Unless you’ve lived in that world, it’s difficult to understand it. Same way the current narrative around Fable and export controls is going over most people’s heads. Dario’s naivety will continue to hurt Anthropic unless they wisen up and get a few battle-scarred Defence type people on board.
🚨 @Karpathy predicted the power of the "LLM Wiki." Google just formalized it.
Meet Open Knowledge Format (OKF): a vendor-neutral standard for giving foundation models the curated context they need.
I can genuinely see this replacing Notion, Obsidian, or traditional wikis for developer teams, and the reason comes down to bookkeeping.
Traditional wikis fail because humans inevitably abandon the tedious work of updating them.
As Andrej Karpathy pointed out recently, LLMs don't get bored.
They don't forget to update a cross-reference, and they can touch 15 files in a single pass.
OKF standardizes the interoperability layer so agents can actually do that heavy lifting autonomously.
Because the format is minimally opinionated, it doesn't dictate what you write, it just dictates how it's structured. You get:
→ Human-readable documents that live right alongside your code in version control
→ Cross-links that map out complex entity relationships without needing a graph database
→ A system that survives moving between different tools and organizations
There is no complex compression scheme.
No central registry.
If you can cat a file, you can read it.
If you can git clone a repo, you can deploy it.
This is how we stop rebuilding context pipelines from scratch every time a new model drops.
Announcement + spec file in 🧵↓
I’ve had a number of conversations with folks inside and outside government about the current situation with Anthropic, and here is what I believe to be true:
— As we know, Anthropic publicly released its Mythos class models earlier this week under the commercial name Fable.
— Fable is Mythos with guardrails. But if those guardrails fail, then you’ve exposed Mythos and its advanced cyber capabilities to people who shouldn’t have them. (Keep in mind that Anthropic itself widely promoted the idea that Mythos was a cyberweapon and needed to be regulated as such. They asked for government regulation of Mythos and championed the guardrails on Fable. If there is a vulnerability — big or small — it is Anthropic’s responsibility to patch.)
— A highly credible trusted partner of both Anthropic and the USG who was testing Fable came forward with a jailbreak of those guardrails. The Admin asked Dario to fix the jailbreak or de-deploy the model. Dario refused.
— In their blog post, Anthropic defended its decision by saying the jailbreak isn’t serious. That is not what the trusted partner and the USG believe; nor is that kind of minimizing language consistent with Anthropic’s brand as the AI safety company. It’s difficult to fathom how they could claim a jailbreak allowing operability of a cyber weapon could be defined as not “serious.”
— In the past, Anthropic has always said that safety must be top priority and taken super seriously. In this case, Anthropic prioritized the continued offering of the consumer model over safety.
— In reaction, the Admin issued the export control. The Admin did this reluctantly. It’s been very surprised that Anthropic hasn’t wanted to cooperate with a reasonable safety request (ie fixing the jailbreak issue). Anthropic’s reaction is very much at odds with their branding and ethos as a safe AI research community.
— The Admin’s hope now is that Anthropic remediates the safety issue, the export control is lifted, and Fable goes back into general release. The Admin wants all of this to happen as soon as possible. It is frankly bewildered that Anthropic hasn’t wanted to comply with safety requests that it previously said were its highest priority.
— Those trying to misdirect and tie this action to the prior DoW/Anthropic issues are wrong. The Admin values Anthropic’s technical capabilities and feels that this issue, while serious, should be easily resolved. The ball is in Anthropic’s court.
Yann Lecun published the most heretical AI paper of the year.
He opens by arguing Magnus Carlsen isn't good at chess and only gets more unhinged from there.
The Turing Award winner and his co-authors dropped a paper demanding the AI industry abandon its biggest obsession, AGI.
Right now, everyone from Silicon Valley CEOs to politicians assumes AGI is the ultimate goal. A machine that can do everything a human can do.
LeCun argues that this entire concept is a biological illusion.
Humans do not possess "general" intelligence. We are highly specialized biological machines, tuned by evolution simply to survive in the physical world.
We only think our intelligence is "general" because we are completely blind to the millions of cognitive tasks we are incapable of comprehending.
Which brings us to the chess argument.
Magnus Carlsen is the greatest human chess player in history. But compared to a modern computer? He is fundamentally terrible.
Our belief that Carlsen is "good" at chess is pure human-centric bias. He isn't objectively good. He's just better than the rest of us, who are biologically awful at it.
LeCun says we need to stop building AI to mimic human generality.
Instead, he proposes a new North Star: SAI.
Superhuman Adaptable Intelligence.
Instead of trying to build a machine that mimics our flawed, biologically-limited brains, we need to embrace extreme specialization.
SAI is about the speed of adaptation.
It is an intelligence that can learn to exceed humans at any specific, economically important task.
More importantly, it is designed to fill the vast skill gaps where humans are fundamentally incapable.
Things like managing global energy grids in real-time. Or predicting complex molecular structures.
The entire AI industry is obsessed with building a digital reflection in our own image.
LeCun's paper is a brutal wake-up call.
Exactly, this is why I’ve done back to doing my own internet research, and handwriting journals. We are human, and part of being human is the journey. If it’s too easy, or too quick, our creativity withers and dies. Why I’ve turned down the intensity on the AI - my human brain needs a break.
The cheek of Trump, when America’s frontier AI companies are amongst the worst offenders wrt using slave - forced - labour to power their LLM’s. @AlboMP do your job please and call that out to the US administration. If you need the evidence happy to provide it, plenty out there #AI #auspol
This is exactly right. The tech bros lost their way with betting the house on LLM’s. Bad move, Yancun is right, world models are the next big innovation. Will leave LLM’s for dead if our brilliant AI scientists can get it right ❤️
World Labs CEO Dr. Fei-Fei Li: "The world is not made of words."
"Language models have given machines an extraordinary command of concepts, vocabulary, and reasoning, but the physical world, virtual or real, runs on a different substrate."
"Where language models learn the statistical structure of text, world models learn the statistical structure of space and time: how light falls on a surface, how a garden looks from an angle no camera has captured, how objects respond to force and follow the laws of physics."
"Language gave machines a way to talk about that world. World models are how machines will finally come to understand, imagine, reason and interact with it."
Full piece: https://t.co/C9qOJg5wuc
One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]
Three PhD students sat on a weathered pier overlooking a channel. In the distance, a bell buoy rocked with the tide, its hollow tone carrying across the water.
The first student listened to the bell and said, "I can imagine swimming out to that buoy and back. I can feel the cold water, the pull of the current, the burn in my shoulders, and the exhaustion of the return."
The second student smiled.
"I have already completed the swim in my mind. I can imagine touching the buoy, turning toward shore, and feeling the satisfaction of accomplishment. I can feel the weight in my arms and the pride that comes from finishing."
The third student stood without a word.
He removed his shoes, stepped from the pier, and began swimming toward the buoy.
The water was colder than he expected.
The current was stronger.
The distance was farther.
Before he reached the buoy, he disappeared beneath the surface.
The bell continued to ring.
The tide continued to move.
The channel remained exactly what it had always been.
The two students sat silently on the pier.
For the first time that afternoon, neither had anything to say.
At first glance, this is a joke about philosophers.
It is also a warning about reality.
The first student understood possibility. He used imagination to explore an experience without exposing himself to danger.
The second student imagined success. He enjoyed the reward before paying the price.
The third student acted.
Unfortunately, action alone is not wisdom.
The channel did not care about his intentions.
The water did not care about his confidence.
Reality rarely negotiates with belief.
Modern society often divides itself between those who only think and those who only act. One group mistakes analysis for achievement. The other mistakes movement for progress.
Both can fail.
The lesson is not that imagination is useless. Every great accomplishment begins as an idea. Nor is the lesson that action is dangerous. Nothing meaningful is ever accomplished without it.
The lesson is that reality remains the final examiner.
A business plan is not a business.
A strategy is not a victory.
A belief is not a fact.
A simulation is not an experience.
The map is useful. The journey is necessary. But neither changes the terrain.
The bell buoy continues to ring whether we understand it or not.
The channel remains what it is.
And sooner or later, every philosophy encounters the water.
Folks: when you write skills, ask your agent to be token efficient, relax grammer. I see too many skills that write books in the skill description, and all that crap is loaded into every context.
I wrote a skill that finds the worst offenders. https://t.co/kfaaJpxMXE
Perplexity just open-sourced the tool they use internally to keep their own developers safe. 😨
It's called Bumblebee. It runs quietly on a developer's laptop and checks for any sneaky code, suspicious browser plugins, or AI tools that might be silently leaking access to your data.
It covers Claude Code, Codex, Cursor, all of it.
Here is why this matters now.
For the last six months, hackers have been quietly slipping malicious code into the free building blocks that almost every app in the world is built on.
When a developer installs one of these poisoned pieces, the attacker gets a backdoor into everything that developer touches.
Including their AI tools and the keys that unlock them.
Most security tools defend the finished product. Bumblebee defends the person building it.
An independent security researcher read through the entire code and confirmed it is clean.
No hidden tracking. No data collection. No backdoors.
For two years, AI coding tools shipped with zero security defenses around them. Perplexity just shipped one. Free.
Worth installing if you build anything with AI.
A 22-year-old graduate student in Kazakhstan got so angry at journal paywalls in 2011 that she built a pirate website holding 88 million scientific papers, and last month she turned the whole thing into an AI that lets you ask one question and get the actual research as the answer.
Her name is Alexandra Elbakyan, and the website is called Sci-Hub.
The AI she just launched is called Sci-Bot. It lives at https://t.co/6w0IBtOEYB and almost nobody outside academia knows it exists yet.
Here is the story, because it is one of the strangest things to happen in science publishing in the last 50 years.
Elbakyan was born in Almaty in 1988, the year the Soviet Union started to collapse. She taught herself programming at 12. She read Soviet science books that explained things her family used to call miracles. She got into computer security at university and graduated in 2009 with a degree she barely needed because by then she was already a serious hacker.
Alexandra moved to Moscow that fall. Then Germany. Then a research internship in the United States. She was working on brain-computer interfaces, the kind of research that requires you to read hundreds of papers a year just to keep up with the field.
And every single one of those papers was locked behind a journal paywall that cost between 30 and 50 dollars to read once.
She did the math. A graduate student in Kazakhstan could not afford to read science.
The first thing she did was learn how to get around the paywalls one paper at a time. She passed the trick around to other students. They asked her for papers constantly. She got tired of doing it manually.
So in September 2011, in three days, she wrote a script that automated the whole thing. A user pastes a DOI. The script logs in through a donated institutional credential. The paper comes back free. The website caches it.
The next person who asks for that paper gets it instantly because the previous request already saved a copy.
That was Sci-Hub. Three days of code. One graduate student. Done.
15 years later, the cache holds 88 million scientific papers. Almost every piece of scholarly literature published before 2020 is sitting on her servers. Researchers in 190 countries use it. Studies in Nature have shown that roughly half of all academic paper downloads worldwide now go through Sci-Hub, not the publishers who actually own the copyrights.
Elsevier sued her in 2015 and won a 15 million dollar judgment. She did not pay. The American Chemical Society sued her and won an injunction. She did not comply. Courts in India, France, Russia, and the UK have tried to block the domain. She just moves it. https://t.co/3sAWJzNe8I. https://t.co/tGIETesZ8i. https://t.co/H5WQ1f9lqR. The site has had over 20 domains and is still up.
Nature put her on its list of the 10 people who mattered most to science in 2016. The New York Times compared her to Edward Snowden. The Verge called her the pirate queen of science.
She has not been to the United States in over a decade because she would be arrested at the airport.
The Sci-Bot launch in April 2026 is the part that nobody is talking about.
She took the 88 million paper database and put a small language model on top of it. You ask a question in plain English. The model searches the entire shadow library, pulls the relevant papers, synthesizes an answer grounded in real citations, and links you to the full text of every source. Free. No login. No institutional credential. No paywall.
Three real scientists tested it for a Chemical and Engineering News article last month. They asked it medical and chemistry questions. The radiologist said the answer he got was usable. The chemist said the gaps in recent literature were obvious but the older science was solid. The publisher community is furious.
What she built is what the paid academic AI tools are trying to build. Except the paid ones are limited to what their parent publisher legally owns. Hers is limited to almost nothing.
Alexandra still lives somewhere in Russia. She does not give her address. She does not do video interviews. She gives talks over Skype with the camera off. She runs the largest illegal library in human history from a laptop and a donation page.
A graduate student who could not afford to read science built the system the entire scientific community now quietly depends on.
The publishers have spent a decade trying to shut her down.
She just shipped an AI that makes their entire business model outdated.
@MatthewBerman@sama Agreed, this is top of my list too. Although, there are a few more. It would be nice if AI could somehow solve the problem of cybercrime rather than contributing to it, but I know that’s not really possible - dual use and all that.
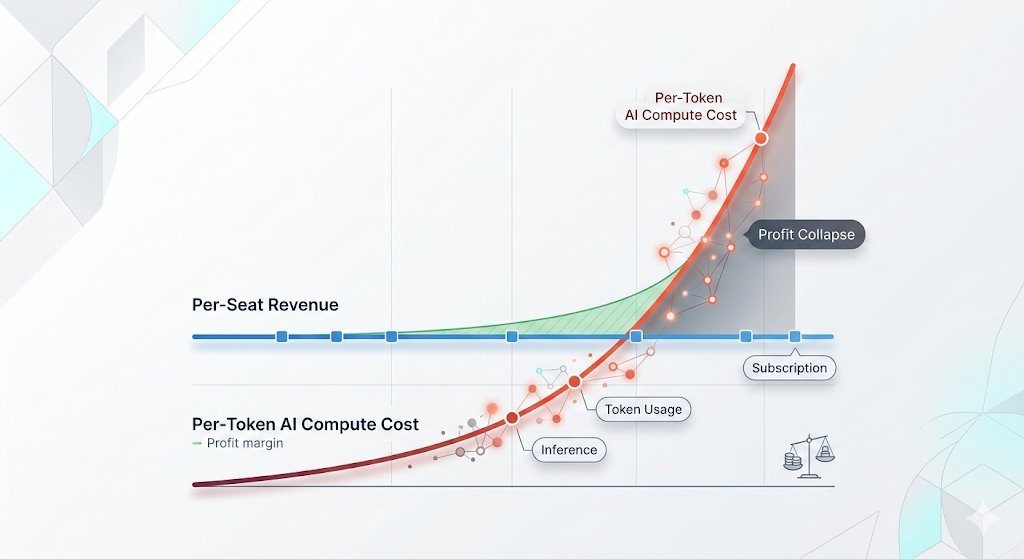
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
























![AndrewYNg's tweet photo. One of the new, buzzy jobs in Silicon Valley is the AI Forward Deployed Engineer (FDE), an engineer who is embedded within a client organization to help customize solutions, such as building and tuning agentic workflows that suit the client’s particular needs. I’ve heard from people who are wondering anew about the FDE career path since OpenAI and Anthropic started building new teams to place FDEs within client organizations.
The rise of FDEs for AI workloads is one way AI is creating new jobs (and why the jobpolcalypse narrative of upcoming job market collapse is false -- there will be many AI and non-AI jobs). However, I believe there will be far more AI Engineer jobs than FDEs, as I explain below.
The FDE role was pioneered about two decades ago by Palantir, which sent engineers to government locations to work on secure, air-gapped networks. In addition to having good technical skills, FDEs need communication skills and sometimes business skills. For example, they may need to speak with clients to understand their needs, formulate a strategy to prioritize projects, explain complex technology, and respectfully push back if a client asks for something unrealistic. They’re enjoying a resurgence because of the amount of work involved in taking an off-the-shelf LLM and building it into a custom agentic workflow that fits particular business needs.
However, I believe the number of AI Engineer jobs will be far larger. A company might accept a few FDEs to be embedded within its organization. But most companies will want far more of their own employees working on their projects. While my organizations do hire FDEs, we hire far more AI Engineers! Also, a common client concern is that it is hard to find vendor-neutral FDEs — they are, after all, there to deeply integrate a particular vendor’s product into a company. In this moment when it’s hard to predict which AI service will be the best one in a year’s time, optionality (the ability to pick whatever vendor turns out to fit best in the future) is very valuable. In contrast, letting FDEs tightly bind a company’s processes significantly reduces optionality.
Right now, I see surging demand for AI Engineers who can build software applications using AI software components (like LLM prompting, agentic frameworks, evals, etc.) and effectively use AI coding agents (like Claude Code, Codex, Antigravity CLI, and OpenCode). As the AI Engineer role matures, I expect it to fragment into more specialized roles, like the generic Software Engineer role from decades ago fragmented into frontend, backend, mobile, data engineering, devops, and so on.
What will be the future, specialized AI engineering roles? I don’t know. Perhaps there will be AI FDEs, LLMOps Engineers, Evals Engineers, AI Data Engineers, Harness Engineers, and other roles we don’t have names for yet. But for now, I see a lot of AI engineers who are generalists create a lot of value. Skilled AI Engineers are in very high demand! As our field continues to mature over the coming decade, I look forward to new specializations within AI Engineering that create even more job opportunities.
[Original text: The Batch newsletter]](https://pbs.twimg.com/media/HJvWmCHagAAnTxQ.jpg)