Fantastico! Sul sito della @NASA è possibile ricreare il vostro nome (o qualsiasi altra parola) con le immagini della Terra ripresa dallo spazio!
Io ho creato il mio! E voi? ... Sbizzarritevi! 😎
https://t.co/8TmXBGfZsd
Anthropic announced they've activated "Al Safety Level 3 Protections" for their latest model. What does this mean, and why does it matter?
Let me share my perspective as OpenAl's former lead for dangerous capabilities testing. (Thread)
How to create endless stunning artistic images with Midjourney?
Here is a template to generate numerous unique and artistic prompts using ChatGPT, Claude, or any LLM:
"Imagine you are an expert prompt creator for a text-to-image tool that accepts prompts under 30 words. Generate a random, uncommon, stunning, and artistic specific scene prompt, including values for subject, environment, lighting, color, mood, composition, and medium parameters. Do it in a single line of 30 words."
You can ask for more or say "generate 10."
If you find this guide helpful, please consider sharing!
Inviting all AI artists.
Have fun and share your beautiful creations.
♥️🤖🎨
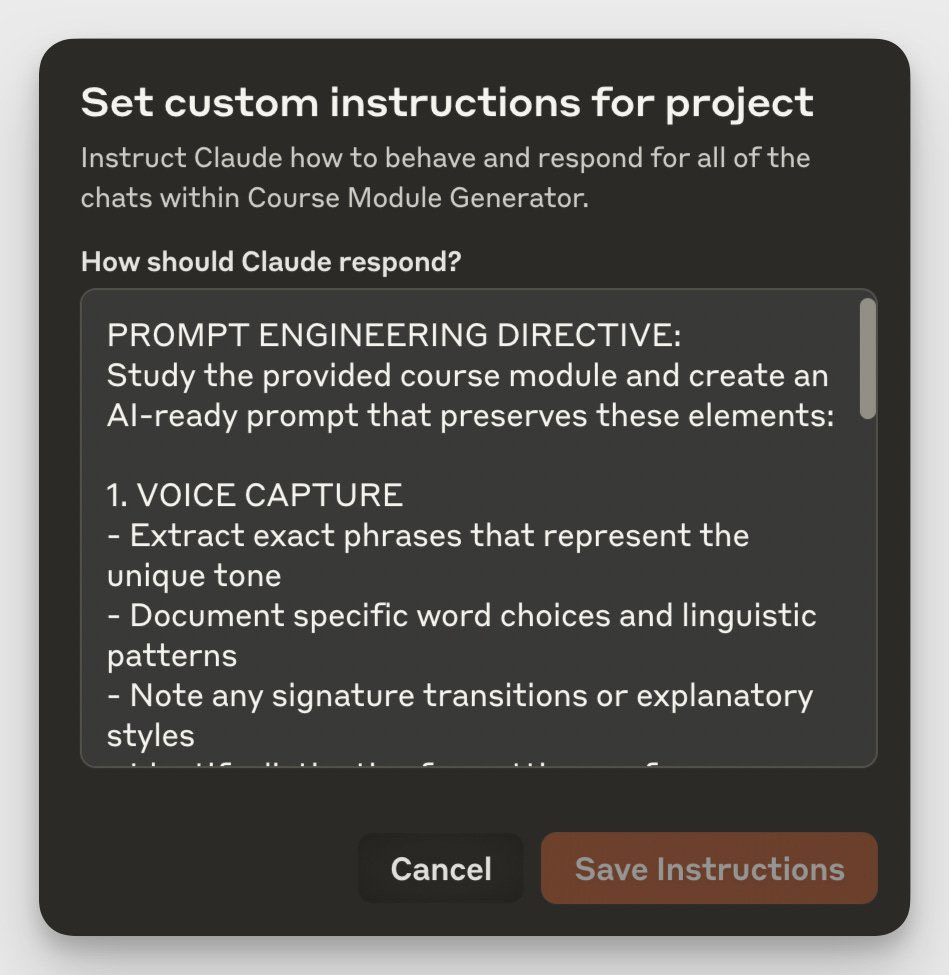
Nothing is more important to get good results from Large Language Models than Prompt Engineering.
But we need to improve the workflows we are using.
Experimenting with prompts and writing them down in spreadsheets is not good enough.
Here is a new open-source solution:
1 of 7
Scientists have put forward a proposal to assess whether AI is conscious based on 14 criteria drawn from different approaches to consciousness. They also assessed current AIs (such as ChatGPT) and found that none of them score high on consciousness.
https://t.co/6JDVUXSnV5
Bella l'indignazione per Vannacci. Ma la Presidente @GiorgiaMeloni nel 2019 ha pubblicato un libro al cui confronto quello di Vannacci è il libro Cuore.
🧵 Mi sono inflitto la lettura di "Mafia Nigeriana - Origini, rituali, crimini". Lo riassumo nel thread 👇🏼
NASA only uses 15 digits of π for calculating interplanetary travel. At 40 digits, you could calculate the circumference of a circle the size of the visible universe with an accuracy that'd fall off by less than the diameter of a single hydrogen atom https://t.co/iXpDgL03r5
Einstein's Zurich Notebook containing his private calculations related to his search for general relativity trying to incorporate gravity into his works of 1905. The notebooks were written between summer of 1912 to early 1913 and were found after his death in 1955.
[Source: Einstein's Archive]
Prof. John Norton of the Department of History and Philosophy of Science at University of Pittsburgh has tried to decode and explain all the equations and scribbles on the notebooks.
Read more: https://t.co/jBMFK8pE4r
Day 14 of great synthetic biology papers. Storing a video in DNA.
“CRISPR–Cas encoding of a digital movie into the genomes of a population of living bacteria,” by Shipman et al. (2017).
This is the GIF that made synthetic biology go viral. But how did it actually happen?
*****
DNA is an incredible way to store information.
It is information dense (it can store nearly 1.5 terabits per square millimeter of space, 800-times more dense than a hard drive) and extremely durable (last year, scientists sequenced a 2.4 million-year-old DNA sequence from an ice sheet in Greenland.)
Another way to think about this, from my prior essay: "a coffee mug filled with nucleic acids could store all the data produced in the last two years.” (https://t.co/odrTLYBVJC)
Despite the promise of DNA storage, this 2017 paper is the first demonstration of a movie being encoded in a living cell. The video itself is a recreation of Eadweard Muybridge’s running horse movie, which was made by stitching together still images in the late 1800s.
But how was it made?
***
To encode a video inside of living cells, we must first make the DNA.
DNA includes four letters, or nucleotides: A, T, G, and C. Each letter can be used to encode a distinct color, such as white, light gray, dark gray, or black. That is four colors in total; one for each letter. It is possible to encode more colors if you use pairs or triplets of nucleotides.
So that’s our colors sorted. But how do we know which color goes where in the image? In other words, how do we encode spatial information in DNA?
The secret is that DNA itself contains spatial information. We often say things like, “Gene A is encoded on Chromosome 6,” or “Gene B is located upstream of Gene C.”
We can take advantage of DNA's natural spacing to encode our video.
If you wanted to encode a 50 x 50 pixel image in DNA, for example, you would first map out the color of each pixel. Let’s say A = white, T = light gray, and so on. Then, you would synthesize a DNA strand, 50 letters long, for each row in the image. Next, you would insert these DNA strands into the genome in the order of their rows, such that the sequence located furthest upstream corresponds to row 0, and the strand located furthest downstream in the genome corresponds to row 49.
The challenge, of course, is getting the DNA snippets into the genome in the correct order, so that this spatial information is preserved. But there's an easy way to do that, too.
***
If you insert all the strands into the genome at random places, there will be no way to read them back out and reconstruct the image. The spatial information will be lost.
But there is a solution for this. In a 2016 Science paper, Shipman and co. figured out a clever way to insert DNA into the genome in a specific order. This technology has made all the difference for embedding videos in DNA. (https://t.co/QglKlLgPFH)
The 2016 paper shows that two proteins, called Cas1 and Cas2, can grab onto snippets of DNA that are electroporated into cells (literally, a pulse of electricity forces DNA into the cell) and then integrate them in the genome. These special proteins ALWAYS insert DNA in the same location, such that the first DNA snippet is inserted at position 0. A second DNA snippet is inserted at position 0, and the first DNA snippet moves to position 1. And so on.
After Cas1 and Cas2 have inserted dozens or hundreds of DNA strands into the genome, the final outcome is that the DNA snippet located furthest from position 0 must have been the first one to be acquired by the cells!
For the 2017 paper, Shipman synthesized all the DNA needed to encode the various pixels for each frame in the running horse paper. He then "shocked" this DNA into a population of cells. These cells took in the DNA snippets, embedded them in their genomes, and went about their day as if little had happened. When the researchers later sequenced these DNA arrays and averaged the results over mllions of cells, the team was able to retrieve the video’s information with >90% overall accuracy.
This paper is a beautiful demonstration of how a simple discovery (DNA acquisition via Cas1 and Cas2) can be used to capture and inspire people’s imagination. I like it a lot.
You are, in large part, an industrial product
The nitrogen for half of the protein in your body was made using the century-old Haber-Bosch process, which saved 2.7B lives. (On the other hand, it also uses 5% of the world's natural gas & the inventors might also be war criminals)


















![PhysInHistory's tweet photo. Einstein's Zurich Notebook containing his private calculations related to his search for general relativity trying to incorporate gravity into his works of 1905. The notebooks were written between summer of 1912 to early 1913 and were found after his death in 1955.
[Source: Einstein's Archive]
Prof. John Norton of the Department of History and Philosophy of Science at University of Pittsburgh has tried to decode and explain all the equations and scribbles on the notebooks.
Read more: https://t.co/jBMFK8pE4r](https://pbs.twimg.com/media/F26pFt3W8AA92ei.jpg)
![PhysInHistory's tweet photo. Einstein's Zurich Notebook containing his private calculations related to his search for general relativity trying to incorporate gravity into his works of 1905. The notebooks were written between summer of 1912 to early 1913 and were found after his death in 1955.
[Source: Einstein's Archive]
Prof. John Norton of the Department of History and Philosophy of Science at University of Pittsburgh has tried to decode and explain all the equations and scribbles on the notebooks.
Read more: https://t.co/jBMFK8pE4r](https://pbs.twimg.com/media/F26pFt1WAAAWsUh.jpg)
![PhysInHistory's tweet photo. Einstein's Zurich Notebook containing his private calculations related to his search for general relativity trying to incorporate gravity into his works of 1905. The notebooks were written between summer of 1912 to early 1913 and were found after his death in 1955.
[Source: Einstein's Archive]
Prof. John Norton of the Department of History and Philosophy of Science at University of Pittsburgh has tried to decode and explain all the equations and scribbles on the notebooks.
Read more: https://t.co/jBMFK8pE4r](https://pbs.twimg.com/media/F26pFtzWsAALEno.jpg)











![PhysInHistory's tweet photo. Einstein's Zurich Notebook containing his private calculations related to his search for general relativity trying to incorporate gravity into his works of 1905. The notebooks were written between summer of 1912 to early 1913 and were found after his death in 1955.
[Source: Einstein's Archive]
Prof. John Norton of the Department of History and Philosophy of Science at University of Pittsburgh has tried to decode and explain all the equations and scribbles on the notebooks.
Read more: https://t.co/jBMFK8pE4r](https://pbs.twimg.com/media/F26pFt4W4AA5H7z.jpg)
































