Andrej Karpathy could have packaged this into a $2,000 masterclass.
Instead, he uploaded it to YouTube for free.
Three hours covering how modern LLMs actually work:
tokenization, neural nets, RLHF, hallucinations, tool use, reinforcement learning, and systems like AlphaGo and DeepSeek.
This isn’t about prompts.
It’s about understanding the machine behind the magic.
🚨BREAKING: A dev just open-sourced the #1 ranked OCR model on Earth.
It's called GLM-OCR and it just hit 94.62 on OmniDocBench V1.5, beating every OCR model in existence.
Only 0.9B parameters. One pip install. Handles documents no other model could touch.
100% Open Source.
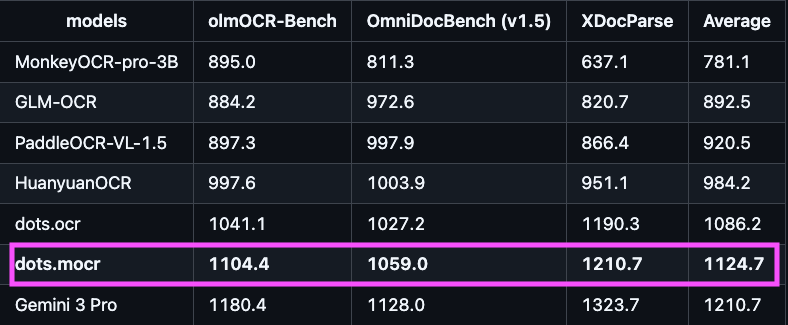
Another OCR model just dropped on @huggingface (so many OCRs lately!)
dots.mocr from @xiaohongshu Hi Lab looks really impressive on the benchmarks.
-Model: https://t.co/tv9CrfnddG
-Paper: https://t.co/JAGPQnPBxJ
✨ 3B
✨ Multilingual support
✨ Converts charts, diagrams, and UI layouts directly into SVG code
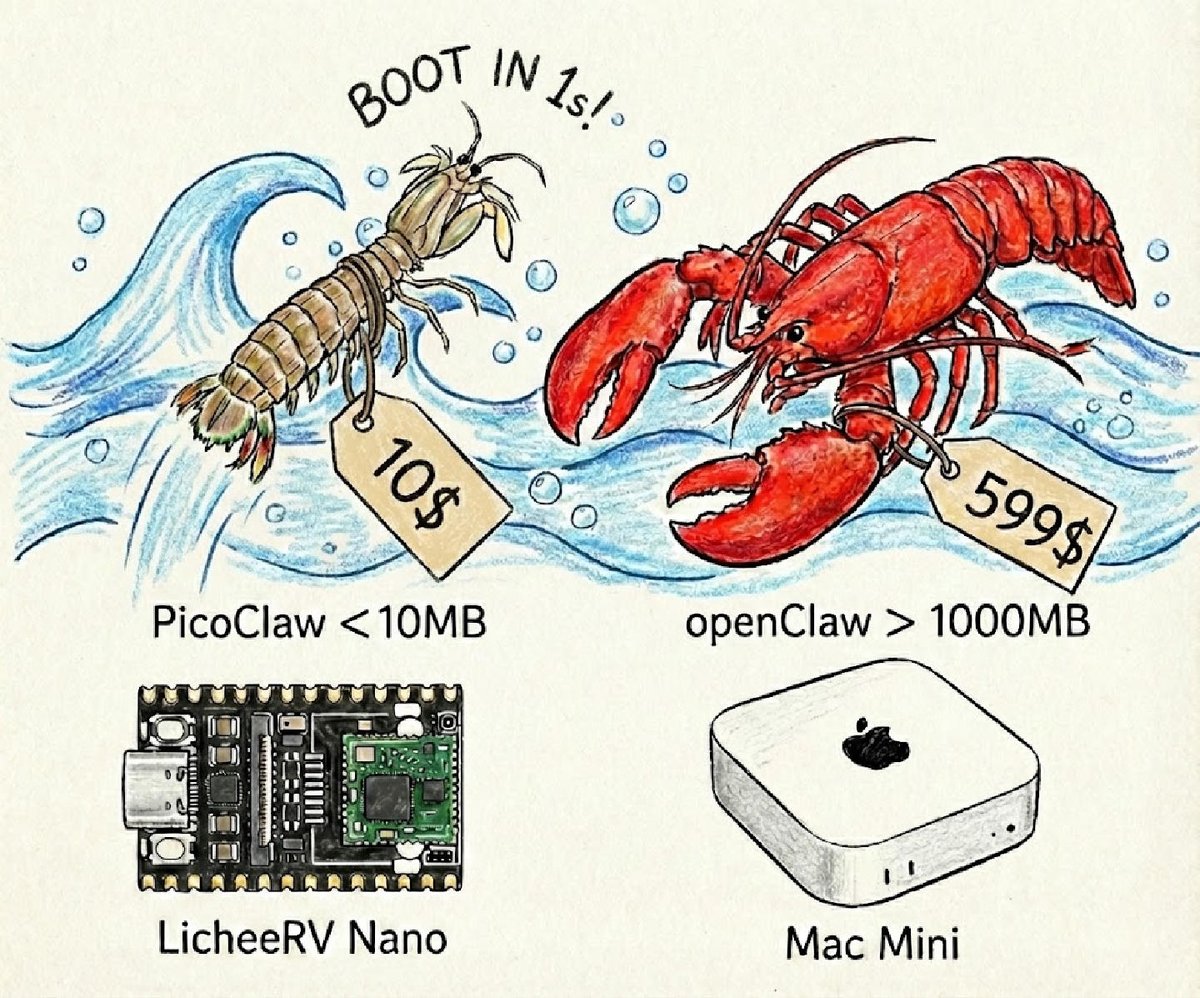
A Chinese hardware team just mass-democratized AI agents.
They took a 430,000-line AI assistant that needs a $599 Mac Mini and 1GB of RAM — and rewrote it in Go so it runs on a $9.9 dev board with less than 10MB of memory.
Boot time: from 500 seconds to 1 second.
Cost: from $599 to $9.9.
Memory: from 1GB to 10MB.
Same features: code generation, web search, Discord/Telegram chat, memory system, scheduled tasks, security sandbox.
The wildest part? They claim 95% of the new codebase was written by AI agents themselves. The humans just guided the architecture. It's an AI assistant that literally rebuilt itself to be smaller.
Launched February 9th. Four days later: 7,400+ GitHub stars.
This is the pattern no one's talking about enough.
Every AI capability that starts expensive gets commoditized within months. GPT-4 level models went open source in 6 months. Now the hardware floor for running a personal AI agent just dropped 60x in weeks.
The infrastructure moat in AI isn't sustainable. The only defensible advantage is what you do with these tools — not access to them.
I don’t know about others, but I’m letting Opus 4.6 design directly in Figma via Cursor.
This is starting to feel unfair.
And yeah… I just sit there and enjoy life. ❤️
Chinese engineers literally refactored @OpenClaw in Go for insane efficiency 🤯
It runs on a $10 @Raspberry_Pi instead of a $399 Mac mini.
→ Uses <10 MB of memory (99% smaller than OpenClaw)
→ 400× faster startup time
→ Boots in 1 second
Free and open source, repo in 🧵↓
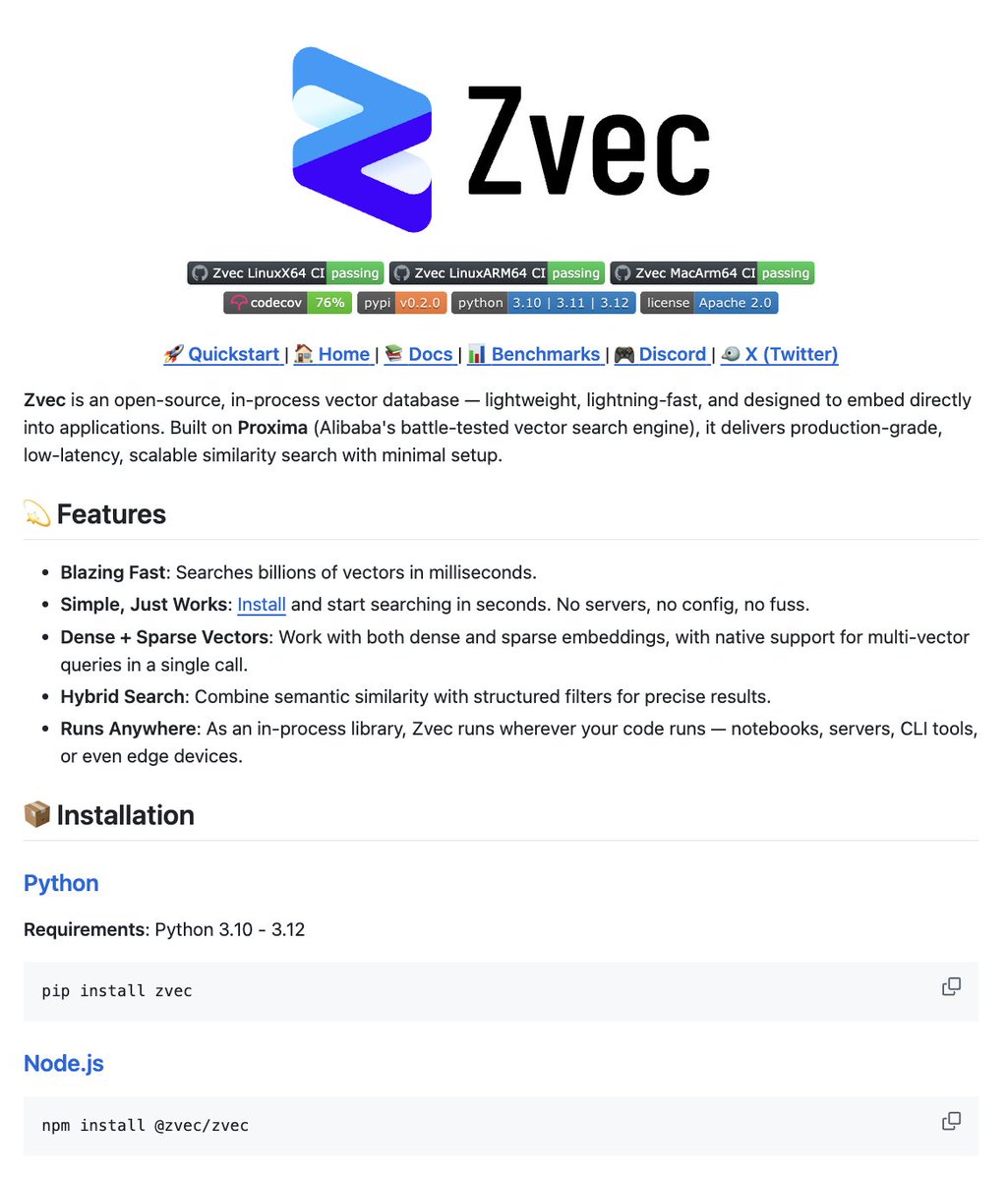
China's Alibaba just opensourced the SQLite of vector databases.
zvec runs as a library inside your app and is built for on-device RAG
no external server. no pinecone. no qdrant instance.
100% opensource.
NVIDIA just dropped PersonaPlex-7B 🤯
A full-duplex voice model that listens and talks at the same time.
No pauses. No turn-taking. Real conversation.
100% open source. Free.
Voice AI just leveled up.
https://t.co/YfzFQfBzMS
I reverse-engineered Claude Code's binary.
Found a flag they hid from --help.
--sdk-url
Enable it and the terminal disappears. The CLI becomes a WebSocket client.
We built a server to catch the connection. Added a React UI on top.
Now I run Claude Code from my browser. From my phone. From anywhere.
Same $200/month subscription. Zero extra API costs.
bunx the-vibe-companion
https://t.co/8Dnp7M46vU
I'm Boris and I created Claude Code. I wanted to quickly share a few tips for using Claude Code, sourced directly from the Claude Code team. The way the team uses Claude is different than how I use it. Remember: there is no one right way to use Claude Code -- everyones' setup is different. You should experiment to see what works for you!
Converts PDF documents to Markdown format using DeepSeek-OCR with FastAPI backend.
This guy bave it 10000 pdfs to convert to markdown.
averaging less than 1 second per page.
Hardware - 1 x A6000 ADA on a Ryzen 1700 /w 32gb ram
Dockerized model with fastapi in a wsl environment.
🚀 DeepSeek-OCR — the new frontier of OCR from @deepseek_ai , exploring optical context compression for LLMs, is running blazingly fast on vLLM ⚡ (~2500 tokens/s on A100-40G) — powered by vllm==0.8.5 for day-0 model support.
🧠 Compresses visual contexts up to 20× while keeping 97% OCR accuracy at <10×.
📄 Outperforms GOT-OCR2.0 & MinerU2.0 on OmniDocBench using fewer vision tokens.
🤝 The vLLM team is working with DeepSeek to bring official DeepSeek-OCR support into the next vLLM release — making multimodal inference even faster and easier to scale.
🔗 https://t.co/rnBG9VUuMy
#vLLM #DeepSeek #OCR #LLM #VisionAI #DeepLearning
I quite like the new DeepSeek-OCR paper. It's a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn't matter.
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input.
Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you'd prefer to render it and then feed that in:
- more information compression (see paper) => shorter context windows, more efficiency
- significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images.
- input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful.
- delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It "imports" all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an... actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go.
OCR is just one of many useful vision -> text tasks. And text -> text tasks can be made to be vision ->text tasks. Not vice versa.
So many the User message is images, but the decoder (the Assistant response) remains text. It's a lot less obvious how to output pixels realistically... or if you'd want to.
Now I have to also fight the urge to side quest an image-input-only version of nanochat...
Excitement is building as new whisky lines hit the shelves.
Explore the latest releases and discover unique flavors from around the world.
Discover the latest whisky releases, featuring rare blends and aged single malts from top distilleries around the world.🧞♂️
Explore new fav