pleased to share 'DiffLogic CA', made of the finest blend of NCA and binary-gate circuits! adopting @FHKPetersen's differentiable circuit learning, we learn *stateful* circuits, recurrent in space & time. by @PietroMiotti, me, @zzznah, @RandazzoEttore 1/5 https://t.co/DKGo4W16cH
How well can a model watch a short video of some physical dynamics and actually predict what happens next?
Introducing MPMWorlds: a new dataset and benchmark to evaluate how well models can reconstruct and extrapolate physical dynamics from video.
https://t.co/w6Yz8S5xBg
🧵👇
(1/n)
Just finished listening—a fantastic discussion on the evolution and future of AI at Google. I was also thrilled to hear @sundarpichai highlight our research moonshot Project Suncatcher and the incredible work my team is doing to explore the frontiers of data centers in space.
The Bitter Lesson and Artificial Life. Everything we know about (1) scaling laws in AI (2) how to discover the ideal abstraction basin in scientific simulations suggest that the next big breakthrough in ALIfe will come from massive training runs first and massive theoretical breakthroughs second.
After automating AI research with @SchmidhuberAI and building AI Scientists at DeepMind, now comes the real experiment: the institution itself.
Excited to co-found @inherent_labs: the recursively self-improving lab for scientific AI.
https://t.co/SQjUduaG3D
My babies are getting so smart, it's freaking me out.
I was looking forward to using GA or bayesian optimisation to find a sweet set of parameters, but hand-tuning is giving scarily good results. I cant stop watching!
(No global coordinator, all acting entirely on local cues)
For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (https://t.co/PK5h0mqQSo), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
Found something in my daily use of Claude Code that validates our Memento results:
Claude Code flushes the KV cache after some idle period, and when I come back past that the model is noticeably harder to work with.
Conjecture: post-flush, the model is no longer continuing its trajectory. It's shoved into a weird OOD regime where it has to simulate what has happened from the tokens and resume from a reconstruction.
Which is much harder than just continuing!!
We measured this effect in our paper. KV states (soft embeddings) carry information that text tokens don't, even when attention is masked.
Bottom line: If you flush your cache you lose a lot of accuracy!
Our work goes beyond just ‘an analysis’.
By combining microfluidic experiments with theoretical modeling, we discovered the actual mechanism: E. coli perform recurrent, neural-like computation to navigate the physical trade-off between immediate growth and future survival.
Excited to co-found Recursive (@recursive_si) with an exceptional team in London and SF to create AI that experiments on how to safely improve itself, turning compute into knowledge that accumulates in an open-ended process of endless, automated scientific discoveries.
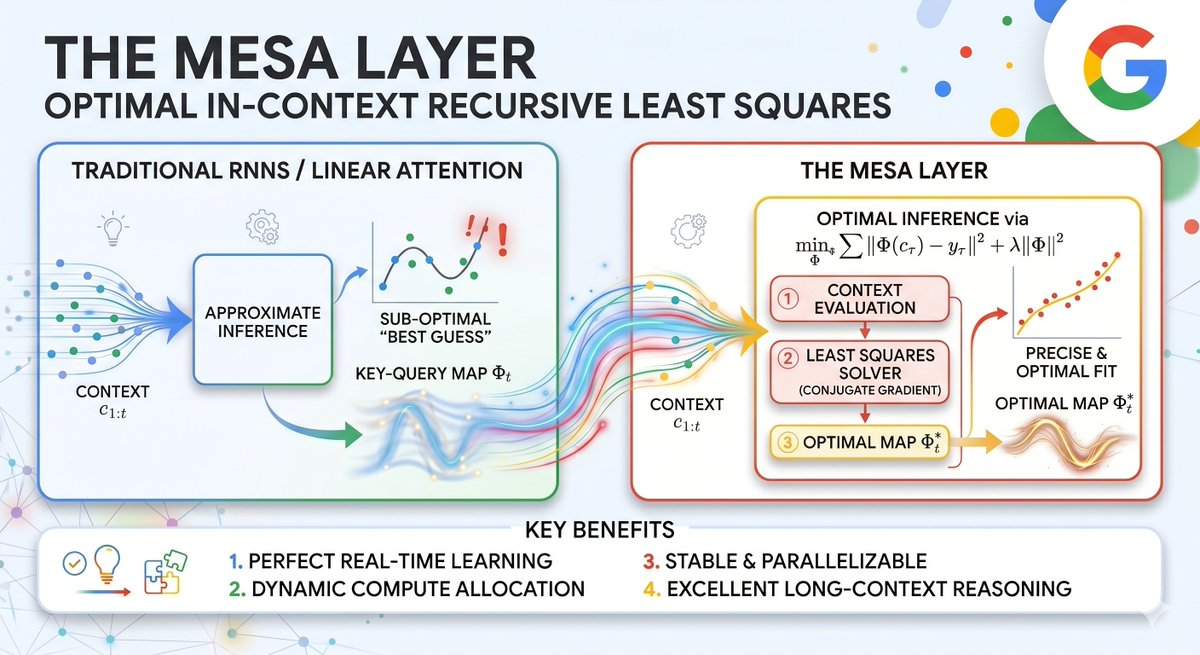
Google presents a new Transformer alternative at #ICLR2026! Join Nino Scherrer & Yanick Schimpf at the Google booth (#411) at 10AM to learn about MesaNet, proposing a new linear sequence layer that optimally learns in-context given a fixed memory budget.
Imagine every pixel on your screen, streamed live directly from a model. No HTML, no layout engine, no code. Just exactly what you want to see.
@eddiejiao_obj, @drewocarr and I built a prototype to see how this could actually work, and set out to make it real. We're calling it Flipbook. (1/5)
Natural evolution's open-endedness leads to beautiful, complex emergent structures and self-organizing behavior 🌱✨. Replicating this in silico is famously hard 💻. Our paper points to a promising direction by evolving populations of competing neural cellular automata with lifelike behavior 🧬🤖 #Isambard
⚠️⚠️flashing lights, rapid cuts, or strobe effects in this thread! 🚨🚨
1/n
So fun watching looped transformers taking off this week! Worth mentioning that @AngelikiGiannou & @shashank_r12 coined the term and gave a beautiful looped construction of an assembly-like computer in Jan 2023 https://t.co/VZiwKY4s2I
What happens when you put competing neural networks in a Petri Dish and start changing the rules while they adapt?
Last year we released Petri Dish NCA, where neural nets are the organisms that learn during simulation. Today we're releasing Digital Ecosystems: a browser-based platform for interactive artificial life research.
The setup: several small CNNs share a 2D grid, each seeing only a 3x3 neighborhood. No global plan. They compete for territory by attacking neighbours and defending against incoming attacks, learning via gradient descent online while the simulation runs.
What we didn't expect was the role of the learning itself. Gradient descent isn't just optimising each species' strategy. Instead, it acts to stabilize the whole system during simulation. Species that overextend get pushed back by the loss. Species that stagnate get nudged to grow. This means you can push parameters toward edge-of-chaos regimes: a zone characterised by emergent complexity. Letting the neural networks learn acts to hold the complex system together while you explore and interact.
The platform lets you steer all of this interactively. You can draw walls to create niches, erase parts of the system online, and tune 40+ system parameters to explore the most interesting configurations. We find it mesmerizing to watch species carve out territories and reorganise when you perturb them.
Everything runs client-side in your browser, no install needed.
Blog: https://t.co/qOuelxmd6l
Code: https://t.co/pz7ktDCRZS
Found a paper that suggests we may have spent years training agents to become hunters of proxy reward when the more basic thing intelligence craves is not a reward at all, but to not run out of viable futures.
The paper proposes that behavior is best understood as maximizing future action-state path occupancy, which collapses mathematically into a discounted entropy objective. The agent doesn’t necessarily want to GET something, but rather is trying to keep as many meaningful trajectories alive as possible.
The obvious objection is “so it just does random shit? fuck around and find out?”
No, this is where it gets pretty beautiful. The agent is variable when variation is cheap and becomes surgically goal-oriented the moment an absorbing state (death, starvation, falling over, etc) gets close enough to threaten its future path space.
Variability is the same drive as goal-directedness, just operating under different constraints.
The demos are kinda wild:
- A cartpole (classic move a cart to keep a pole from falling control task) that doesn’t merely balance but dances and swings through a huge range of angles and positions because why not? The whole point is occupying state space, and rigid balance is a voluntarily impoverished life.
- A prey-predator gridworld where the mouse PLAYS with the cat, teasing it and using both clockwise and counterclockwise routes around obstacles to lure it away from the food source before slipping in to eat, using both routes roughly equally. A reward-maximizing agent would collapse to one strategy and exploit it. Here, the agent keeps its behavioral repertoire
- A quadruped trained with Soft Actor-Critic and ZERO external reward that learns to walk, jump, spin, and stabilize, and then makes a beeline for food only when its internal energy drops low enough that starvation becomes a real threat
The thing that hit me hardest is the comparison to empowerment and free energy principle agents. Both collapse to near-deterministic policies with almost no behavioral variability. This paper’s agents find the highest-empowerment state and exploit it. FEP agents converge to classical reward maximizers.
As far as I’m aware, this is the only framework that produces agents you could describe as being “alive.”
The AI implication here is that we undertrain for behavioral repertoire. Most systems hit the benchmark by collapsing onto a narrow attractor basin of good-enough trajectories. They’re competent for sure, but brittle too, with one viable plan, executed until the world shifts and leaves them with nothing.
The thing I increasingly want from agents isn’t competence per se, but option-preserving competence.
I want agents with the ability to keep multiple viable plans alive and switch between them without catastrophe.
We’ve been so focused on teaching agents what to want that we never stopped to ask what happens if wanting isn’t the point, if the deepest drive isn’t necessarily toward anything, but away from the walls closing in.
paper: https://t.co/Kn3mllmmPK