I just sequenced a human genome to 30× coverage entirely at home.
As far as I know, this is the first time this has been done.
I didn’t step foot in a lab once. Every step - from saliva collection, to running the sequencer - took place in a single room with a dining table + kitchenette.
Six weeks ago, I had never done wet lab biology before.
I used an Oxford Nanopore P2 Solo - the only commercially available sequencing device portable enough to do 30x human genome sequencing at home.
Biggest takeaway - I could build something that combined software, hardware, and molecular biology far faster than I thought was possible.
I can name >100 specific instances where AI helped me solve a technical problem that would previously have blocked me because I lacked access to a domain expert.
For example: how do I save my sequencing run when my DNA extraction yield is 4x lower than I need it to be, and I have this limited set of reagents to hand?
To make this work, I had to navigate multiple disciplines:
- writing software to monitor sequencing runs and orchestrate remote GPU infra for basecalling
- learning + executing 5 hour long molecular biology protocols
- building a hardware device to quantify DNA concentration
Apologies for the hyperbole, but I feel super lucky to be living in 2026.
A few weeks ago I decided to sequence a human genome to 30x at home.
Then I actually did it. And I did it really quickly.
Pakistan may be accidentally building one of the world’s first decentralised #solar economies. The craziest part? Real scale barely shows in official stats. Imported 51.5 GW solar panels by late 2025—nearly = entire grid. Yet registered net-metered rooftop solar just 5.3–6.8 GW.
What makes this story so extraordinary is the speed.
In only a few years, Pakistan appears to have gone from a relatively minor solar market to potentially sourcing around a quarter of its electricity from solar once distributed generation is included.
👉 ~16.6–17 GW solar imports in 2024
👉 ~18 GW solar imports in 2025
👉 ~51.5 GW cumulative imports by late 2025
👉 Rooftop solar: ~1.3 GW → 4.1 GW in 2024
👉 ~5.3–6.8 GW registered rooftop solar in 2025
👉 24+ GW estimated behind-the-meter/off-grid
👉 Solar potentially ~25% of actual electricity use
The massive gap between imported panels and officially registered systems strongly suggests tens of gigawatts are now operating quietly on homes, farms, factories and businesses across the country.
This increasingly looks less like a normal energy transition and more like large-scale consumer-led grid defection.
And economics is driving nearly all of it.
Electricity tariffs surged. Diesel prices climbed. Blackouts remained common. Meanwhile ultra-cheap Chinese solar panels and falling battery prices made self-generation economically irresistible.
So millions effectively made the same calculation:
Generate your own power, or remain trapped inside an expensive and unstable system.
Once solar becomes cheaper than the grid itself, adoption can move faster than governments, utilities and even official statistics can keep up with.
This isn’t gradual transition by any stretch. It may ultimately become a blueprint for how energy-poor nations break free from legacy old-world energy systems dominated by fossil fuels and increasingly expensive centralised power.
It’s decentralisation at escape velocity.
This is #Bettrification.
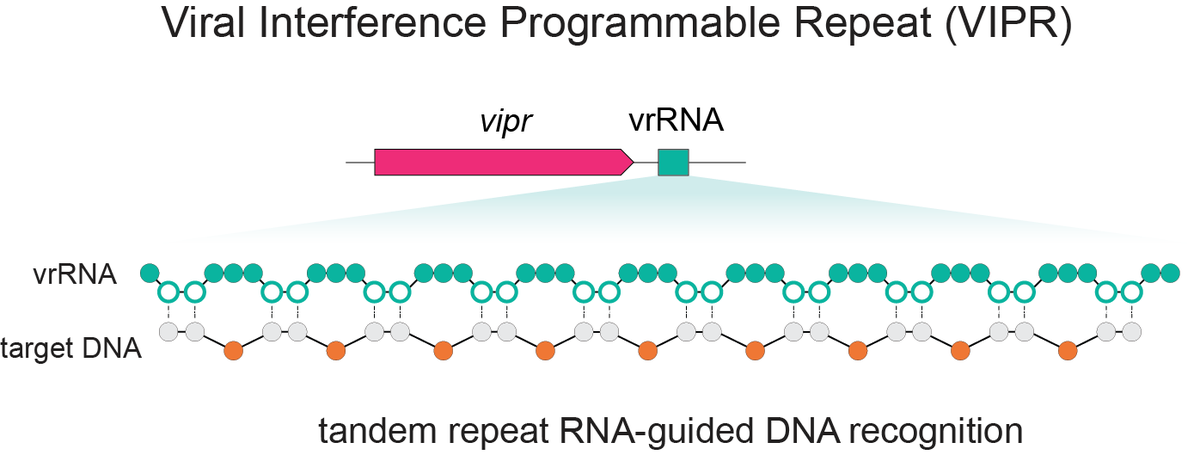
Excited to share our discovery of a new programmable RNA-guided DNA-targeting system hiding inside bacteriophages that predates CRISPR.
We call it VIPR (Viral Interference Programmable Repeat), and it uses an entirely new logic to find its targets.
Thread + link below.
Two Pakistani candidates Muhammad Zeeshan Ali and Khurram Daud have been selected as the first foreign astronauts to train for China's space station missions, the China Manned Space Agency announced on Wednesday. #XinhuaNews
Following on from Kitchen table genomes/liquid biopsy. There are two forces at work, a centralization one and a decentralization one. Large companies are trying to trap everything in central data centers with proprietary data streams, giving them a moat and control, others are pushing to run AI and other things locally empowering individual users. Same is happening to bio/medical data including sequencing.
I sequenced my genome at home, on my kitchen table.
I wrote up exactly how I did it - the equipment, protocol, theory, and cost:
https://t.co/Nkjqaho2zm
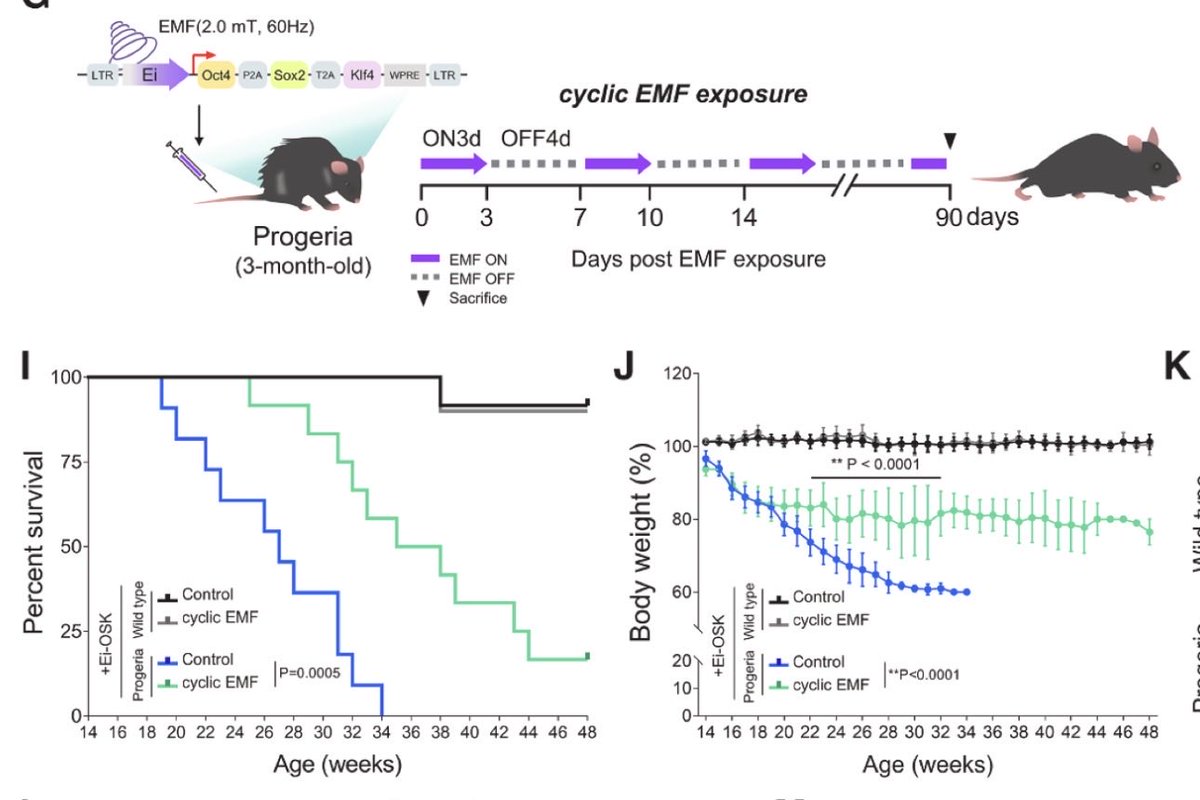
REMOTE CONTROL MICE! A group from Seoul has just published in Cell that they’ve discovered a crazy-weird protein (Cyb5b) that can be used to turn on any gene when exposed to EMFs!
They used it to turn on OSK and extend the lifespan of a progeroid mouse. More to come on this…
🇦🇺An Australian tech founder with zero biology background sequenced his dog’s tumor DNA, then used ChatGPT and AlphaFold to design a custom mRNA cancer vaccine.
A month later, the tumors shrank by half.
And this is just the start of AI medicine.
I recently learned that RNase A enzymes can survive autoclaving, or high-pressure heating, at 121°C. This is strange.
But then I learned there are entire organisms that not only survive autoclaving, but actually grow and divide at 121°C???
There was a 2003 paper, for example, where these two scientists took a submarine down to a hydrothermal vent in the Pacific ocean, scooped up some dirt, and kept everything in an airtight tube.
This tube had an organism in it. The organism had features "typical of Archaea." They put this organism into an autoclave (held at 121°C) for a full 24 hours. When they took it out of the autoclave, the cell population had doubled. Thus, the organism was called "Strain 121."
The 2003 paper ends with an enticing statement:
"The factors that permit strain 121 to grow at such high temperatures are unknown. It is generally assumed that the upper temperature limit for life is related to the instability of key molecules essential for life, but which molecules are most important in defining the upper temperature limit have not been defined. However, strain 121 offers the possibility to do this work."
I read this and got excited. I began searching for follow-up studies on Strain 121. But I was quickly disappointed.
This organism has its own Wikipedia page, but every single reference is from 2003 or 2004. Its name was later changed to Geogemma barossii, so I searched for that, too. But all I could find were random news stories about this "heat-loving microbe," all of which linked back to the original 2003 paper.
I'm extremely confused by this. Why is nobody studying this microbe? It doesn't even have a published genome sequence. Where is the intellectual center for hyperthermophile research?
Evo 2, our fully open-source biological foundation model trained on trillions of DNA tokens spanning the entire tree of life, is out in @Nature today
We & the scientific community have done a lot with this @arcinstitute@nvidia model in the last year! 🧵👇
When you're deciding what to study in college, don't try to predict what will be valuable in the future, because that's so hard that you'll probably get it wrong. Instead focus on what you personally find most exciting. You can't get that wrong.