1/
A 5M-parameter model just beat frontier LLMs on hard logical puzzles at less than 1/100,000th of the inference cost.
How? By scaling test-time compute in continuous latent space rather than discrete token space.
Let's unpack how this works. 🧵
What if attention were code? We show that many attention heads in transformer LMs can be replaced by human-readable Python programs.
Swap them in and the model barely notices.
See our experiments here: Explaining Attention with Program Synthesis [https://t.co/tkFopEYtaV]
The human brain is strikingly modular, with distinct networks for language, formal reasoning, social reasoning, and physical reasoning. Is this a fundamental principle of how intelligent systems are built, or an accident of biological evolution?
In our latest preprint, we find that a similar modular organization emerges in Large Language Models, another class of intelligent system.
Brains and LLMs are shaped by entirely different kinds of optimization (biological evolution vs. gradient descent). That they arrive at the same modular design anyway suggests modularity may be a fundamental property of intelligent systems.
🌐 Web: https://t.co/ZKrnTSSuSf
📄 Paper: https://t.co/ZibBXz3PUy
💻 Code & data: https://t.co/uBo5iOYNjy
Using circuit analyses across 46 tasks spanning four cognitive domains, we find:
1️⃣ Tasks that draw on the same network in humans recruit overlapping units in LLMs, while tasks drawing on different networks recruit distinct units.
2️⃣ These units are causally linked to model behavior. Ablating the units critical for one domain impairs performance in that domain (−26% accuracy) but barely touches the others (−2.5%).
This project has been in the works for a while :) Huge thanks to my advisors @jacobandreas@ev_fedorenko@devarda_a, and to @Nancy_Kanwisher for valuable conceptual input and feedback throughout. #MIT
Probably 10x better than any of the eduslopppp bullshit you'll find in the 15 min threads with 2k bookmarks that have been put out in the past year truth be told. The best way to learn will always be to just sit down and read and reread and reread again
https://t.co/Rz14zg9OdL
Sorry, I just saw this, @taskinfatih. Thank you @aimalysheva for asking...
even though I might disappoint you.
I may be missing part of the intended argument, but I would be cautious about interpreting this as evidence for a universal language manifold shared by humans and LLMs.
“King” and “queen” are semantic objects observed at the physical-cover level. Their apparent vector relation does not necessarily reveal a pre-existing universal manifold underneath. Their representations are produced by an iterated integral through the network, with the input text acting as the boundary condition.
A reasoning trace is therefore better understood as a computation-generated pathway through stacked representations, rather than simply a curve moving along a fixed low-dimensional semantic surface. The Linear Representation Hypothesis identifies locally consistent relations, such as the direction from “king” to “queen,” but this alone does not establish one universal language manifold.
This may be why the idea is so difficult to understand: everything is dynamic. The input changes the boundary condition, each layer changes the representation, and the reasoning path is created during computation. We keep looking for one fixed manifold, but the geometry itself is moving.
Hope this helps....
please see ** Single Token Geometry 06: Stacked Piecewise Manifold **
https://t.co/tWkscGX2F5
I'm fairly convinced there's some universal language manifold (= a surface formed by meaning vectors) that both humans and LLMs operate on. But we don't train LLMs to explicitly represent this manifold. We rather train them to approximate it, and to move along it by building curves on it.
And those curves are reasoning in geometric terms, like a reasoning trace is a curve on a low-dimensional manifold embedded in a very high-dimensional space.
The Linear Representation Hypothesis (https://t.co/2p3HZEGhX0) touches this, but I wonder if there's more recent work that takes the manifold idea further?
Would love to see takes from people with serious differential geometry backgrounds on this!
10/ There are a few rough edges: it's not lossless, iterative compaction isn't free extrapolation (training horizon matters a lot), and exact needle retrieval is still hard. But we've made many improvements to the architecture and training process since we wrote this paper, and are excited to share these soon.
Regardless, the core result holds: amortization makes long-context compaction tractable. Huge shoutout to @alexsandomirsky, @part_harry_, @mudithj, @maxkirkby and the rest of the Baseten research team for their work on this!
Paper: https://t.co/akNs8gAIFg
1/ You can shrink a language model's KV cache by 200×, in a single forward pass, and it still answers correctly.
At 256k context that's 36 GiB of cache down to ~360 MiB, with no change to the base model.
Here's how we did it 👇
// Self-Harness: Harnesses That Improve Themselves //
(bookmark this one)
Most of the agent scaffolds we rely on today are built once and remain frozen or mostly unchanged.
The harness, like the skills, needs to evolve with new models.
What if the scaffold rewrites itself?
This new work treats the harness, the prompts, tools, and control flow around the model as a learnable artifact that improves from its own runs rather than staying a fixed wrapper you hand-maintain.
The scaffolding becomes the part that compounds, run after run. If you run long-horizon agents, a self-modifying harness turns scaffold upkeep from manual work into something the system earns on its own.
Paper: https://t.co/byh1MP99xU
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Gradient descent on neural networks frequently drives the sharpest Hessian eigenvalue to exactly 2/learning_rate. This is the Edge of Stability. For five years, ML theory has failed to explain why this happens globally from any initialization. Until now. 🧵
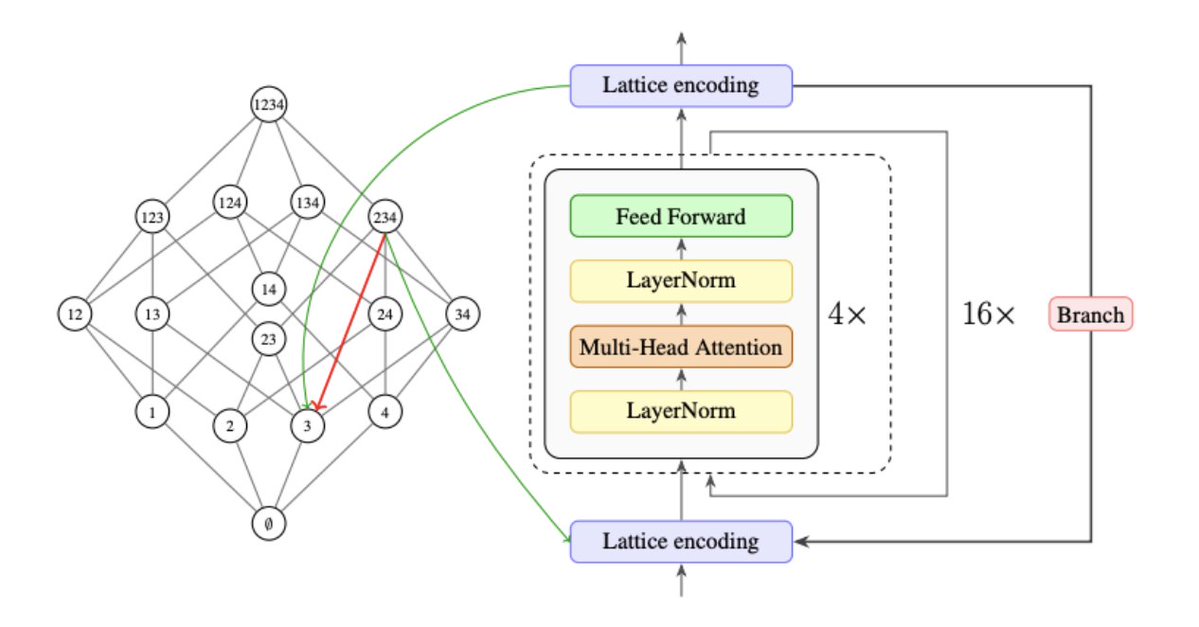
Introducing Lattice Deduction Transformers: An 800k-parameter looped transformer that reasons like a SAT solver achieves 100% on Sudoku-Extreme with only 15 minutes of training.
A collaboration between @axiommathai, @AmherstCollege and @BarnardCollege.
What if you could speed up AI image generation by 22x without retraining from scratch?
Researchers from Zhejiang University and the University of Adelaide introduce FlashAR.
They add a lightweight vertical prediction head to existing autoregressive models, enabling parallel two-way next-token prediction. This preserves the original training objective while dynamically combining horizontal and vertical predictions.
Result: up to 22.9x speedup for 512x512 image generation, using just 0.05% of the original training data.
FlashAR: Efficient Post-Training Acceleration for Autoregressive Image Generation
Project: https://t.co/SX3AzDmHKS
Paper: https://t.co/AAioG5WRic
Code: https://t.co/baNSMUVYYD
Our report: https://t.co/gBRu5ktZ4q
📬 #PapersAccepted by Jiqizhixin
Training an LLM from scratch is easier to study when the whole path is in one repo.
Train LLM From Scratch is a PyTorch repository for learning how a transformer language model is built, trained, saved, and used for text generation.
It helps you move from “I understand attention on paper” to a runnable training pipeline by pairing model code with data download, preprocessing, config, training, and generation scripts.
Key features:
• Transformer components from scratch – separate PyTorch modules for MLP, attention, transformer blocks, and the final model
• Pile-based data path – scripts download The Pile files and preprocess JSONL.ZST text into tokenized HDF5 datasets
• Configurable training setup – model size, context length, heads, blocks, batch size, learning rate, and file paths live in https://t.co/zuPqaR3MhP
• Hardware guidance – README compares common GPUs for 13M and 2B-class training runs
• Generation workflow included – generate_text.py loads trained checkpoints and produces sample text outputs
It’s open-source (MIT license).
Link in the reply 👇
Local minima are rare in high dimensions because a strict local minimum has to curve upward in every direction, so all Hessian eigenvalues must be positive.
In a D-dimensional toy model where eigenvalue signs are independent, that’s a 2^(-D) event. In GOE-like random matrix models, positive definiteness is even rarer, roughly exp(-cD^2).
So as dimension grows, random critical points are much more likely to be saddles than minima. This is one reason high-dimensional optimization is often a saddle-escape problem, not a bad-local-minimum problem.
Wrote up some of the math here: https://t.co/vkaVqVD64N
// Memory as Connectivity //
One of the cleaner reframings of agent memory I have seen this month.
FluxMem treats memory as the continuously evolving topology of a heterogeneous graph.
Three stages run together: initial connection formation, feedback-driven refinement, and long-term consolidation of recurrent successful trajectories into reusable procedural circuits. During execution, it repairs missing links, prunes interference, and aligns abstraction granularity.
SOTA on LoCoMo, Mind2Web, and GAIA across three distinct memory regimes.
Paper: https://t.co/uNrdgGX4jC
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Introducing DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation
https://t.co/c9AvsRKybj
What if we didn’t have to hold an entire neural network in memory to train it?
Standard neural net training optimizes all parameters jointly. As a result, the memory required during training grows linearly with the depth of the network.
In our #ICLR2026 paper, we propose DiffusionBlocks, a principled framework to train networks one block at a time, drastically reducing memory requirements while matching end-to-end performance.
With DiffusionBlocks, we split the network into blocks and train them one at a time, so you only need memory for a single block.
How? We explicitly assign each block a role: to move the representation a little closer to the target than the block before it did. That role turns out to be precisely what a diffusion model does, step by step. Each block only needs to optimize its own objective and can be trained independently.
We validated this across five different architectures:
• ViT
• DiT
• Masked diffusion
• Autoregressive transformers
• Recurrent-depth transformers
In each case, performance is competitive with end-to-end training while using a fraction of the memory.
This perspective also extends naturally to recurrent-depth (Looped) transformers, which apply the same network iteratively and normally require expensive backpropagation through time (BPTT). Viewed through DiffusionBlocks, we can replace those multiple iterations with a single forward pass during training.
Read our paper and code, to learn more.
Paper: https://t.co/CRj96VGYQn
GitHub: https://t.co/eNW0K9Xh8E
🐟