Si algú està interessat en seguir de ben a prop el projecte que tot just hem començat: Videojocs i Educació en català (https://t.co/lRmCgdJnoT) podeu seguir el compte @vjeducacio on publico tots els capítols nous, recursos, dossiers, articles, etc. #educació#videojocs#encatalà
🖥️ Què hem de fer si tenim el Windows 10 a l'ordinador, ara que sabem que deixarà d’actualitzar-se arreu del món a partir del dimarts 14 d'octubre?
🗣️ N'hem parlat amb @ferranadell, expert en Informàtica de la @UOCuniversitat
⬇️
https://t.co/5Lw78g14aH
Nou #tresvides3cat sobre Minecraft. Per què és bo pel cap jugar-lo? Per què no passa de moda? Sabíeu que hi ha una Catalunya alternativa a Minecraft (més real que allò de la República Digital)? En parlem amb l'@AlbertGarlo, @ferranadell i @CubecatOficial.
https://t.co/cdzEUTOY0t
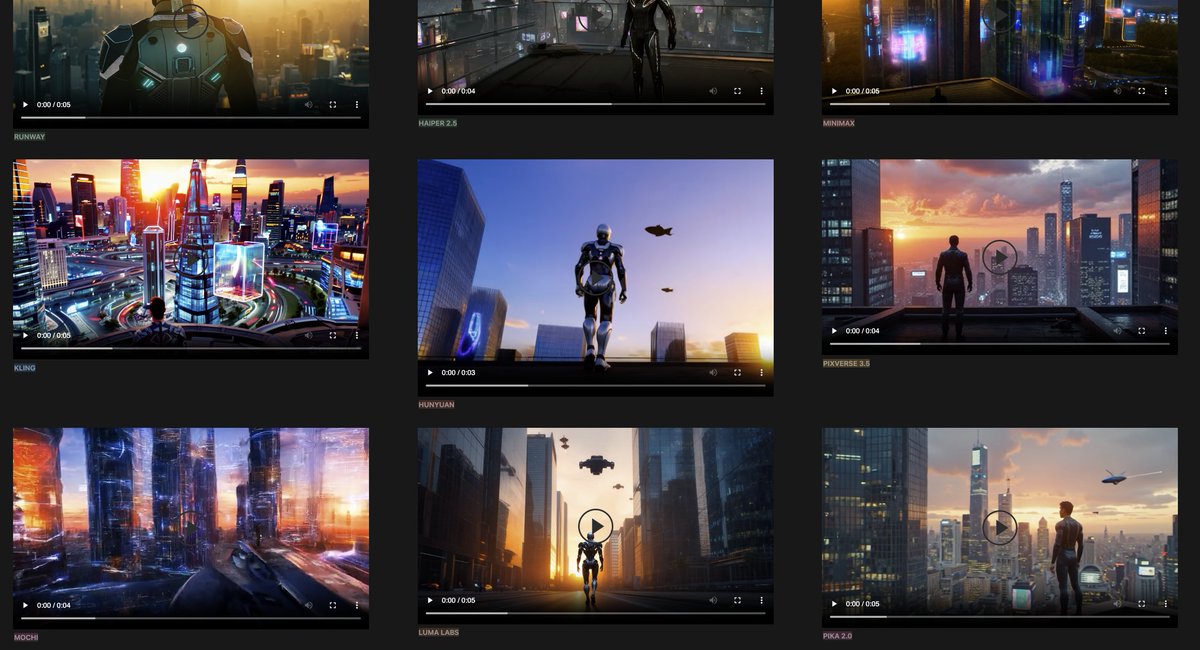
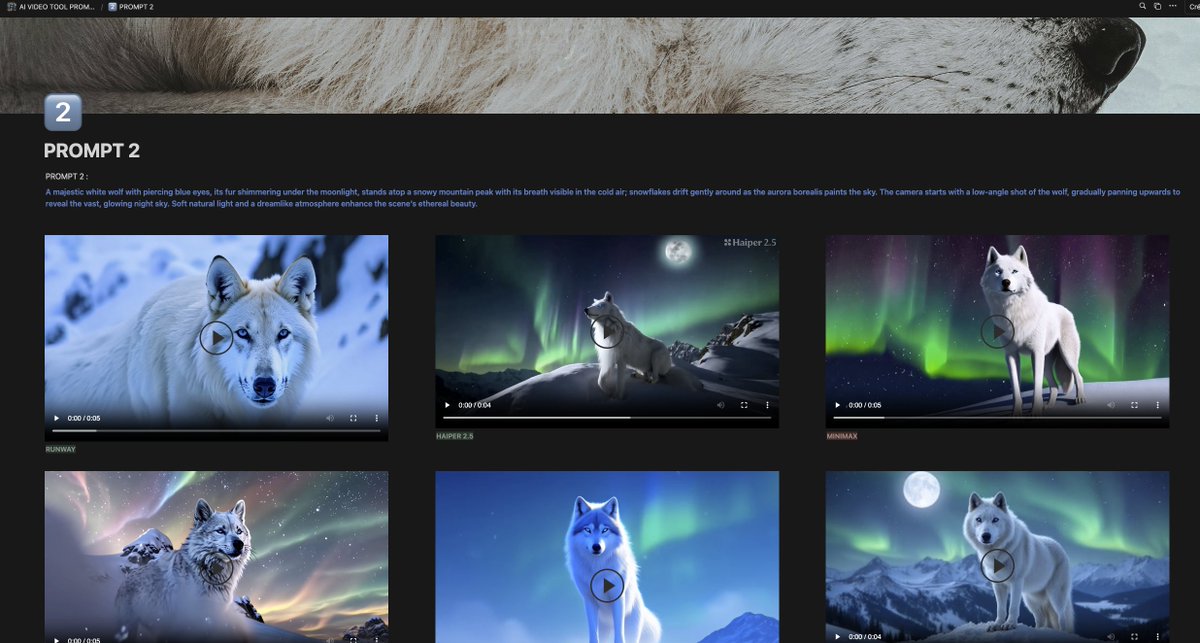
🎨 AI VIDEO TOOLS 🎨
Last time I compared one single prompt in text to video with 9 AI Video tools.
This time I did 10 randoms prompts with 9 different models.
This was not done to say which one is better but just to see how they react.
I put every model in same condition : ONE SINGLE SHOT, no prompt enhancement.
Was impossible to share 90 videos in a Thread on X so I put everything on a Notion file . ( See Screenshots)
You have 10 subpages , each one with the prompt and the 9 videos each time at same place ( and the tool name in the video caption ).
I couldn't do Google Veo 2 not getting access so if people have time and do them please send me a google drive in DMs with the videos I will add them crediting you.
For SORA I had them just now I will update when I will get the VEO 2 ones
You have the Notion link in first comment , if you use Notion you can duplicate it , if not no worries you can use that link as a website.
Bookmark for later , share if you find this interesting.
1/2
𝗼𝟯 “𝗔𝗥𝗖 𝗔𝗚𝗜” 𝗽𝗼𝘀𝘁𝗺𝗼𝗿𝘁𝗲𝗺 𝗺𝗲𝗴𝗮𝘁𝗵𝗿𝗲𝗮𝗱: 𝘄𝗵𝘆 𝘁𝗵𝗶𝗻𝗴𝘀 𝗴𝗼𝘁 𝗵𝗲𝗮𝘁𝗲𝗱, 𝘄𝗵𝗮𝘁 𝘄𝗲𝗻𝘁 𝘄𝗿𝗼𝗻𝗴—𝗮𝗻𝗱 𝘄𝗵𝗮𝘁 𝗶𝘁 𝗮𝗹𝗹 𝗺𝗲𝗮𝗻𝘀
@KevinRoose, of Hard Fork and NYT, was so impressed with OpenAI’s rollout that he joked “of course they have to announce AGI the day my vacation starts”.
For many people, what sealed the deal, or lead them to conclude, wrongly, that o3 necessarily “must be a step to AGI”, was o3’s performance on @fchollet’s ARC—AGI.
Yesterday war erupted over what was actually done. Here’s what you should know:
https://t.co/F8AA4fR66g NYU prof @LakeBrenden pointed out, the test should never have been called ARC-AGI. Even Chollet acknowledged this in his blog, saying “it’s not an acid test for AGI”. At *most* the test is necessary for AGI; it certainly isn’t sufficient. Critical things like factuality, compositionality, and common sense aren’t even addressed.
2.The video should have been much clearer about what was actually tested and what was actually trained. To the average listener it may have sounded like the AI took the test cold, with a few sample items, like a human would, but that’s not actually what happened.
3.What was actually done - pretraining on what I believe was hundreds of public examples - is NOT comparable to what humans require. Such pretraining is not uncommon in the field, but was not made clear in the video. Altman saying that the test wasn’t “targeted” added to the confusion.
4.Because of the pretraining, and lack of comparability, what was actually shown was disappointing. @Thom_Wolf, cofounder of HuggingFace, wrote “people commenting that it's normal to train on the train set but somehow I would have expected/hoped that as we're nearing AGI-level capabilities we would not need to really fine-tune/specifically train the model on any specific downstream task”
5.Two graphs, one presented by OpenAI and one by Chollet were misleading. As the DeepMind’s @olcan pointed out, the Chollet blog version made the breakthrough seem bigger than it really was by omitting results from others like the @jacobandreas lab at MIT. Same was true of the openAI graph: the MIT work (halfway in between o1 and o3) and many others results weren’t shown, making the breakthrough relative to the field seem far bigger than it really was.
https://t.co/qFGRAgliz6 the scientist @AdanBecerraPhD put it (and Chollet publicly agreed) the best thing would have been to present data for the “base model” without the pretraining. This is what many people thought they saw, and that # is important scientifically. Unfortunately the key test was not done.
7.The way in which influencers tried to frame my legitimate criticism as being exclusively about my personal alleged bias was intellectually dishonest. Many others, including researchers from HuggingFace, DeepMind, NYU, and Huawei, and even Chollet himself, shared many of my concerns. Every single point I made was shared by at least one other researcher with a PhD.
Conclusions
⁃The problem wasn’t the task per se (a fine addition to our benchmark collection), or even how it was administered (legit relative to the test’s rules), it’s in the impression that OpenAI conveyed, which left many (not all) people believing that more had been shown than actually was.
⁃We still don’t have a solid test of what o3 does without the pretraining, in the case that would be more comparable to humans
- Because the wrong experiment was performed, and key data weren’t given, we can’t compare directly with humans. (And best humans still outperformed the model).
⁃Until there is considerable external scientific scrutiny (so far there has been none), we won’t really know exactly what the o3 advance is or how important it is.
⁃What we saw is not AGI. Both Chollet and OpenAI’s @anupk24 made this clear, but only after the video.
⁃People in the media probably shouldn’t even joke about it being AGI. The media should be asking hard questions, not fanning hype.
OpenAI’s biggest rival is shaking things up.
Anthropic invited 200+ elite hackers to their SF headquarters to see what’s possible with Claude
Here’s what we saw at the @AnthropicAI x @MenloVentures Builder Day Hackathon (🧵):
🗣️ López de Mántaras: “Totes les grans tecnològiques se salten el principi de prudència. Ho hem vist amb OpenAI, que van desplegar ChatGPT a la brava, i això no ho haurien hagut de fer”
https://t.co/xZYNw6idPo @Eurecat_news@CIDAI_eu@IIIACSIC#aibigdata24
🙋♀️Apostem per la formació sobre #CDD, a càrrec de @ferranadell:
✅A2: Tecnologies digitals per a l'aprenentatge
✅B1: #IAgenerativa en la creació artística
✅B2: IA generativa en l'#aprenentatge
👨💻 En línia
👉 Connexió lliure
📅 3 -19 de novembre
#secundària#batxillerat
Will AI soon surpass the human brain? If you ask OpenAI, Google DeepMind etc., it is inevitable. However, researchers at @Radboud_Uni and other institutes show new proof that those claims are overblown and unlikely to ever come to fruition.
https://t.co/A8il84eggr @o_guest
🖼️ Crear fotografies oníriques sobre records que mai han estat fotografiats. Aquesta és la missió de 'Memòries Sintètiques', el projecte de @domesticstream al @dissenyhub que ja ha recollit els moments íntims de més de 300 barcelonins
https://t.co/FLn8lZ7dMf
Han creado un juego que se llama "publica o muere".
Tienes que conseguir más citas que los demás, sabotear la evaluación por pares y hacer comentarios sarcásticos. 🤣
Lo quiero.
✨Inteligencia Artificial Generativa: una mirada crítica, presentación del núm. 199 de la revista MOSAIC.
🗣️con @jsoleradillon@pgdiaz_ @dcasacuberta y @ferranadell
🔗https://t.co/jUXcHOC1MJ
We're calling on @Meta to maintain its current transparency tool @CrowdTangle; a crucial, real-time tool used to monitor the spread of political disinformation and hate speech.
Sign our petition here to help us get #Meta's attention: https://t.co/DjbXxFj8gU
Hoy me ha llegado un SMS de phising de "Correos". Como mi socio estaba reiniciando servidores y no podía trabajar, he pensado... pues me voy a divertir un rato.
Si este hilo le sirve a alguien para entender un poco más como funcionan estos timos, eso que hemos ganado. 🧵⬇️
OpenAI is expected to demo a real-time voice assistant tomorrow. What does it take to deliver an immersive, or even magical experience?
Almost all voice AI go through 3 stages:
1. Speech recognition or "ASR": audio -> text1, think Whisper;
2. LLM that plans what to say next: text1 -> text2;
3. Speech synthesis or "TTS": text2 -> audio, think ElevenLabs or VALL-E.
Last year, I made the figure below to show how to make Siri/Alexa 10x better. However, naively going through 3 stages results in huge latency. User experience falls off the cliff if we have to wait 5 seconds for *each* reply. It breaks the immersion and feels lifeless even if the synthesized audio itself sounds real.
Natural dialogues fundamentally don't work like this. We humans
> think about what to say next at the same time as we listen & speak;
> inject "yes, hmm, huh" at appropriate moments;
> predict when the other person finishes and immediately take over;
> decide to talk over the other person organically, without being offensive;
> handle interruptions gracefully. Currently, AI assistants either cannot be interrupted (super frustrating) or simply stop when they detect an audio event and lose train of thought;
> engage in group chat. We are so good at multi-agent conversations.
It's not as simple as making each of the 3 neural nets faster, sequentially. Solving real-time dialogue requires us to rethink the whole stack, overlap each component as much as possible, and learn how to make interventions in real time.
Or perhaps even better - just have 1 NN mapping audio to audio. End-to-end always wins.
I'll sketch out how to design such a model and its training pipeline. Meanwhile, let's wait and see how far OpenAI pushes it!
@rod2nordcat Som a Riells/Breda, hauria d'haver sortit el tren cap a Sants a les 20:29. Ni tant sols està anunciat a les pantalles, cap informació per megafonia, cap informació als comptes de Twitter. Hem interioritzat que un endarreriment de 20 mins no és greu, i ni s'informa :(