructure was the digital backbone of the entire thing. She handled the social media, the website, the donations, the coordination. She built the platform that pushed the movement to reach millions.
After Occupy she joined Google as a software engineer. She worked on TensorBoard, the visualization tool for TensorFlow, and on site reliability for Google infrastructure. She stayed for years. Then in 2018 she left Google Brain to work on a personal project.
The project was called Cosmopolitan Libc.
Cosmopolitan does something most C programmers would tell you is mathematically impossible. It lets you compile a C program once and have the resulting binary run natively on Linux, Windows, macOS, FreeBSD, OpenBSD, and NetBSD with no modification. One file. Six operating systems. No virtual machines. No interpreters. No recompilation. The technique she invented is called Actually Portable Executable.
The implications are wild. Cosmopolitan binaries violate every assumption about how operating systems load programs. They are at once a Windows PE file, a Linux ELF binary, a macOS Mach-O binary, and a shell script. The same bytes run on every platform.
For five years she worked on it mostly alone. She funded the development partly through Mozilla's MIECO program, which sponsored her work on Cosmopolitan 3.0, released on October 31, 2023.
A month later she shipped llamafile.
llamafile is what happens when you combine Cosmopolitan with llama.cpp. You take any LLM weights file in the standard GGUF format, you wrap it in Justine's binary, and you get a single file that runs on six operating systems without installation. No Python. No CUDA setup. No dependency hell. Just one file that you double click and it works.
Mozilla launched it as an official project of their innovation group on November 29, 2023. It went viral immediately. The repository, hosted at github .com/mozilla-ai/llamafile, now has 24,600 stars. The license is Apache 2.0.
Justine kept shipping. She added GPU support to Cosmopolitan, a task systems engineers thought would require rewriting the whole thing. She added dlopen support, another thing nobody else had figured out. She wrote whisperfile, a single file version of OpenAI's Whisper speech-to-text model based on the same architecture.
Her GitHub profile lists projects most engineers would consider impossible. sectorlisp, a Lisp interpreter that fits in a boot sector. blink, the tiniest x86-64-linux emulator on Earth. bestline, a teletypewriter command session library. redbean, a complete web server inside a single zip file.
A teenager who shipped software in 1998 grew up to write the C library that the entire local AI movement now runs on top of.
She did most of it alone, and most people scrolling AI Twitter cannot name her.
The expensive part of software is rarely the code.
It is the unclear scope, the wrong assumptions and the cleanup after everyone pretended they were aligned.
𝗪𝗵𝗮𝘁 𝗶𝘀 𝘆𝗼𝘂𝗿 𝗱𝗲𝘃𝗲𝗹𝗼𝗽𝗲𝗿 𝗮𝗿𝗰𝗵𝗲𝘁𝘆𝗽𝗲?
I've managed engineering teams for over 20 years. The most problematic engineers are the ones doing work that doesn't match who they are.
Many times, I saw a builder forced into a tech lead role, and sometimes a deep specialist pressured to be a generalist. A product-minded engineer stuck on a team that only values raw output (hello AI). 🧵
Cómo confirmar que no tienes ni idea de cómo funcionan las redes sin decirlo explícitamente: by LaLiga. Estudiad como funciona un proxy inverso y entenderéis la tontería de nota informativa que acabáis de soltar (o no, yo ya no sé)...
🚨 NOTA INFORMATIVA
En relación con la información publicada por ADSLZone, que vincula los sistemas antipiratería de LALIGA con el supuesto fallo de un dispositivo de localización personal, LALIGA desmiente categóricamente dicha afirmación.
Tras las comprobaciones técnicas realizadas, no existe evidencia alguna de que las direcciones IP asociadas a la aplicación mencionada hayan sido bloqueadas por los sistemas de LALIGA por actividades relacionadas con la distribución ilegal de contenidos.
🔗https://t.co/fatZxwlxAh
Whoever uses AI to write code should be ultimately responsible for that code and liable for any potential consequences of running that code.
I don't care what model you used, how you used it, or how much it helped you.
Humans bear full responsibility.
Agency > Intelligence
I had this intuitively wrong for decades, I think due to a pervasive cultural veneration of intelligence, various entertainment/media, obsession with IQ etc. Agency is significantly more powerful and significantly more scarce. Are you hiring for agency? Are we educating for agency? Are you acting as if you had 10X agency?
Grok explanation is ~close:
“Agency, as a personality trait, refers to an individual's capacity to take initiative, make decisions, and exert control over their actions and environment. It’s about being proactive rather than reactive—someone with high agency doesn’t just let life happen to them; they shape it. Think of it as a blend of self-efficacy, determination, and a sense of ownership over one’s path.
People with strong agency tend to set goals and pursue them with confidence, even in the face of obstacles. They’re the type to say, “I’ll figure it out,” and then actually do it. On the flip side, someone low in agency might feel more like a passenger in their own life, waiting for external forces—like luck, other people, or circumstances—to dictate what happens next.
It’s not quite the same as assertiveness or ambition, though it can overlap. Agency is quieter, more internal—it’s the belief that you *can* act, paired with the will to follow through. Psychologists often tie it to concepts like locus of control: high-agency folks lean toward an internal locus, feeling they steer their fate, while low-agency folks might lean external, seeing life as something that happens *to* them.”
This is counterintuitive for some, which is why there’s a paradox named after it. But if you lower the cost of something that was previously supply constrained, demand for that thing goes up. Software engineering is just one of the easiest examples to contemplate.
The process goes like this: every small business, every IT team, every large enterprise sees that engineering can now drive vastly more output. They then start to consider all the new things they can build or automate. They even test building prototypes themselves.
They only get so far with that approach because they realize there are still 50 other tasks that go into building software and maintaining it. So they start to hire more engineers to do that work. All of this for work they never would have considered automating or having software for if AI didn’t exist.
So yes, automating tasks, in plenty of fields, will lead to demand for experts, not less.
We as software engineers are paid for solving business problems
And not for writing code.
Code is just a tool to solve these problems.
As middle developer, I measured my value by:
- How many lines of code I wrote
- How many features I have implemented
- How many bugs I have resolved
- How does my code look like
When I became a senior - I realized something:
No business cares about how elegant your code is if it doesn't solve their problem.
I have made this mistake multiple times in my career - writing code that has zero business value.
Your job as a software engineer is not to write code.
Your job is to build solutions.
A good developer writes code that works.
A great developer writes as little code as possible to solve the right problem.
When a feature launches, the business doesn't care that you refactored code beautifully.
They care that revenue increased and customers are happier.
Code quality, refactoring, and maintainability still matter.
They are what allow you to deliver value faster and safer next time.
They are the foundation.
Clean code without business impact is useless.
But business value without maintainable code is short-lived.
The most valuable devs are the ones who:
• Understand the business goal before writing a single line of code
• Communicate trade-offs clearly
• Deliver outcomes without sacrificing long-term quality
Because at the end of the day -
We are not paid to write perfect code.
We are paid to create value.
——
♻️ Repost to remind others that code is a tool
➕ Follow me ( @AntonMartyniuk ) to improve your .NET and Software Architecture Skills
Meanwhile every Uber you book, every Netflix binge, every card payment you tap - bro is silently doing the heavy lifting.
Even the platform you used for this clickbait post? Powered by bro.
Java didn’t disappear, bro. Your knowledge did.
¿Cómo sobrevive un chaval a la era digital?
Que si brainrots, algoritmos diseñados por psicópatas...
Así que hablé con educadores y padres sobre esto, que espero sirva también para padres y madres que anden perdidos en esta era que hasta a mí me cuesta muchas veces seguirle la marcha
https://t.co/aRpH762RcO
𝗔𝗣𝗜 𝗚𝗮𝘁𝗲𝘄𝗮𝘆 𝘃𝘀 𝗟𝗼𝗮𝗱 𝗕𝗮𝗹𝗮𝗻𝗰𝗲𝗿 𝘃𝘀 𝗥𝗲𝘃𝗲𝗿𝘀𝗲 𝗣𝗿𝗼𝘅𝘆
Regarding a system design, we often need clarification about the roles of a Load Balancer and an API Gateway. Most of our resources are about their implementation rather than real-life use cases.
𝗔𝗣𝗜 𝗚𝗮𝘁𝗲𝘄𝗮𝘆
It sits between a client and a group of backend services. It acts as a reverse proxy, accepting all application programming interface (API) calls, aggregating the services needed to fulfill them, and returning the appropriate results.
User authentication, rate limits, and statistics are typical duties that API gateways handle on behalf of an API service system. Also, the API gateway can handle faults (circuit breaker) and log and monitor.
𝗟𝗼𝗮𝗱 𝗕𝗮𝗹𝗮𝗻𝗰𝗲𝗿
It is a service that distributes incoming traffic across many servers or resources. Usually, we have two or more web servers on the backend, and it 𝗱𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗲𝘀 𝗻𝗲𝘁𝘄𝗼𝗿𝗸 𝘁𝗿𝗮𝗳𝗳𝗶𝗰 𝗯𝗲𝘁𝘄𝗲𝗲𝗻 𝘁𝗵𝗲𝗺.
Its primary purpose is to use resources optimally. A more equal task allocation and increased capacity can enhance the system's responsiveness and reliability.
There are three load balancers at a high level: hardware-based, cloud-based, and software-based.
𝗥𝗲𝘃𝗲𝗿𝘀𝗲 𝗣𝗿𝗼𝘅𝘆
A server sits in front of backend servers and forwards client requests to them. Reverse proxies are typically used to enhance security, performance, and reliability.
A reverse proxy receives a request from a client, forwards it to another server, and returns the response to the client, giving the impression that the first proxy server handled the request. These proxies ensure that users don't access the origin server directly, giving the web server anonymity.
They are usually used for Load balancing, where we need to handle incoming traffic so we can distribute it across multiple backend servers, or for caching.
So, the main thing that differs these two is that an 𝗔𝗣𝗜 𝗚𝗮𝘁𝗲𝘄𝗮𝘆 𝗶𝘀 𝗳𝗼𝗰𝘂𝘀𝗲𝗱 𝗼𝗻 𝗿𝗼𝘂𝘁𝗶𝗻𝗴 𝗿𝗲𝗾𝘂𝗲𝘀𝘁𝘀 to the appropriate service and it handles requests for APIs, while a 𝗟𝗼𝗮𝗱 𝗯𝗮𝗹𝗮𝗻𝗰𝗲𝗿 𝗶𝘀 𝗳𝗼𝗰𝘂𝘀𝗲𝗱 𝗼𝗻 𝗱𝗶𝘀𝘁𝗿𝗶𝗯𝘂𝘁𝗶𝗻𝗴 𝗿𝗲𝗾𝘂𝗲𝘀𝘁𝘀 𝗲𝘃𝗲𝗻𝗹𝘆 between a group of servers and handles requests that are sent to a single IP address, which works at protocol or socket level (TCP, HTTP).
Some 𝗲𝘅𝗮𝗺𝗽𝗹𝗲𝘀 of API Gateways are Amazon API Gateway, Ocelot (.NET-based), Tyk, or Apache APISIX, while Load Balancers are Azure Load Balancer, HAProxy, or Seesaw.
An example of reverse proxy services is 𝗔𝗽𝗮𝗰𝗵𝗲 𝗣𝗿𝗼𝘅𝘆, 𝗡𝗴𝗶𝗻𝘅 𝗼𝗿 𝗜𝗜𝗦 with additional modules (Url Rewrite).
I recently received an email titled “An 18-year-old’s dilemma: Too late to contribute to AI?” Its author, who gave me permission to share this, is preparing for college. He is worried that by the time he graduates, AI will be so good there’s no meaningful work left for him to do to contribute to humanity, and he will just live on Universal Basic Income (UBI). I wrote back to reassure him that there will still be plenty of work he can do for decades hence, and encouraged him to work hard and learn to build with AI. But this conversation struck me as an example of how harmful hype about AI is.
Yes, AI is amazingly intelligent, and I’m thrilled to be using it every day to build things I couldn’t have built a year ago. At the same time, AI is still incredibly dumb, and I would not trust a frontier LLM by itself to prioritize my calendar, carry out resumé screening, or choose what to order for lunch — tasks that businesses routinely ask junior personnel to do.
Yes, we can build AI software to do these tasks. For example, after a lot of customization work, one of my teams now has a decent AI resumé screening assistant. But the point is it took a lot of customization.
Even though LLMs can handle a much more general set of tasks than previous iterations of AI technology, compared to what humans can do, they are still highly specialized. They’re much better at working with text than other modalities, still require lots of custom engineering to get it the right context for a particular application, and we have few tools — and only inefficient ones — for getting our systems to learn from feedback and repeated exposure to a specific task (such as screening resumés for a particular role).
AI has stark limitations, and despite rapid improvements, it will remain limited compared to humans for a long time.
AI is amazing, but it has unfortunately been hyped up to be even more amazing than it is. A pernicious aspect of hype is that it often contains an element of truth, but not to the degree of the hype. This makes it difficult for nontechnical people to discern where the truth really is. Modern AI is a general purpose technology that is enabling many applications, but AI that can do any intellectual tasks that a human can (a popular definition for AGI) is still decades away or longer. This nuanced message that AI is general, but not that general, often is lost in the noise of today's media environment.
Similarly, the progress of frontier models is amazing! But not so amazing that they’ll be able to do everything under the sun without a lot of customization. I know VC investors who are scared to invest in application-layer startups because they are worried that frontier AI model companies will quickly wipe out all of these businesses by improving their models. While some thin wrappers around LLMs no doubt will be replaced, there also remains a huge set of valuable applications that the current trajectory of progress of frontier models won’t displace for a long time.
Without accurate information about the current state of AI and how it is likely to progress, some young people will decide not to enter AI because think think AGI leaves them no meaningful role, or decide not to learn how to code because they fear AI will automate it — right when it is the best time ever to join our field.
Let us all keep working to get to a precise understanding of what’s actually possible, and keep building!
[Original text: https://t.co/OfxCVPGKoq ]
If you ever played Space Invaders you surely noticed that each time you killed an alien the game went faster.
But, if you checked the source code from one of the arcade machines, you would find nothing related to this. That's because this mechanic is a hardware accident.
The Intel 8080 CPU had to update every alien. Our machines would do it extremely fast (in fact, it would be impossible to play the original game with current power), but changing the position, redrawing the sprites and checking for collisions for each one of the 55 aliens was really expensive.
That's why the game starts slowly, but gets faster, simply because each time you kill an alien, there are less resources to manage. And... people loved this! A simple side effect became an iconic mechanic.
The source code (not original one, copyright held by Taito Corporation): https://t.co/rOPAbvMvh9
You can also read about the Intel 8080 here: https://t.co/RMWSFgwBSu
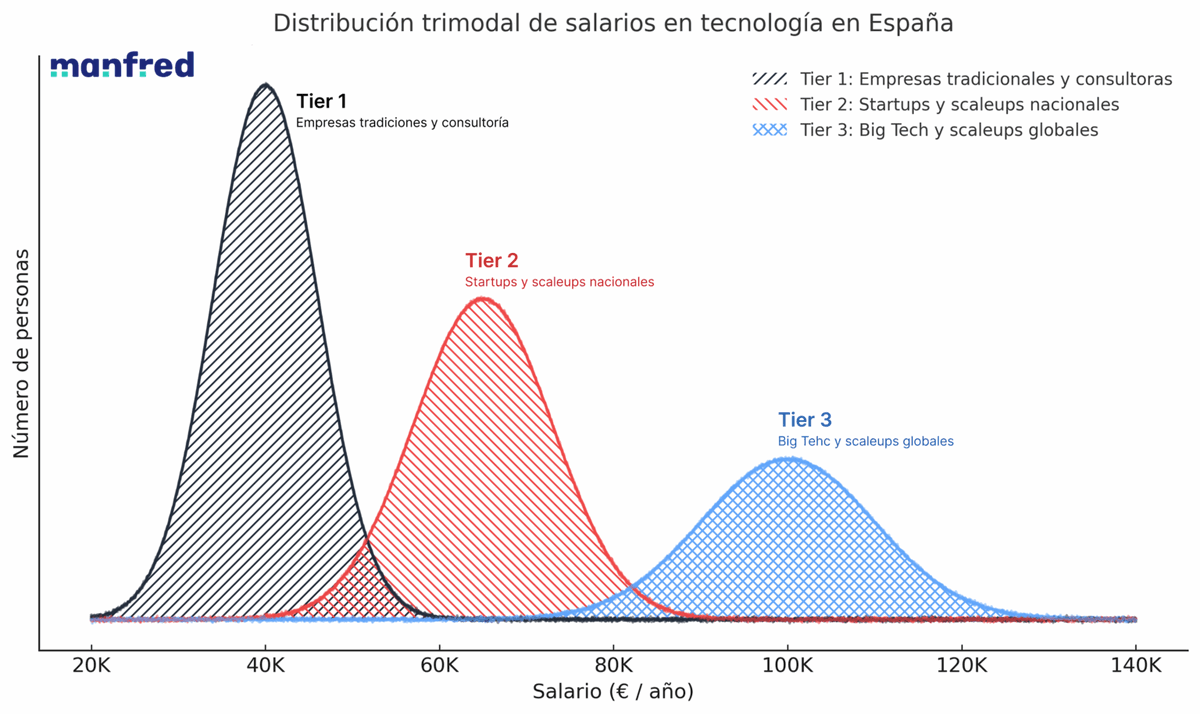
En España, un ingeniero o ingeniera de software puede cobrar 35.000€ o 130.000€.
🤷♂️Mismo rol, distinta empresa, distinto salario🌍💶
¿Por qué pasa esto?
Porque el mercado tech tiene tres ligas/ tiers salariales.
Abro hilo explicando con ejemplos 👇
@lemire b4 I started in business
I thought engineering-burnout
had to do with constantly being faced with
hard engineering problems & cracking under pressure
doing business realized I craved hard engineering problems &
was burned out by meetings/politics/lies/backstabbing/profitteers
A must for every programmer:
• Basic data structures
• Sorting and searching
• Graphs and trees
• Approximation algorithms
• Dynamic programming
• Complexity analysis
You don't need to know Dijkstra's algorithm to write better CSS or HTML. But nothing will teach you more about computers, abstractions, and software engineering than looking at the foundation of how systems work.
And this is important. Today, more than ever.
In the future, coding may become a thing of the past. It'll become a hobby for nerds and nostalgic people, but it'll be hard to make any money writing code alone.
But building software is as much about writing code as watching a movie is about the process of buying a TV.
Building software is about problem-solving and thinking. Good software developers understand that code doesn't matter. It's a means to an end, nothing more.
Coding may not be here for long, but the future of building software is as bright as it's ever been.
Awesome & wholesome:
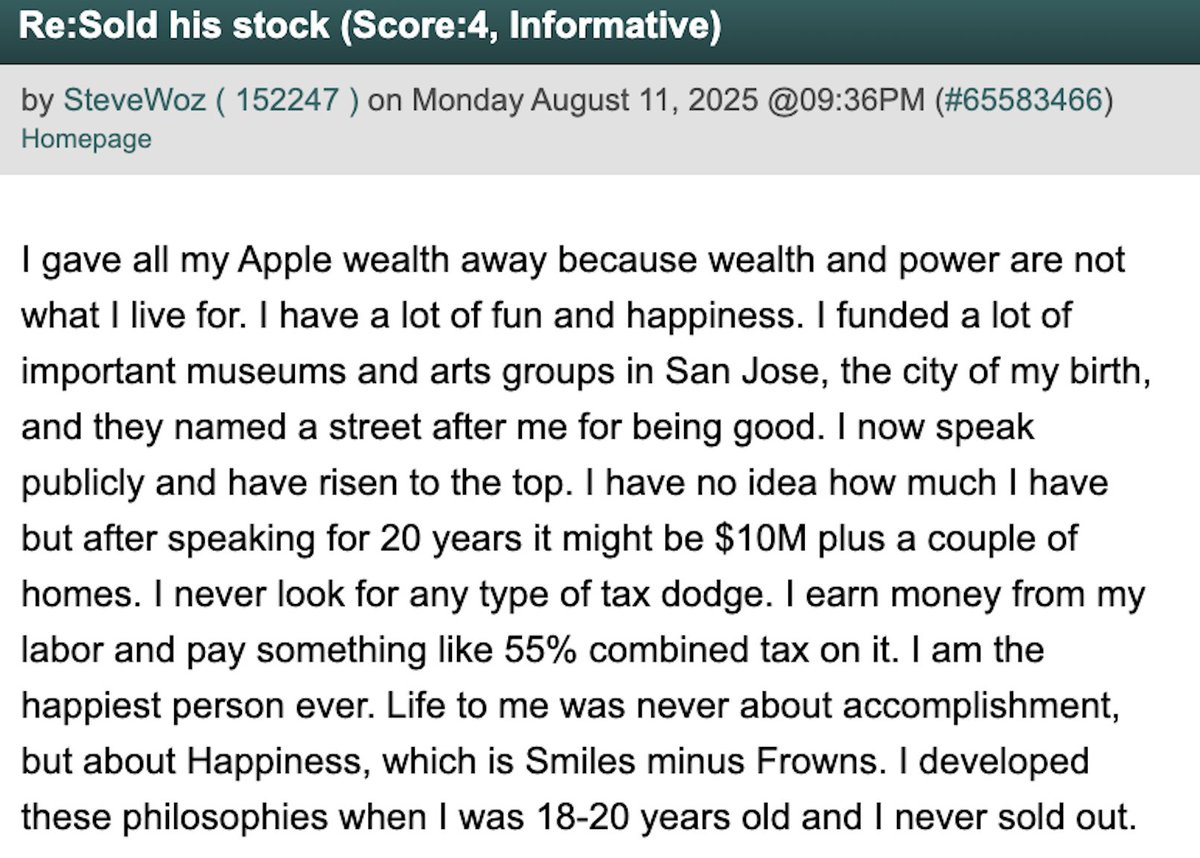
Slashdotters were dunking on @stevewoz for selling his Apple stock… then he showed up in the comments with the most grounded reply.
Gave away his Apple wealth, funds museums, pays his taxes, and measures life by joy: “Happiness is Smiles minus Frowns.”