In the prisoner's dilemma, despite the fact that both players cooperating is Pareto efficient, the only pure Nash equilibrium is when both players choose to defect.
#TIL #6 In addition to the well known Prisoners Dilemma, a similar game theory concept is Stag Hunt. The stag hunt differs from the prisoner's dilemma in that there are two pure-strategy Nash equilibria:[2] one where both players cooperate, and one where both players defect.
#TIL #5 The S&P returned 18% last year, its third double digit year in a row. However if you are a gold based investor rather than a dollar based investor, it returned -28%.
Same companies, same performance, just different perspectives.
#TIL #4 Parasocial relationships being developed with AI. Study of 3,532 people shows relationship-seeking AI quickly feels good, then less so, while “wanting” keeps growing. Users form attachment, seek more AI companionship, see it as friend not too, gain no psychosocial benefit
#TIL #3 The Zeigarnik Effect is the psychological tendency to remember unfinished or interrupted tasks better than completed ones. This explains why we get distracted by incomplete to-do lists, but also how starting a task, even briefly, increases the likelihood of finishing it
TIL #2: the Mexican fishermen parable.
An American investment banker meets a Mexican fisherman who catches a few large tuna in only a little while—just enough to support his family. Asked why he doesn’t stay out longer, the fisherman explains he sleeps late, fishes a little,
Control production and distribution. Move from the small village to Mexico City, then Los Angeles, then New York. In 15–20 years, announce an IPO, sell stock, and make millions.
“And then what?” the fisherman asks.
“Then you retire,” says the banker—move to a small coastal
This came out 4 days before OpenAI released 4o rather than 5. Great timing as the counter to pure AI optimism. https://t.co/wylvkN6EXF seems it will take another transformer level breakthrough, I’d bet on us to find it.
GPT-4o hot take:
• The speech synthesis is terrific, reminds me of Google Duplex (which never took off).
but
• If OpenAI had GPT-5, they have would shown it.
• They don’t have GPT-5 after 14 months of trying.
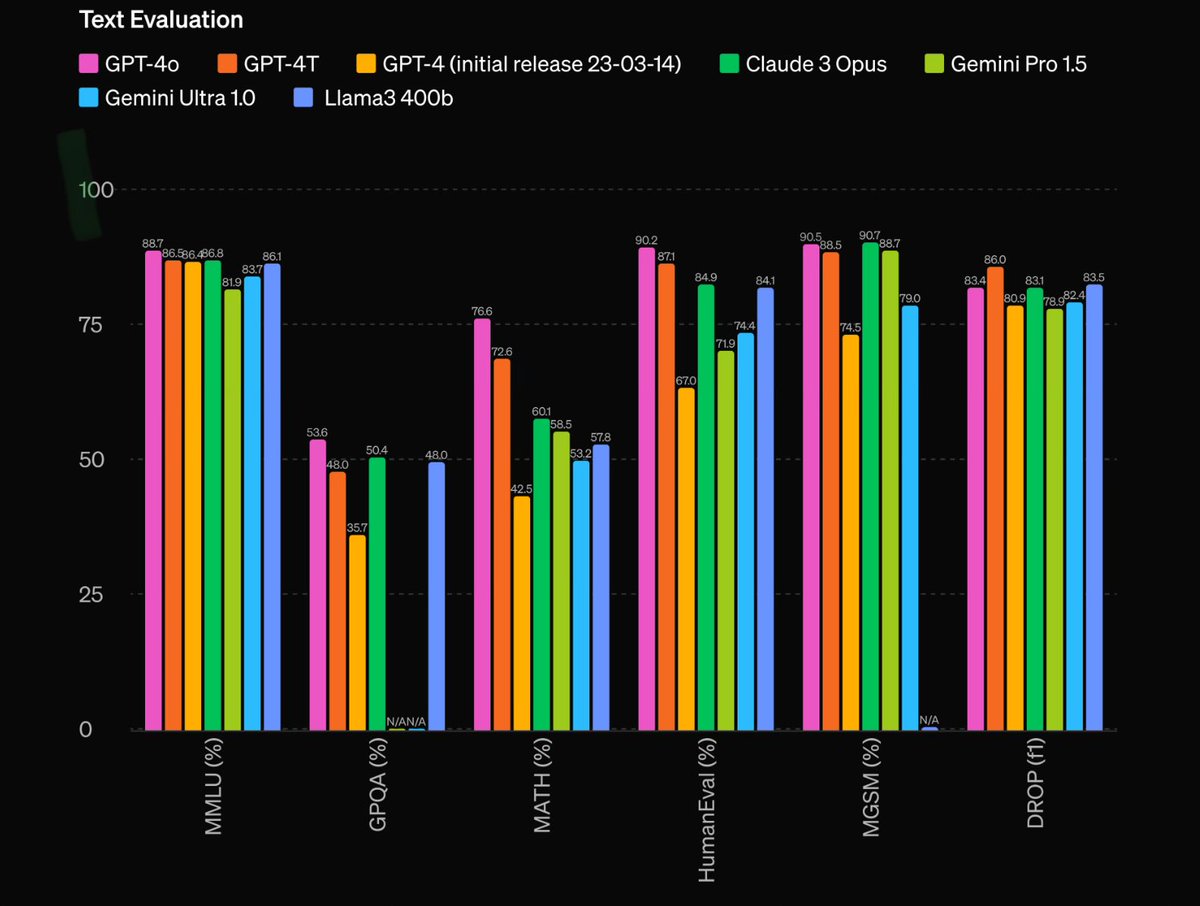
• The most important figure in the blogpost is attached below. And the most important thing about the figure is that 4o is not a lot different from Turbo, which is not hugely different from 4.
• Lots of quirky errors are already being reported, same as ever. (See e.g., examples from @RosenzweigJane and @benjaminjriley.)
• OpenAI has presumably pivoted to new features precisely because they don’t know how produce the kind of capability advance that the “exponential improvement” would have predicted.
• Most importantly, each day in which there is no GPT-5 level model–from OpenAI or any of their well-financed, well-motivated competitors—is evidence that we may have reached a phase of diminishing returns.
Best advice I ever got: think like a VC when looking for tech job.
It led me to joining Rippling ($11B+) before its Series A. It changed my life, so I built a free tool to help others.
We expect that each company listed on Prospect will grow at least 2X over the next 4 years:
Discovered an intriguing concept - Kahneman-Tversky Optimization (KTO). It's not just about aligning LLMs more efficiently and cheaply, but also a leap towards valuing implicit feedback over explicit feedback. Really cool stuff! #KTO#AI#ImplicitFeedback https://t.co/zwZmpCFRZy
Google, this is embarrassing.
You published an impressive video showing Gemini answering your questions. It looked awesome. It looked real-time.
But it was a lie. None of that happened as recorded and presented to the public.
Instead, you cherry-picked frames and edited a video in a way you knew it would impress people.
That's misleading, and anyone who participated in this charade should be embarrassed.
I hope I'm wrong.
Read their disclaimer:
"We've been capturing footage to test it on a wide range of challenges, showing it a series of images, and asking it to reason about what it sees."
@DrJimFan I wonder if the star part of Q* also has reference to A* search. The simplest way I’ve thought of that is adding another model for the A* heuristic to speed up the exploration of the ToT. Would this be the job of the Value NN?
Claude 2.1 (200K Tokens) - Pressure Testing Long Context Recall
We all love increasing context lengths - but what's performance like?
Anthropic reached out with early access to Claude 2.1 so I repeated the “needle in a haystack” analysis I did on GPT-4
Here's what I found:
Findings:
* At 200K tokens (nearly 470 pages), Claude 2.1 was able to recall facts at some document depths
* Facts at the very top and very bottom of the document were recalled with nearly 100% accuracy
* Facts positioned at the top of the document were recalled with less performance than the bottom (similar to GPT-4)
* Starting at ~90K tokens, performance of recall at the bottom of the document started to get increasingly worse
* Performance at low context lengths was not guaranteed
So what:
* Prompting Engineering Matters - It’s worth tinkering with your prompt and running A/B tests to measure retrieval accuracy
* No Guarantees - Your facts are not guaranteed to be retrieved. Don’t bake the assumption they will into your applications
* Less context = more accuracy - This is well know, but when possible reduce the amount of context you send to the models to increase its ability to recall
* Position Matters - Also well know, but facts placed at the very beginning and 2nd half of the document seem to be recalled better
Why run this test?:
* I’m a big fan of Anthropic! They are helping to push the bounds on LLM performance and creating powerful tools for the world
* As a practitioner of LLMs, it’s important to build an intuition for how they work, where they excel and their limits
* Tests like these, while not bulletproof, help showcase real world examples and get a feeling for how they work. The goal is to transfer this knowledge to productive use cases
Overview of the process:
* Use Paul Graham essays as ‘background’ tokens. With 218 essays it’s easy to get up to 200K tokens (repeated essays when necessary)
* Place a random statement within the document at various depths. Fact used: “The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day.”
* Ask Claude 2.1 to answer this question only using the context provided
* Evaluate Claude 2.1s answer with GPT-4 using @langchain evals
* Rinse and repeat for 35x document depths between 0% (top of document) and 100% (bottom of document) (sigmoid distribution) and 35x context lengths (1K Tokens > 200K Tokens)
Next Steps To Take This Further:
* For rigor, one should do a key:value retrieval step. However for relatability I did a San Francisco line within PGs essays for clarity and practical relevance
* Repeat test multiple times for increased statistical significance
Notes:
* Amount Of Recall Matters - The model's performance is hypothesized to diminish when tasked with multiple fact retrievals or when engaging in synthetic reasoning steps
* Changing your prompt, question, fact to be retrieved and background context will impact performance
* The Anthropic team reached out and offered credits to repeat this test. They also offered prompt advice to maximize performance. It's important to clarify that their involvement was strictly logistical. The integrity and independence of the results were maintained, ensuring that the findings reflect my unbiased evaluation and are not influenced by their support.
* This test cost ~$1,016 for API calls ($8 per million tokens)