OpenClaw is the fastest-growing open source project, but there are no stories of running it safely in production at scale. As we started deploying agents internally at @brexHQ, we couldn’t stop thinking about this question.
Agents work, but nobody wants to give them real credentials. Instead of waiting for a solution to emerge, we decided to try a novel approach: using LLMs to judge the network traffic of an AI agent.
Today we’re announcing CrabTrap, an open-source proxy that intercepts every outbound request and blocks risky activity using LLMs, before it ever hits an external API. The results are promising; we believe it’s a meaningful step forward in the security of agent harnesses in production environments.
Try it out today.
(As a side note, it was really fun to work personally on a real systems problem again. And btw, if you want to work at a place where the CEO is building proxies at night, we’re hiring!)
GBrain v0.10.0 is a big one
My personal OpenClaw setup and brain can now be yours. I've perfected my RESOLVER.md, my SOUL.md and ACLs for multi-user brain access.
Now there are 24 distinct fat skills with fat code, fully tested with e2e tests, evals and unit tests.
6. The Influence of Kaiming He
Xie deeply admires Kaiming He, with whom he worked closely at FAIR. He learned that Kaiming's superpower is his extreme focus and ability to build an impenetrable baseline ("scaffold") before aiming for breakthroughs [02:34:30]. Kaiming taught him that the real research "signals" come from the failures and surprises during the experimental process, not from armchair theorizing [02:08:12].
7. "Impact" vs. "Understanding"
Xie dislikes the word "impact," finding it too ego-driven and aggressive. Instead, he views research through the lens of philosopher Hannah Arendt: the goal of research is "understanding." Publishing a paper is about sharing a profound realization with the world to find resonance and intellectual kinship, rather than just changing the world by force [01:31:27].
8. Intelligence is More Than Human Language
Xie cautions against human arrogance in defining intelligence solely through language. Drawing on evolutionary biology, he argues that building an AI with the survival and physical reasoning skills of a squirrel is actually a much harder problem than building an AI that can write code or pass exams [06:13:05].
9. The Power of "Research Taste"
Xie equates research to filmmaking, where "taste" dictates everything from the problem you choose to solve down to the formatting of the paper. Influenced by Kaiming He (who even gifted him the Buddhist Diamond Sutra to teach him to look past superficial "forms" to find true substance), Xie believes good taste means avoiding crowded, hyped areas in favor of fundamental, eternal problems like representation learning [02:45:03].
10. The Degradation of Open Academic AI Research
Xie expresses concern over how major industrial AI labs have become increasingly closed off, shifting from open academic exploration to secretive commercial competition. This shift strips researchers of their autonomy and turns them into easily replaceable cogs in a massive engineering machine, heavily motivating his decision to start a new, more open research-driven company [05:21:26].
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)
Very interested in what the coming era of highly bespoke software might look like.
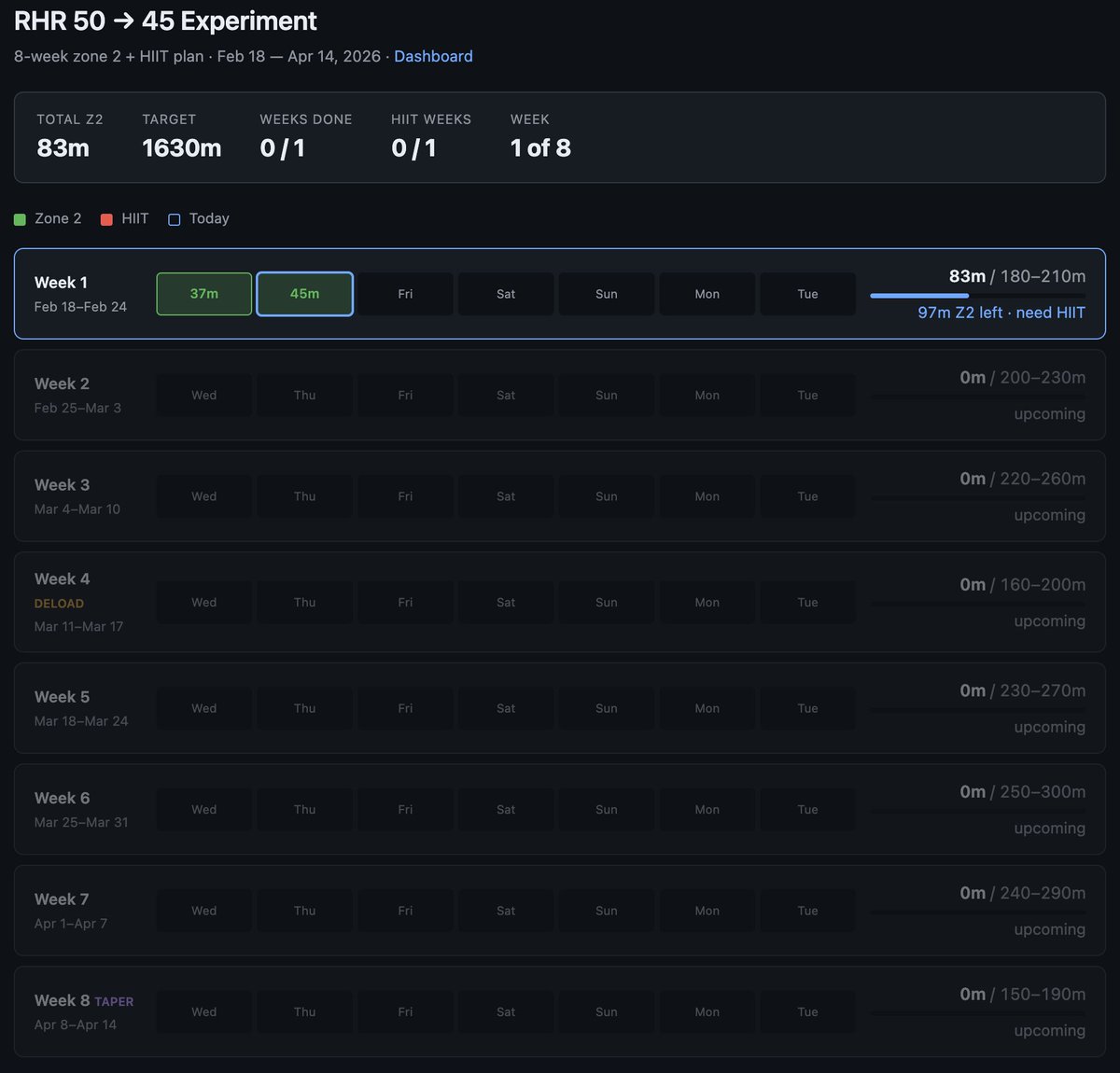
Example from this morning - I've become a bit loosy goosy with my cardio recently so I decided to do a more srs, regimented experiment to try to lower my Resting Heart Rate from 50 -> 45, over experiment duration of 8 weeks. The primary way to do this is to aspire to a certain sum total minute goals in Zone 2 cardio and 1 HIIT/week.
1 hour later I vibe coded this super custom dashboard for this very specific experiment that shows me how I'm tracking. Claude had to reverse engineer the Woodway treadmill cloud API to pull raw data, process, filter, debug it and create a web UI frontend to track the experiment. It wasn't a fully smooth experience and I had to notice and ask to fix bugs e.g. it screwed up metric vs. imperial system units and it screwed up on the calendar matching up days to dates etc.
But I still feel like the overall direction is clear:
1) There will never be (and shouldn't be) a specific app on the app store for this kind of thing. I shouldn't have to look for, download and use some kind of a "Cardio experiment tracker", when this thing is ~300 lines of code that an LLM agent will give you in seconds. The idea of an "app store" of a long tail of discrete set of apps you choose from feels somehow wrong and outdated when LLM agents can improvise the app on the spot and just for you.
2) Second, the industry has to reconfigure into a set of services of sensors and actuators with agent native ergonomics. My Woodway treadmill is a sensor - it turns physical state into digital knowledge. It shouldn't maintain some human-readable frontend and my LLM agent shouldn't have to reverse engineer it, it should be an API/CLI easily usable by my agent. I'm a little bit disappointed (and my timelines are correspondingly slower) with how slowly this progression is happening in the industry overall. 99% of products/services still don't have an AI-native CLI yet. 99% of products/services maintain .html/.css docs like I won't immediately look for how to copy paste the whole thing to my agent to get something done. They give you a list of instructions on a webpage to open this or that url and click here or there to do a thing. In 2026. What am I a computer? You do it. Or have my agent do it.
So anyway today I am impressed that this random thing took 1 hour (it would have been ~10 hours 2 years ago). But what excites me more is thinking through how this really should have been 1 minute tops. What has to be in place so that it would be 1 minute? So that I could simply say "Hi can you help me track my cardio over the next 8 weeks", and after a very brief Q&A the app would be up. The AI would already have a lot personal context, it would gather the extra needed data, it would reference and search related skill libraries, and maintain all my little apps/automations.
TLDR the "app store" of a set of discrete apps that you choose from is an increasingly outdated concept all by itself. The future are services of AI-native sensors & actuators orchestrated via LLM glue into highly custom, ephemeral apps. It's just not here yet.
When I first heard Shinzen and other teachers talk about recognizing depth of practice from the way someone stands, walks, and talks, I didn't know quite what to make of it.
Over time, more clearly seeing how this mind is more an extension of these bodily senses than anything apart, noticing ever subtler causal connection between breath, body, and every mind-movement, all these expansions and contractions in awareness, and beginning to recognize the same in others, it made more sense.
Then, having countless experiences in-person of my own teachers clearly seeing my own obstructions better than I could, empty mirrors reflecting my own grasping back at me, I had no doubt.
Much of what I naively interpreted as metaphor is quite literal.
I saw the greatest minds of my generation waste 1000 hours fixating on their breath with no insights or lasting effects bc they read the mind illuminated
Women founders have been reaching out to me over the past 24 hours about how they don’t have permission to run their companies in Founder Mode the same way men can. This needs to change
this morning i heard @OortCloudAtlas reframe sadness in a way that loosened a knot i didn't know i had in my chest. he said,
"usually we're sad about something difficult that happened but if we look behind that, it's because we wish something good had happened
it's rly a wish that good things happen; that people and animals feel good
it's rly simple
in a way, sadness is one of our most beautiful treasures because it's our compassionate heart expressing itself
the energy of kindness, caring and love [has] a certain close tie with sorrow"
It's not always possible to say, at the time, what was the most important thing that happened on any particular day. But this was very likely the most important thing that happened on March 22, 2024.
https://t.co/kIUxOCgHUW
























![heynibras's tweet photo. this morning i heard @OortCloudAtlas reframe sadness in a way that loosened a knot i didn't know i had in my chest. he said,
"usually we're sad about something difficult that happened but if we look behind that, it's because we wish something good had happened
it's rly a wish that good things happen; that people and animals feel good
it's rly simple
in a way, sadness is one of our most beautiful treasures because it's our compassionate heart expressing itself
the energy of kindness, caring and love [has] a certain close tie with sorrow"](https://pbs.twimg.com/media/GJfaPEhaoAAnNdU.jpg)





























