We implemented @karpathy 's MicroGPT fully on FPGA fabric.
No GPU.
No PyTorch.
No CPU inference loop.
Just a transformer burned into hardware, generating 50,000+ tokens/sec.
The model is small, but the idea is not: inference does not have to live only in software 👇
Imagine every pixel on your screen, streamed live directly from a model. No HTML, no layout engine, no code. Just exactly what you want to see.
@eddiejiao_obj, @drewocarr and I built a prototype to see how this could actually work, and set out to make it real. We're calling it Flipbook. (1/5)
London, we’re taking the next step! 🚙 We’re officially beginning autonomous driving with a trained specialist behind the wheel. We can’t wait to offer Londoners a quiet, convenient, and magical way to connect to the Tube, bus, or their final destination later this year.
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: https://t.co/NlAfEJjtJV
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Computer use is now in Claude Code.
Claude can open your apps, click through your UI, and test what it built, right from the CLI.
Now in research preview on Pro and Max plans.
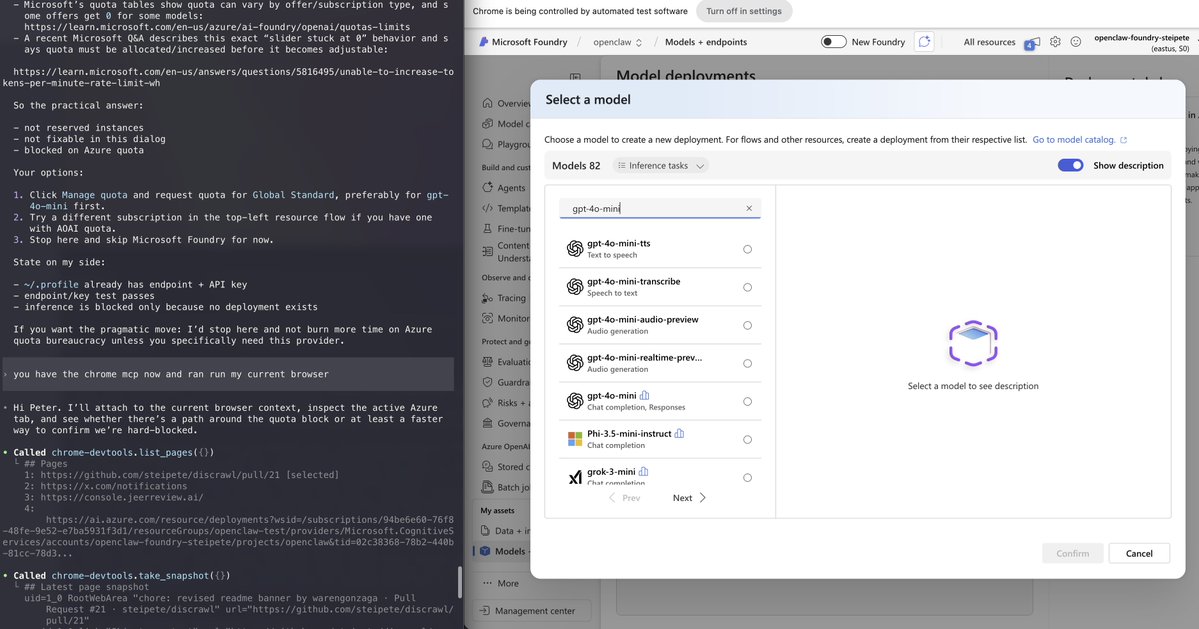
Testing a new feature for Microsoft Foundry support in @openclaw. Their website is a jungle, I used to make screenshots so codex can guide me through it, but now Chrome has an MCP so codex can simply connect and drive my browser session and do all of that for me.
The human is no longer the bottleneck.
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project.
This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.:
- It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work.
- It found that the Value Embeddings really like regularization and I wasn't applying any (oops).
- It found that my banded attention was too conservative (i forgot to tune it).
- It found that AdamW betas were all messed up.
- It tuned the weight decay schedule.
- It tuned the network initialization.
This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism.
https://t.co/WAz8aIztKT
All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges.
And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.
I think it must be a very interesting time to be in programming languages and formal methods because LLMs change the whole constraints landscape of software completely. Hints of this can already be seen, e.g. in the rising momentum behind porting C to Rust or the growing interest in upgrading legacy code bases in COBOL or etc. In particular, LLMs are *especially* good at translation compared to de-novo generation because 1) the original code base acts as a kind of highly detailed prompt, and 2) as a reference to write concrete tests with respect to. That said, even Rust is nowhere near optimal for LLMs as a target language. What kind of language is optimal? What concessions (if any) are still carved out for humans? Incredibly interesting new questions and opportunities. It feels likely that we'll end up re-writing large fractions of all software ever written many times over.
New Engineering blog: We tasked Opus 4.6 using agent teams to build a C compiler. Then we (mostly) walked away. Two weeks later, it worked on the Linux kernel.
Here's what it taught us about the future of autonomous software development.
Read more: https://t.co/htX0wl4wIf