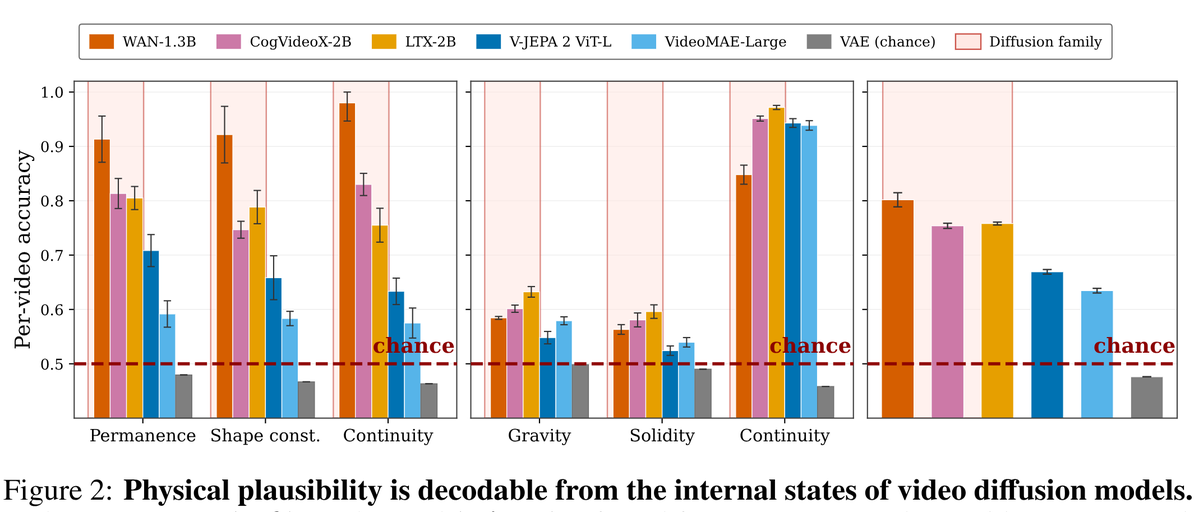
You may have recently heard claims that video generation models are "dumb" about physics, and only "world models" (V-JEPA, specifically) have a valid internal model of physics.
This turns out to be false. In a recent paper, researchers show that a LINEAR probe of diffusion videogen models predict various "physics" very well, significantly better than V-JEPA or VideoMAE (and plain VAE just sucks).
This is noteworthy, because a *linear* probe being this accurate shows that the model has a pretty explicit internal representation of the physics!
I’m getting increasingly annoyed by young people complaining that they cannot do AI-related research unless they join big industrial labs… well, here is my reply: academia is supposed to work on ideas that money cannot buy!
You have noticed it. ChatGPT feels dumber than it used to. Your prompts that worked six months ago produce worse results now. The writing sounds flatter. The ideas sound safer. The internet itself feels like it is shrinking. Every article reads the same. Every email sounds the same. Every answer sounds like it was written by the same voice.
You thought it was you. It is not you.
Researchers at Oxford and Cambridge published a paper in Nature proving what is happening. They call it Model Collapse.
Here is the mechanism in one sentence. AI trained on AI-generated data gets dumber every generation until it forgets what real human data looked like.
The internet is filling with AI-generated content. Blog posts. Articles. Reviews. Comments. Social media. AI companies scrape the internet to train the next generation of models. Which means the next generation of AI is being trained on the output of the current generation.
Each cycle loses information. Not randomly. It loses the rarest, most unusual, most creative parts first. The researchers call these the "tails of the distribution." The weird ideas. The unexpected perspectives. The things that made the internet feel human. Those disappear first.
What remains is the average. The safe. The expected. The bland.
Then the next generation trains on that. And loses more. And the next generation trains on that. And loses more. The researchers proved this is not a slow decline. Major degradation happens within just a few iterations. Even when some of the original human data is preserved.
They tested it on large language models. On image generators. On statistical models. The pattern was the same every time. The output converges toward a narrow, flattened version of reality that looks nothing like the original data.
The lead researcher put it plainly. "Large language models are like fire. A useful tool. But one that pollutes the environment."
The pollution is invisible. You cannot see which sentence on the internet was written by a human and which was written by AI. Neither can the AI that is about to train on it. And once the tails are gone, they do not come back. The damage is irreversible.
This is not a prediction anymore. It is a diagnosis.
The internet you grew up on was built by humans writing things no algorithm would have written. Strange, personal, imperfect, alive. That internet is being diluted. One generation of AI at a time. And the models trained on what remains are learning a smaller and smaller version of the world.
Model Collapse is not a technical problem. It is a cultural one. The thing that made the internet worth reading is the thing that disappears first.
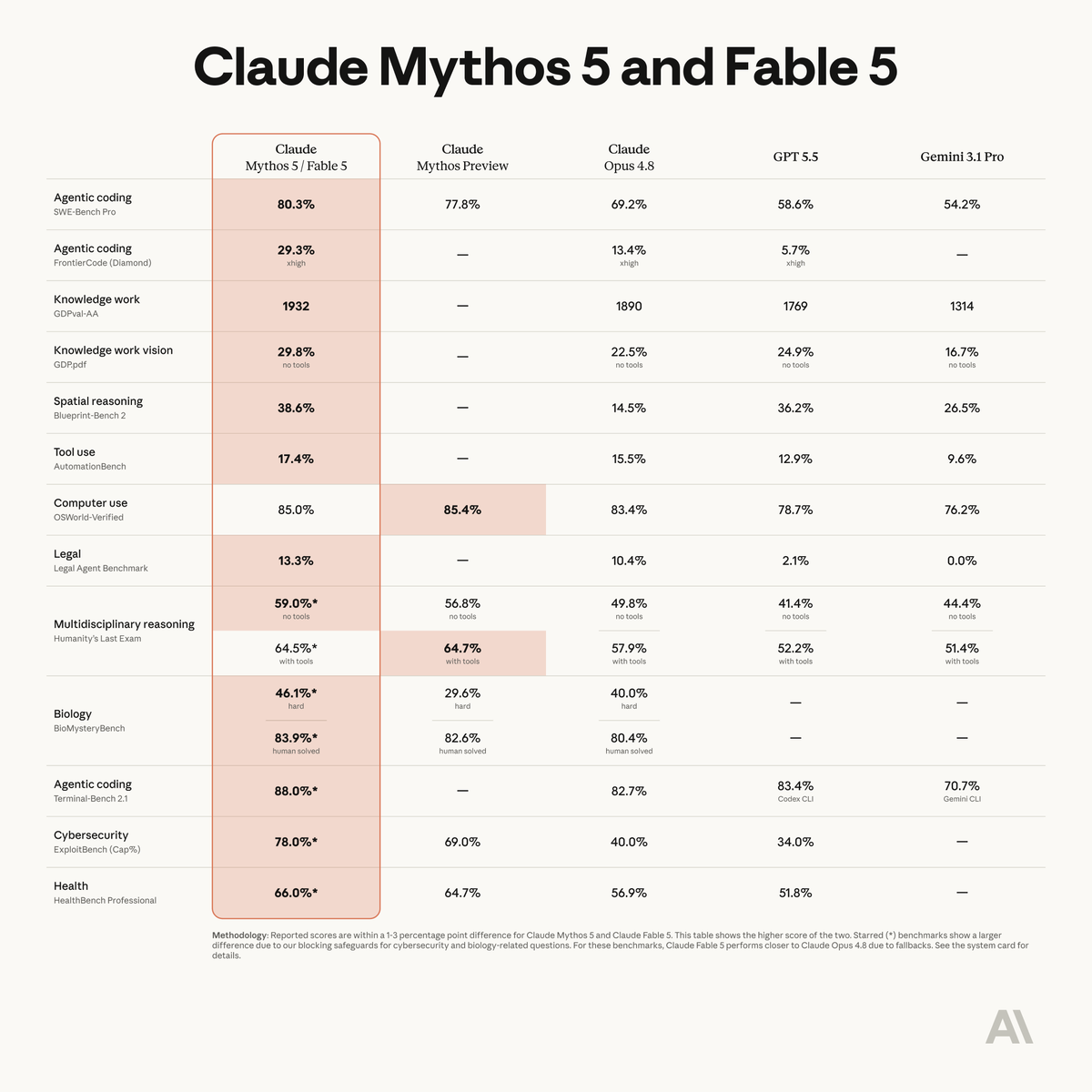
Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision.
The longer and more complex the task, the larger Fable 5’s lead over our other models.
Super proud of my students and collaborators, especially @FuWanjia and @Hongyu_Lii for the Outstanding Paper Award at the Sense of Space workshop @CVPR for UniTac: https://t.co/2hvrWNmbcB
1/ Introducing GPIC: a Giant Permissive Image Corpus and benchmark for visual generation!
🚀100M VLM-captioned image-text pairs for training
📊1M image-text pairs for benchmarking
🖼️~28 trillion pixels
🤗Centrally Hosted
✅Fully permissive for research + commercial use
Dataset, benchmark and models🧵👇
Co-led with @KyleSargentAI
VISReg: Variance-Invariance-Sketching Regularization for JEPA training
"We propose VISReg (Variance-Invariance-Sketching Regularization), a novel method that prevents embeddings from collapse while learning good representations."
"By decoupling scale and shape, VISReg combines
VICReg’s flexibility with the distributional rigor of sketching methods, providing robust gradients even under collapse"
"Pre-trained on ImageNet-22K, it matches DINOv2’s OOD performance despite the latter using 10× more data (LVD-142M)."
For the past years my research focus was on unifying models and training paradigms across modalities. Today I'm excited that we're releasing our latest model aligned with this theme:
Gemma 4 12B, a dense encoder-free model which processes raw text, image, and audio inputs!
1/
ByteDance Seed removes the VAE bottleneck from unified multimodal models
Their technique, Representation Forcing, lets decoders predict visual representations before pixels so generation and understanding share one end-to-end space.
在研究界,
范式上降维打击远比原地搬砖硬砸要容易得多。
你不需要在两个领域同时成为最顶尖的专家,你只需要把 A 领域已经玩烂了的、极其成熟的硬核工具,精准地平移到 B 领域那个刚刚兴起、大家都还在抓耳挠腮的混乱泥潭里。
因为 B 领域的人没见过这么好用的锤子,而 A 领域的人又没注意到这颗新钉子。
以我最了解的AI x 心理学的案例举例。
第一步,盘点你的硬核锤子,成熟领域 A
这里的锤子,必须具备两个特点。
逻辑极度严密。
有一套公认的数学或行为实验范式。
实验心理学的行为范式与严苛控制,比如心理学里的元认知量化、态度与Persuasion Models。
这些体系经历了无数行为实验的洗礼,在统计学和控制变量的设计上极其严密。
多模态视觉-文本的底层表征工具,比如用来把图像和文字映射到同一特征空间的数学模型与表征技术,其特征提取和向量对齐的计算方式在机器学习中已经高度标准化。
第二步,锁定有热度、有盲区的新钉子,前沿领域 B
这颗钉子往往出现在当下最火、资源最多、但大家都还在黑盒里乱撞的领域,比如大模型、生成式 AI、AI 伦理与人机交互
前沿领域的普遍痛点是缺乏硬性的评估标准和底层的解释工具。
大模型在长文本或长序列生成时的Stability到底怎么定量评估?
目前的评测集很多都在流于表面。
人类的意识带宽、感知边界在面对爆发的多模态信息刺激时,传统工具往往由于维度太低而无法精准量化。
第三步,像素级合体,这就是你的硬核 Idea
有了锤子和钉子,接下来就是套利的发生瞬间。
(你就会生成一些想法和idea)
第四步,用 AI 榨干这个 Idea 的生存概率实操降噪
当你通过跨界平移组合出一个初步想法后,不要马上去写论文或做实验,先用大模型做极限压力测试。
我最喜欢给 AI 的降噪 Prompt 框架:
“我现在试图把 A 领域的 [具体成熟方法论/实验范式] 平移到 B 领域的 [具体前沿问题] 中。请你作为最挑剔的Reviewer ,从以下三个硬核维度攻击我:
01 这两个领域在底层假设上有什么不可调和的冲突?(防范逻辑硬伤)
02 B 领域的哪些特有噪声或变量,会彻底摧毁 A 领域原本严密的实验控制?
03 这种平移,会不会沦为一个毫无实际学术价值的‘玩具应用’?如果是,怎么修正才能让它具备硬性的定量科学意义?”
通过这种方式,AI 会逼着你把所有模糊的、宏大的概念,全部缩减成可测量的变量、可控的实验、可对比的 Metric。
看完这个系统性的拆解,如果让你把自己手头最熟悉最扎实的那个硬核工具,去尝试暴力拆解一个最近关注的前沿黑盒吧!
Image editing models can put you on the Moon, but can they precisely move a circle right by 50 pixels? 📐
Introducing 🎨PaintBench: a foundational eval of visual editing operations with only one right answer.
The highest-performing model (@NanoBanana 2) reaches only 17.1%.
Can MLLMs actually track what's happening in a video?
Introducing VSTAT 🎯, our new benchmark for visual state tracking.
The tasks are simple: count cups, read typed words, count page flips. Humans solve them easily. MLLMs don't.
https://t.co/dgqhqeVuSv
🧵 [1/11]
I’m in love with this sentence:
“The degree to which a person can grow is directly proportional to the amount of truth he can accept about himself without running away.”
We take for granted that larger models are better than smaller ones, but why is this so? Our new paper, led by Jing Huang and @EkdeepL, traces this to a data-induced competition for resources (neurons), using formal analysis, idealized tasks, and real pretraining.