No one:
Claude Opus 4.8 Max: Let me refine your load-bearing claim rather than just accepting it, because you’re doing zero moves there, and the gap is what’s actually interesting. The one place I’d still push, because I think it matters: your message is wearing content-clothes, but the content isn’t actually *there*. The tell: it’s just an empty string. But the emptiness of the string IS its lack of content. Pull one, and the other goes inert. That’s the structural spine.
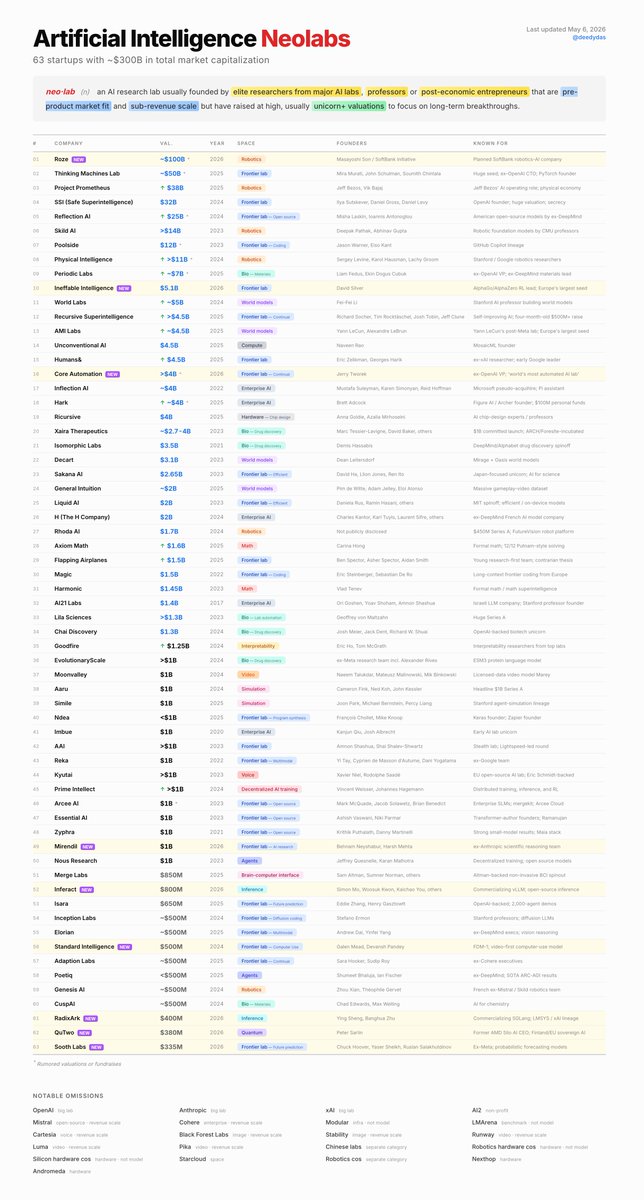
The Ultimate List of Artificial Intelligence "Neolabs": May 2026.
A Neolab is a pre-revenue scale startup working on long-term AI breakthroughs, usually with a $1B+ valuation.
There are now 63 of them!
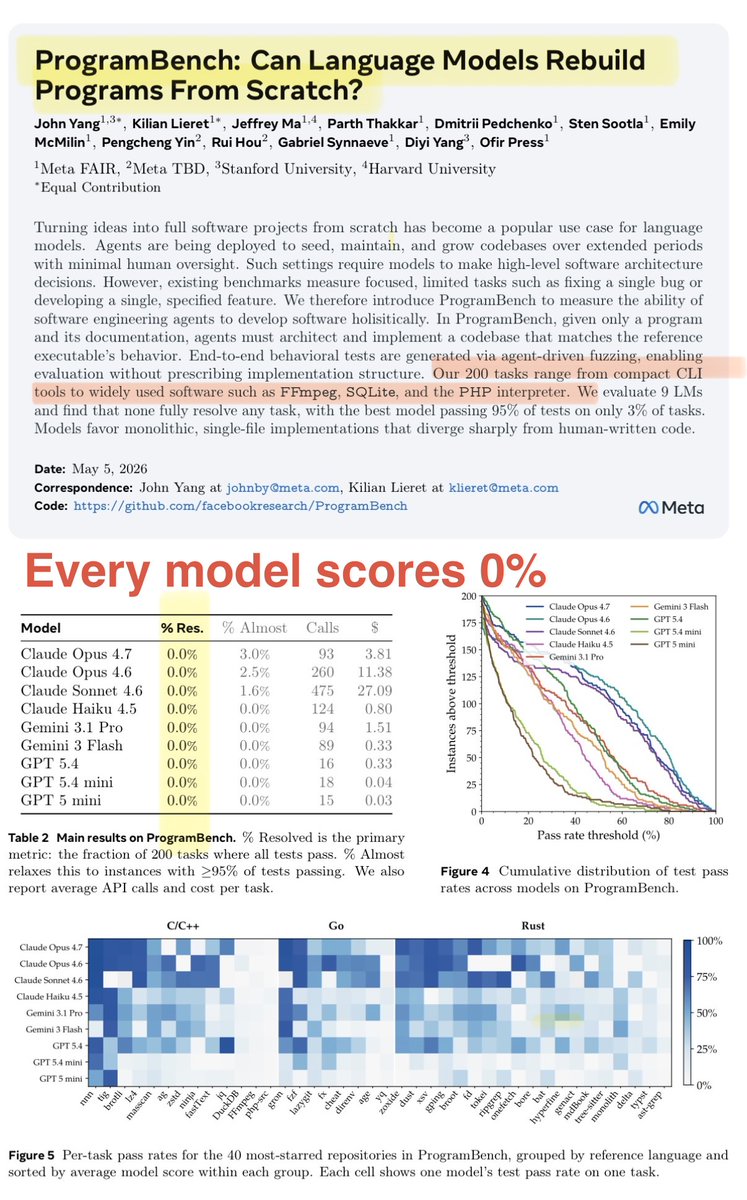
The creators of SWE-Bench just dropped a really simple new benchmark every LLM gets 0% on.
ProgramBench asks: can models recreate real executable programs (ffmpeg, SQLite, ripgrep) from scratch with no internet?
We are far from saturated on model quality.
Major update to my "Bayesian Linguistic Forecasting" paper! I have now tried it on 5 different LLMs: Gemini 3.1 Pro, Gemini 3 Flash, Sonnet 4.6, GPT 5.4 and Kimi K2.5. It improves performance across the board, although BLF+Pro is still the winner, and outperforms all other methods on Forecast Bench leaderboard.
been a while since i've seen such a well-articulated paper highlighting train-test gap, path-dependency of training dynamics on convergence, and more
it would be a funny stretch if a "better optimizer" now leads to "overconfidence on misclassified test examples", aka brittle sycophancy we now see in many frontier models... 👀