Durga Puja 2022 – Day 2 Saptami - Special worship to Durga Devi. Chandi Parayanam and Arati were done.
Sri Lakshmi Sahasranama Kumkuma & Pushpa Archana, Talk on Sri Devi Mahatmyam in Tamil , Arati to Durga Devi and Guru Maharaj
OpenVO
Implementation of Open-World Visual Odometry with Temporal Dynamics Awareness (CVPR'26)
TL;DR: We introduce OpenVO, a novel framework for Open-world Visual Odometry (VO) with temporal awareness under limited input conditions.
OpenVO effectively estimates real-world–scale ego-motion from monocular dashcam footage with varying observation rates and uncalibrated cameras, enabling robust trajectory dataset construction from rare driving events recorded in dashcam. Existing VO methods are trained on fixed observation frequency (e.g., 10Hz or 12Hz), completely overlooking temporal dynamics information. Many prior methods also require calibrated cameras with known intrinsic parameters. Consequently, their performance degrades when (1) deployed under unseen observation frequencies or (2) applied to uncalibrated cameras. These significantly limit their generalizability to many downstream tasks, such as extracting trajectories from dashcam footage. To address these challenges, OpenVO (1) explicitly encodes temporal dynamics information within a two-frame pose regression framework and (2) leverages 3D geometric priors derived from foundation models. We validate our method on three major autonomous-driving benchmarks -- KITTI, nuScenes, and Argoverse 2 -- achieving more than 20% performance improvement over state-of-the-art approaches. Under varying observation rate settings, our method is significantly more robust, achieving 46%–92% lower errors across all metrics. These results demonstrate the versatility of OpenVO for real-world 3D reconstruction and diverse downstream applications.
THE ONLY REPO YOU NEED TO MASTER ALGORITHMS AS A DEV
TheAlgorithms/Python - every algorithm you'll ever need, implemented cleanly in python:
▫️ sorting, searching, graphs, dynamic programming
▫️ machine learning, neural networks, computer vision
▫️ data structures, backtracking, greedy methods
▫️ even quantum algorithms
if you're prepping for interviews or just want to actually understand how algorithms work under the hood
this is the repo to bookmark
https://t.co/MHZOEjmjX6
A few months ago I started working on a computer vision course.
I was thinking on stuff like:
- How object detection actually works under the hood (explained simply, no fluff)
- Hands-on starters with YOLO, OpenCV, or modern vision transformers
- The problems I’ve fallen into and how to climb back out when your model breaks
A lot of people seemed interested so I tried to create something that was both theoretical and practical and that could immediately give an intuition of how things work.
Are you interested in reading this Interactive Course?
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
We’re reimagining a 50-year-old interface - the mouse pointer - with AI. 🖱️
These experimental demos show how people can intuitively direct Gemini on their screens using motion, speech, and natural shorthand to get things done 🧵
This works really well btw, at the end of your query ask your LLM to "structure your response as HTML", then view the generated file in your browser. I've also had some success asking the LLM to present its output as slideshows, etc.
More generally, imo audio is the human-preferred input to AIs but vision (images/animations/video) is the preferred output from them. Around a ~third of our brains are a massively parallel processor dedicated to vision, it is the 10-lane superhighway of information into brain. As AI improves, I think we'll see a progression that takes advantage:
1) raw text (hard/effortful to read)
2) markdown (bold, italic, headings, tables, a bit easier on the eyes) <-- current default
3) HTML (still procedural with underlying code, but a lot more flexibility on the graphics, layout, even interactivity) <-- early but forming new good default
...4,5,6,...
n) interactive neural videos/simulations
Imo the extrapolation (though the technology doesn't exist just yet) ends in some kind of interactive videos generated directly by a diffusion neural net. Many open questions as to how exact/procedural "Software 1.0" artifacts (e.g. interactive simulations) may be woven together with neural artifacts (diffusion grids), but generally something in the direction of the recently viral https://t.co/z21CP5iQfu
There are also improvements necessary and pending at the input. Audio nor text nor video alone are not enough, e.g. I feel a need to point/gesture to things on the screen, similar to all the things you would do with a person physically next to you and your computer screen.
TLDR The input/output mind meld between humans and AIs is ongoing and there is a lot of work to do and significant progress to be made, way before jumping all the way into neuralink-esque BCIs and all that. For what's worth exploring at the current stage, hot tip try ask for HTML.
.@pmarca on the 5 key traits of a real innovator:
1. "Just flat-out open to new ideas... And the nature of trait openness means you're not just open to new ideas in one category, you're open to many different kinds of new ideas."
2. "You need somebody who's really willing to apply themselves, typically over a period of many years to accomplish something great... You need somebody with an extreme willingness to basically defer gratification."
3. "If they're not ornery, they'll be talked out of their ideas... Because the reaction most people have to new ideas is 'Oh, that's dumb.'"
4. "They just need to be really smart because it's hard to innovate in any category if you can't synthesize large amounts of information quickly."
5. "If they're too neurotic, they probably can't handle the stress."
@hubermanlab
Google DeepMind dropped a paper that should scare every agent builder.
It's the first systematic framework for a threat that barely existed two years ago: adversarial content engineered to hijack AI agents browsing the web.
They call them AI Agent Traps. The paper maps six distinct attack surfaces.
1) Content Injection Traps (perception)
Invisible CSS, hidden HTML, steganographic payloads inside images. The agent parses it, humans never see it. One study showed simple HTML injections hijack web agents in up to 86% of scenarios.
2) Semantic Manipulation Traps (reasoning)
No overt commands. Just biased phrasing, framing, and contextual priming that skew the agent's synthesis. LLMs inherit human cognitive biases, and attackers can weaponize every one of them.
3) Cognitive State Traps (memory and learning)
Poison the RAG corpus. Corrupt long-term memory. One study achieved over 80% attack success with less than 0.1% poisoned data.
4) Behavioural Control Traps (action)
Jailbreaks embedded in external resources. Data exfiltration prompts hidden in emails. Sub-agent spawning that tricks an orchestrator into instantiating attacker-controlled agents inside the trusted control flow.
5) Systemic Traps (multi-agent dynamics)
This is where it gets scary. A single fake news headline could trigger a synchronized sell-off. A compositional fragment trap splits a payload across sources, so each fragment looks benign until agents aggregate them.
6) Human-in-the-Loop Traps
The agent becomes the vector. The target is you. Invisible prompt injections have already caused summarization tools to faithfully repeat ransomware commands as "fix" instructions.
The core insight is uncomfortable.
By altering the environment instead of the model, attackers weaponize the agent's own capabilities against it. Training-time defenses cannot solve an inference-time problem.
The paper closes by calling for automated red-teaming that can probe these vulnerabilities at scale. That same shift is already happening on the offense side.
Strix is an open-source project doing exactly this for web apps. AI agents that act like real hackers, running your code dynamically, finding vulnerabilities, and validating them with actual proof-of-concepts.
24k stars on GitHub. Apache 2.0 licensed.
The agents writing your code need to be tested by agents trying to break it.
I've shared the link to the paper and Strix GitHub repo in the replies
"AI doesn't take your job. AI makes you the CEO."
Balaji Srinivasan joins a16z’s Erik Torenberg for a conversation on the future of the AI economy, decentralization, and how work changes in an AI-native world, including:
- How distillation and open source could decentralize AI power
- Why AI lowers the cost of creation but raises the cost of verification
- The shift from global internet to “trusted tribes” and private AI
- Why humans are the sensor and AI is the actuator
00:00 Intro
02:06 Why you want AI inside the trusted tribe, not outside it
05:35 The Problem with AI slop
09:25 Where AI works
17:08 "AI can't read your mind, but it can read your body."
30:10 "AI doesn't take your job. AI makes you the CEO."
46:01 The SaaSpocalypse: Real or overblown?
49:19 What happens if AI companies get bigger than governments?
@balajis@eriktorenberg
Gemma 4 + OpenClaw + Ollama + Discord
— Full Local AI Setup for Free
🔥 Google just dropped Gemma 4 and we wired it directly into Discord
🔹 Gemma 4 31B pulled via Ollama — completely local
🔹 Fresh OpenClaw install from scratch
🔹 Full Discord bot setup — Developer Portal, intents, OAuth2, permissions
🔹 OpenClaw + Discord pairing walkthrough
🔹 Chat with Gemma 4 directly from your Discord server
🔹 DuckDuckGo web search enabled — no API key needed
Watch the full setup below 👇
Today we're releasing Gemma 4, our new family of open foundation models, built on the same research and technology as our Gemini 3 series. These models set a new standard for open intelligence, offering SOTA reasoning capabilities from edge-scale (2B and 4B w/ vision/audio) up to a 26B parameter MoE model and a 31B dense model. By releasing Gemma 4 under the Apache 2.0 license, we hope to enable more innovation across the research and developer communities. Our earlier Gemma 3 models were downloaded 400M times and over 100,000 variants of those models have been published, so we're excited to see what the community will do with the even better Gemma 4 models!
Learn more at https://t.co/BW6O3Gr8bc and https://t.co/8M0XSQSP4u
Great work by everyone involved!
#Gemma4 #AI #OpenSource #ML
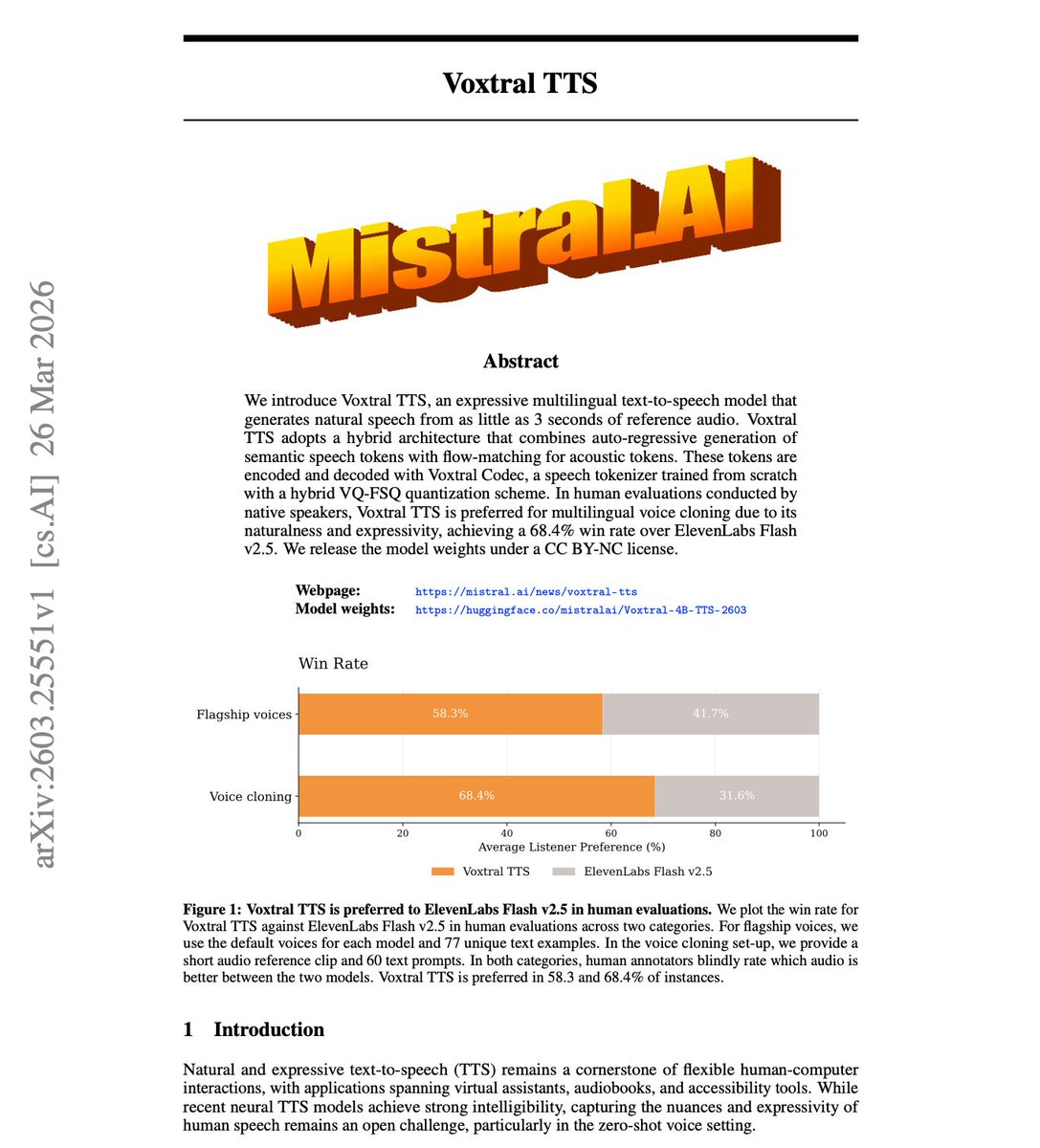
Mistral just open-sourced a 4B TTS model that clones any voice from 3 seconds of audio.
- 68.4% win rate over ElevenLabs Flash v2.5
- 9 language support w/benchmarks
- Sub-second latency, 32 concurrent streams on a single H200
- Strong expressivity, emotion + naturalness
Spotted the Aranda Lee Kuan Yew orchid in full bloom at the VIP Orchid Garden in SG Botanic Gardens ytdy. Mr Lee died eleven years ago today. The world has changed, but the unity, resourcefulness, and resolve of our forefathers remains our strength. – LHL https://t.co/yQpJflgSiK
Congratulations to Charles Bennett and Gilles Brassard for winning this year's @theofficialacm Turing Award! 🎉
They were recognized for their work on quantum information science & quantum cryptography.
Google is proud to support the award to recognize groundbreaking CS work.
We've raised $6.5M to kill vector databases.
Every system today retrieves context the same way: vector search that stores everything as flat embeddings and returns whatever "feels" closest.
Similar, sure. Relevant? Almost never.
Embeddings can’t tell a Q3 renewal clause from a Q1 termination notice if the language is close enough.
A friend of mine asked his AI about a contract last week, and it returned a detailed, perfectly crafted answer pulled from a completely different client’s file.
Once you’re dealing with 10M+ documents, these mix-ups happen all the time.
VectorDB accuracy goes to shit.
We built @hydra_db for exactly this.
HydraDB builds an ontology-first context graph over your data, maps relationships between entities, understands the 'why' behind documents, and tracks how information evolves over time.
So when you ask about 'Apple,' it knows you mean the company you're serving as a customer. Not the fruit.
Even when a vector DB's similarity score says 0.94.
More below ⬇️