3) “TAPAS: Weakly Supervised Table Parsing via Pre-training” by Google AI
Introduced a model that extends BERT’s architecture to work with tabular datasets. https://t.co/sy32kI1gv8
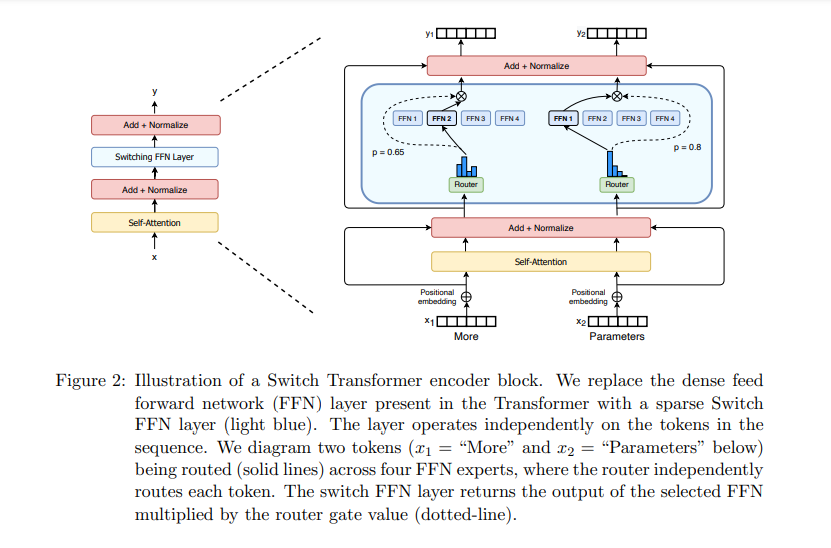
2) “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity” by Google AI
Introduced the biggest transformer model ever built with over one trillion parameters. https://t.co/4qdujsTs0g
3 research papers you should read to understand Transformers 🦾 better.
1. "Attention is All You Need" @GoogleAI that started the transformer revolution
2. Switch Transformers @GoogleAI
3. TAPAS @GoogleAI
A Thread 🧵👇
"The effectiveness of BERT arises from:
1. Pre-training over large amounts of raw textual data via self-supervised learning
2. Crafting rich, bidirectional feature representations of each token within a sequence"
Learn more from @cwolferesearch's post. https://t.co/kqRILMUpxm
We trained a transformer called VIMA that ingests *multimodal* prompt and outputs controls for a robot arm. A single agent is able to solve visual goal, one-shot imitation from video, novel concept grounding, visual constraint, etc. Strong scaling with model capacity and data!🧵
New release of @huggingface transformers includes a new pipeline called Document Question Answering ❓📄
This is a pipeline you can use to extract information from PDFs! Let's take a closer look 👀