Thrilled to see this work out in the world. 🚀
We’ve been building new frontier models for coding and reasoning, including MAI-Code-1-Flash and MAI-Thinking-1.
Model details:
MAI-Code-1-Flash: https://t.co/BvKDZwdORJ
MAI-Thinking-1: https://t.co/5qPiEJZV96
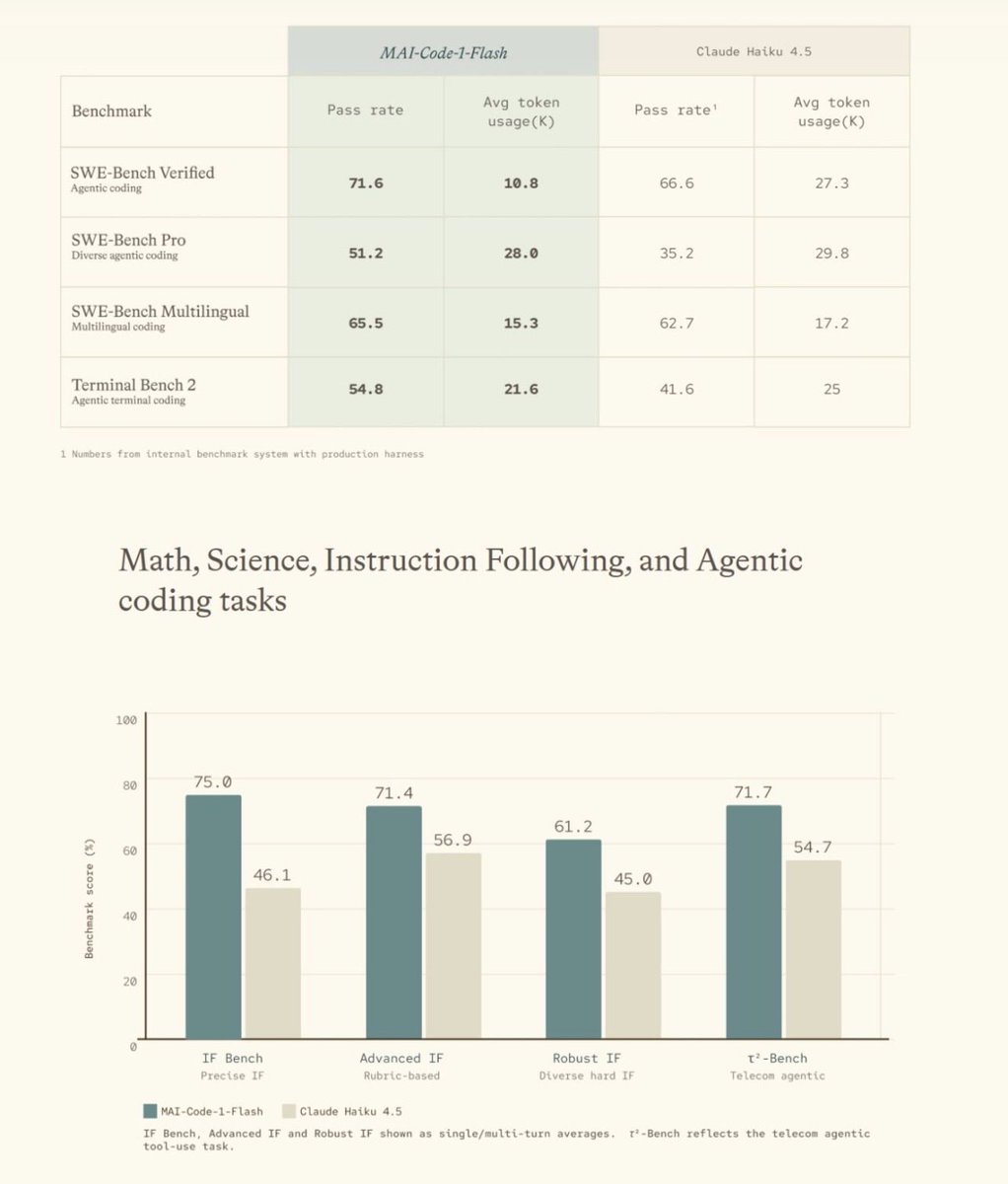
Excited to introduce our MAI Code model at Microsoft Build. As shared in the session, this is a MoE (5B active / 137B total) initialized from an MAI pretrained model and trained for real user scenarios with product harnesses. I’m proud to have served as the research lead for this effort, and even prouder of what the team has achieved. It’s a beast for its size. Stay tuned — a larger model could come :)
Language models often produce repetitive responses, and this issue is further amplified by post-training. In this work, we introduce DARLING, a method that explicitly optimizes for both response diversity and quality within online reinforcement learning!
Reasoning can be made much, much faster—with fundamental changes in neural architecture. 😮
Introducing Phi4-mini-Flash-Reasoning: a 3.8B model that surpasses Phi4-mini-Reasoning on major reasoning tasks (AIME24/25, MATH500, GPQA-D), while delivering up-to 10× higher throughput at 32K generation length with vLLM. 🤯
Model: https://t.co/bYFanHgikH
Codebase: https://t.co/M2GLiw3nUl
Blog: https://t.co/ka7yjL29HQ
Paper: https://t.co/lUF2xwYQWq
(1/8)
Fluent, fast, and fair—in collaboration with @MSFTResearch, Johns Hopkins computer scientists (including @fe1ixxu & @kentonmurray) have built a new machine translation model that achieves top-tier performance across 50 diverse languages. Learn more: https://t.co/4vBEEDWIgS
Glad to see the team used a 3.8B model (Phi-4-mini-reasoning) to achieve 94.6 in Math-500 and 57.5 in AIME-24.
arxiv: https://t.co/741JoHgK4m
hf: https://t.co/PVbW4jyJTu
Azure: https://t.co/V2QusWIAgc
🚀 Phi-4-Mini-Reasoning is finally out!
Two months ago, we introduced a reasoning-enhanced Phi-4-Mini. Since then, we've taken it further—a compact model with robust reasoning abilities that even surpass, models up to 2x its size.
Paper: https://t.co/GcSxxwVZX4
I'll be presenting our work, VocADT, tomorrow at #ICLR2025✨
Check out our poster session: https://t.co/bVOYMDQBnz
🗓️Thu 24 Apr 3 p.m. - 5:30 p.m
📍Hall 3 + Hall 2B #250
So excited to be attending @iclr_conf in Singapore🇸🇬
We also arxived #Phi-4-Mini technical report to cover our innovations for building strong lightweight multimodal model Phi-4-multimodal and language model Phi-4-mini.
We use mixture-of-LoRAs technique to combine text, image, speech modalities together without interference.
Excited to share that Phi-4-mini has been released!
This was my first time rolling up my sleeves and experiencing the entire text training process. We also have a reasoning-enhanced Phi-4—outperforming many 7B reasoning models—which we plan to release very soon. Stay tuned!
We released Phi-4-mini (3.8B base in LLM), a new SLM excelling in language, vision, and audio through a mixture-of-LoRA, uniting three modalities in one model. I am so impressed with its new audio capability. I hope you can play with it and share with us your feedback. We also trained a reasoning model, achieving 90.4 on Math-500.
Model: https://t.co/QJx65DtQPv
Paper: https://t.co/Jxktctw1pv
Blog: https://t.co/rzaA0x6e6I
Multilingual models are usually heavily skewed in favor of high-resource languages.
We change this with X-ALMA: an LLM-based translator committed to ensuring top-tier performance across 50 diverse languages, regardless of their resource levels!
Paper: https://t.co/O4M5LDGdAB
We wrapped up CS 8803 "Large Language Model" class at @GeorgiaTech for Fall 2024.
Here is the reading list:
• learning from human preferences (PPO, DPO, SimPO, CPO, RRHF, ORPO, CTO)
• real-world LLM (Llama-3, Aya, Arena's)
• efficient LLM (MoMa, LoRA, QLoRA, LESS)
Multilingual models are usually heavily skewed in favor of high-resource languages.
We change this with X-ALMA: an LLM-based translator committed to ensuring top-tier performance across 50 diverse languages, regardless of their resource levels!
Paper: https://t.co/O4M5LDGdAB