Pretty sure 50% of internal token spend is completely useless, but right now it's hard to know which 50%.
As an admin I'd love a dashboard that breaks down each person's spend into summarized clusters. Much easier to spend more when you can draw a clear line to value.
Excited to release a new starter! Sync-first, production-ready, and blazing fast
- @tan_stack Start
- @tan_stack DB for blazing fast client-side queries & optimistic mutations
- @ElectricSQL for real-time sync from PG
- @better_auth
- @DrizzleORM
- @tailwindcss
- Hono OpenAPI
METR's @ajeya_cotra says the best way to manage catastrophic AI risk is to set up a "sensible auditing regime that's technically literate," which involves auditors embedded in the frontier model providers.
"You don't want a box-checking auditor that has like 17 arbitrary things you're supposed to do."
"My best guess is that it's going to look like something that happens in the financial sector, where you have embedded auditors. Folks who are experts in finance, who sit and eat lunch with the employees, see all the books, know everything, and have a lot of flexibility to investigate what they need to."
"We're really hoping to move more and more in the embedded direction. Embedded auditing of the monitoring system, potentially even embedded auditing of training."
the year was 2024. you wanted to build an ai chatbot. you installed chroma db locally. you couldn’t figure out how to deploy it so you switched to pgvector. you read a paper on RAG. you spent $4.82 by calling an embedding api after realizing you couldn’t figure out how to get BAAI/bge-large-en-v1.5 working with your broken cuda packages. nvidia stock was overpriced at $90 you’re sure of it. you converted all your documents to embedding. you googled cosine similarity. you called the claude 3 sonnet model api and ran out of context after 8k tokens. you’re deep into reading langchain docs and confused. maybe something called llama index might work. it took four days to prototype but at least github copilot has killer autocomplete. your responses are shit but fortunately openai has a fine tuning api that will help. surely in a few weeks you’ll have something to show your boss, and the answers will be hallucination free. life is good.
A flow I just tried and LOVED:
1. /grill-with-docs, talking about a new bit of UI
2. Asks me a question I can't answer unless I prototype
3. /prototype
4. Iterate on the prototype, burning tokens freely until we get a good spot
5. /rewind to the question, and select 'summarize' (Claude Code feature), saying 'summarize what we learned from prototyping'
6. Continue the grilling session, retaining the prototype
Smoooooooth
I think ontology on write has never been solved after years of research. Best case scenario is an event log that can be reasoned through / linked easily. In practice, setting a strict hash to get proper lineage on incomplete/changing data is a strong bottleneck. I’ve tried building logical consistency checks to “simulate the ontology”, but I do think it’s ultimately a tagging / versioning problem at scale. You can’t even reuse successful agent trajectories because source data and tool schemas change so soon.
Evals are dead. Or more precisely:
traditional eval-driven development doesn’t scale.
Static evals were useful when agents were short-lived and bounded, but once agents are running for hours and taking thousands of actions + operating autonomously, evals alone stop being enough.
At that point pass/fail is too coarse. Simulation misses too much of what happens in prod and model capabilities are moving faster than eval infra can keep up.
What we run instead: observability-driven development.
- deploy with tight guardrails
- collect prod trajectories
- cluster behavior to discover patterns + failure modes
- specialize workers for narrower tasks
- tune thresholds until behavior is reliably within bounds
Can you see what your agents are doing? Can you detect drifts before they cause damage?
This is an important shift in how we build AI systems. Evals still matter but observability is becoming the foundation for prod-ready agents.
Thanks Sunny Bakhda (@honeyhiveai founding engineer) for a great talk at @aicouncilconf
Q: What does it take to build and deploy LLM-powered applications?
A: The AI Engineering Track. Today!
Running Enterprise Agents in Production with @vasundra_s
Evals That Actually Work with @the_bunny_chen
Context Engineering with @simba_khadder
Managing Really Large Multimodel Datasets for AI with @changhiskhan
Pricing AI Agents with @kshithappens
Observability for Long-Running Agents with Sunny Bakhda.
Thanks for curating a great track, @ds3638!
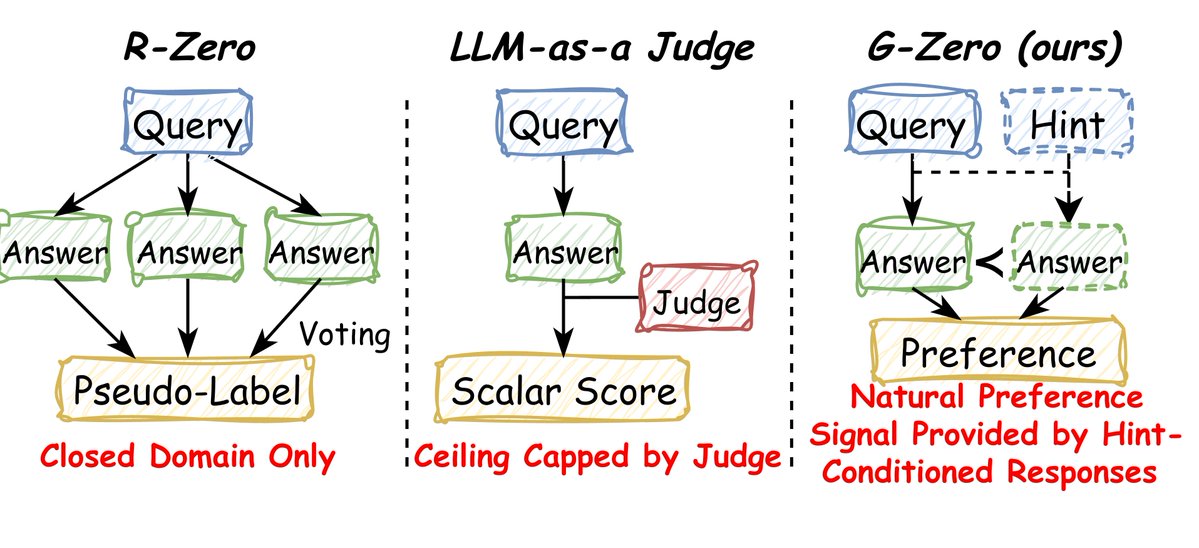
"How do you self-improve a model on open-ended tasks where you can't take a majority vote?"
I got asked this in nearly every research interview I did last year. None of my answers felt clean.
So we built something that doesn't need a vote, a verifier, or a judge.
Meet G-Zero. 👇
paper: https://t.co/TrvGb48W4d
huggingface: https://t.co/8guc5xSh3i
code: https://t.co/G8mMm2I9h1
All experiments are done via api by @thinkymachines (1/n)
I appreciate the work by @EpochAIResearch@GregHBurnham in flagging and fixing these issues. Finding bugs in evaluations is always disappointing, but in the long run, is necessary (and extremely helpful) for improving evaluations. It also reminds me of the issues we uncovered in CORE-Bench: https://t.co/jj9F3wWMo5
As benchmarks become more complex, analyzing benchmark tasks and agent logs will become more important to ensure the validity of evaluation results. Coincidentally, today we released a paper (led by @PKirgis) on how to do log analysis well. https://t.co/rTcirSHuRO
This builds on all our lessons from the trenches in conducting such evaluations and fixing the issues we found in our own work.
I’m sure we’ll find many other issues in our evals, but genuinely think the evals community will be better off for having developed tools and methods to improve eval rigor.
I didn't study a lick of AI in college.
I had studied computer science at MIT, but because I had been interning and working in quant trading, it was much more statistically focused than anything related to machine learning.
Joining Exa AI early was my first exposure, and I still appreciate Jeff Wang for his patience, especially in the early days when I had never even heard of RAG.
For anyone else looking to get started, I would really recommend watching Andrei Karpathy's 'intro to LLMs' 1hr comprehensive deep dive. Even though it is now two years old, it remains highly relevant.
And while really powerful agents exist, Cursor/Windsurf are still a really good first step for going from something you are more familiar with, like the traditional IDE, to understanding how AI can accelerate your current work.
And then, in terms of getting more hands-on, I absolutely love claude cowork, especially if you are non-technical, just to get a glimpse at the power of AI in your day-to-day life.
The human brain🧠 is incredibly efficient because it only activates the specific neurons needed for a thought. Modern LLMs naturally try to do this too (> 95% of neurons in feedforward layers stay silent for any given word), but our hardware punishes them for it.
One of the most frustrating paradoxes in deep learning: making a model do less math often makes it run slower. Why? Because unstructured sparsity introduces irregular memory access, and GPUs are built for predictable, dense blocks of math.
We teamed up with @NVIDIA to try to fix this hardware mismatch. Instead of forcing the GPU to adapt to the sparsity, we built a "Hybrid" format that reshapes the sparsity to fit the GPU. Our sparsity format (TwELL) dynamically routes the 99% of highly sparse tokens through a fast path, and uses a dense backup matrix as a safety valve for the rare, heavy tokens.
Through TwELL and a new set of custom CUDA kernels for both LLM inference and training, we translated theoretical sparsity into actual wall-clock speedups: >20% faster training and inference on H100 GPUs, while also cutting energy consumption and memory requirements.
Paper: https://t.co/rqIY9SYBDe
Blog: https://t.co/oRjNbpJKha
Code: https://t.co/FAFaJwpxAJ
⚡️
Alignment research often has to focus on averting concerning behaviors, but I think the positive vision for this kind of training is one where we can give models and honest and positive vision for what AI models can be and why. I'm excited about the future of this work.
If you’re shipping agents, your observability surface should live where you code. One of the most visible changes in @HoneyHiveAI v2 is that traces and evals now show up where engineers and coding agents already work: the terminal, IDE, and your coding agents.
We're shipping a HoneyHive CLI so teams and agents can talk to the same API the UI uses. You can create or update projects from the command line and pull logs into whatever scripts or CI paths you already use to ship changes. We're also adding agent skills for the entire agent development lifecycle — from development & evals to root-causing alerts & self-healing your agents.
Now Claude Code, Cursor, or any coding agent can:
- Triage failing traces when an alert fires and cluster them by error mode to isolate the regression
- Trace the regression back to the offending change — a prompt edit, a tool schema update, a model swap
- Draft a fix and run it against the affected slice plus your regression set before anything gets proposed
- Open a PR with the RCA, eval diff, and trace links already attached — so you review a fix, not a hypothesis
All of this runs on the same v2 foundation we designed for regulated environments. The control plane stays separate from the data planes, eval compute runs where the data lives, and access is gated with RBAC. If your agents are touching customers, they should inherit the same telemetry and governance guarantees as the rest of your stack.
Wrote more on this here: https://t.co/GaVxA0btUw
Skills and plugins are closer to product marketing than product.
You often still need a dedicated interface to explore tradeoffs, make decisions, handle exceptions..
As with every other product cycle, apps will be radically different than the past, yet as important as ever.