As a JNV alumnus, I believe it’s a huge missed opportunity for Tamil Nadu students not to have access to Jawahar Navodaya Vidyalayas. For countless children from rural and economically modest backgrounds, JNVs provide high-quality education, excellent infrastructure, exposure, and lifelong friendships that would otherwise be out of reach. They were established under Rajiv Gandhi’s vision to promote educational equity and talent development across India. This is about opportunity and social mobility, not ideology or politics.
@joshwoodward@GeminiApp Update or import memory, I have been causing ChatGPT everyday for last 2+ years, it knows a lot about me, how can I seed Gemini with this info for more context to avoid being too verbose for each query.
We should consider replacing Turing test with concur expense test. Like ability to submit concur expense reports under 30 mins without cursing 10 times..! That’s true AGI..!
@i_pranavmehta Congrats and a great product! How are you guys thinking of GTM? Are you guys building Field engineering/SE/partnership teams? Would love to chat!
What I’d pay to watch:
A daily HBO-style, Vice-inspired newscast curated from first-party sources (primarily twitter) and modern media (podcasts & other sources). We’re at the dawn of a new era with an incredible opportunity to build the modern media outlet—tech breakthroughs, longevity, AI arms race, manufacturing, space, crypto, and world events all in 30-60 mins of high-quality content.
Because endlessly scrolling Twitter isn’t helping anyone! Also, let’s be real—livestream of DOGE findings would be premium PPV content. 😀📺✨
💯 to everything said here! It’s worth diving deeper into the role of policymakers, nation builders, market makers and industrialists to execute with unified view to reinvent the future !
2. These cycles initially favor CAPEX-heavy models. Consider the infrastructure required for oil and gas in the 1920s, railroads in the 1800s, or semiconductors and space exploration in the late 20th century.
The Jiofication of India over the last decade exemplifies this. As the underlying resource / innovation (oil, cpu, gpu, network, AI-token) becomes commodity, price becomes the primary differentiator. Those with the endurance to withstand aggressive price competition win, attracting more capital and scaling further.
Countries with robust capital markets, policies, supply chains, and talent pipelines hold the advantage and often end up “owning” the bottom layer of innovation which they can seek rent on as the cycle plays out often for 30-50 years.
https://t.co/UmOPNA9mCI
2. These cycles initially favor CAPEX-heavy models. Consider the infrastructure required for oil and gas in the 1920s, railroads in the 1800s, or semiconductors and space exploration in the late 20th century.
The Jiofication of India over the last decade exemplifies this. As the underlying resource / innovation (oil, cpu, gpu, network, AI-token) becomes commodity, price becomes the primary differentiator. Those with the endurance to withstand aggressive price competition win, attracting more capital and scaling further.
Countries with robust capital markets, policies, supply chains, and talent pipelines hold the advantage and often end up “owning” the bottom layer of innovation which they can seek rent on as the cycle plays out often for 30-50 years.
https://t.co/UmOPNA9mCI
We have to take the LLMs to school.
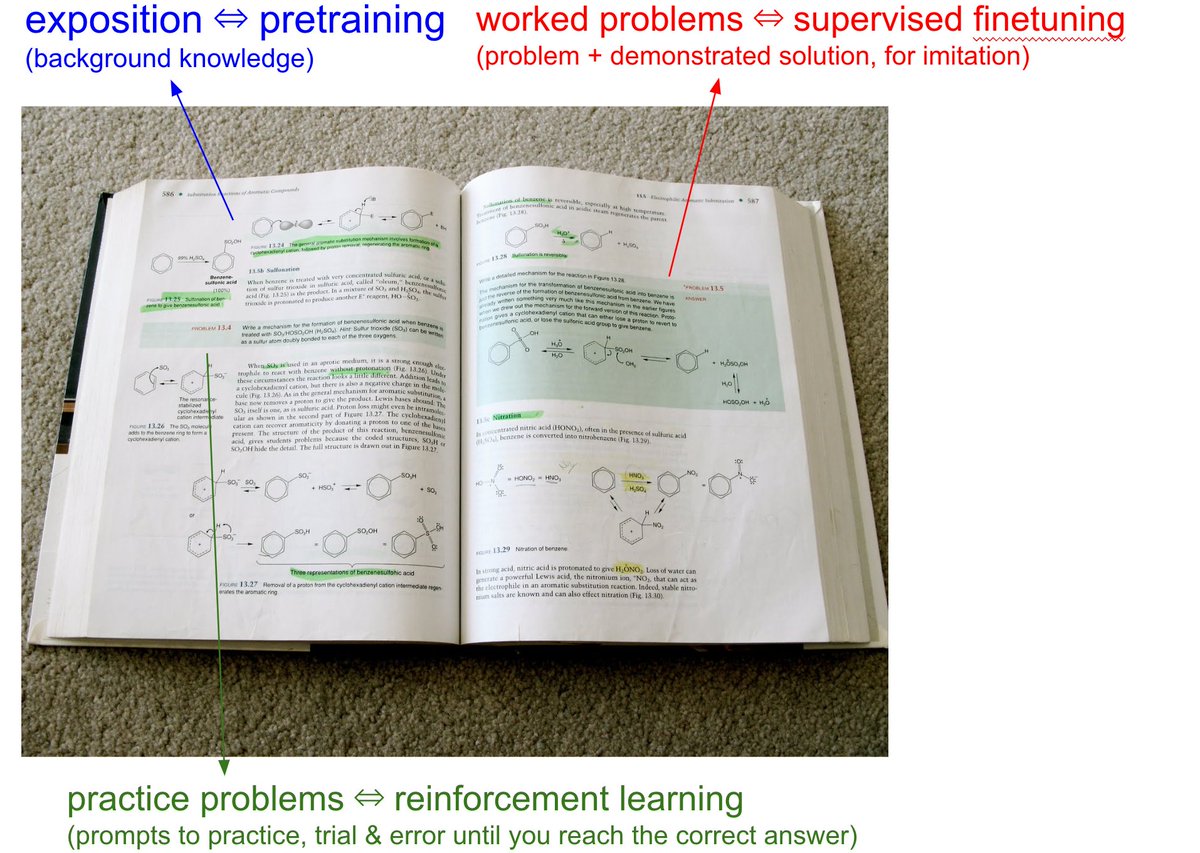
When you open any textbook, you'll see three major types of information:
1. Background information / exposition. The meat of the textbook that explains concepts. As you attend over it, your brain is training on that data. This is equivalent to pretraining, where the model is reading the internet and accumulating background knowledge.
2. Worked problems with solutions. These are concrete examples of how an expert solves problems. They are demonstrations to be imitated. This is equivalent to supervised finetuning, where the model is finetuning on "ideal responses" for an Assistant, written by humans.
3. Practice problems. These are prompts to the student, usually without the solution, but always with the final answer. There are usually many, many of these at the end of each chapter. They are prompting the student to learn by trial & error - they have to try a bunch of stuff to get to the right answer. This is equivalent to reinforcement learning.
We've subjected LLMs to a ton of 1 and 2, but 3 is a nascent, emerging frontier. When we're creating datasets for LLMs, it's no different from writing textbooks for them, with these 3 types of data. They have to read, and they have to practice.
"Move 37" is the word-of-day - it's when an AI, trained via the trial-and-error process of reinforcement learning, discovers actions that are new, surprising, and secretly brilliant even to expert humans. It is a magical, just slightly unnerving, emergent phenomenon only achievable by large-scale reinforcement learning. You can't get there by expert imitation. It's when AlphaGo played move 37 in Game 2 against Lee Sedol, a weird move that was estimated to only have 1 in 10,000 chance to be played by a human, but one that was creative and brilliant in retrospect, leading to a win in that game.
We've seen Move 37 in a closed, game-like environment like Go, but with the latest crop of "thinking" LLM models (e.g. OpenAI-o1, DeepSeek-R1, Gemini 2.0 Flash Thinking), we are seeing the first very early glimmers of things like it in open world domains. The models discover, in the process of trying to solve many diverse math/code/etc. problems, strategies that resemble the internal monologue of humans, which are very hard (/impossible) to directly program into the models. I call these "cognitive strategies" - things like approaching a problem from different angles, trying out different ideas, finding analogies, backtracking, re-examining, etc. Weird as it sounds, it's plausible that LLMs can discover better ways of thinking, of solving problems, of connecting ideas across disciplines, and do so in a way we will find surprising, puzzling, but creative and brilliant in retrospect. It could get plenty weirder too - it's plausible (even likely, if it's done well) that the optimization invents its own language that is inscrutable to us, but that is more efficient or effective at problem solving. The weirdness of reinforcement learning is in principle unbounded.
I don't think we've seen equivalents of Move 37 yet. I don't know what it will look like. I think we're still quite early and that there is a lot of work ahead, both engineering and research. But the technology feels on track to find them.
https://t.co/JCxTdKpuzv
Elon Musk tonight on overregulation:
"I got a bunch of nutty stories. SpaceX had to do this study to see if Starship would hit a shark. And I'm like... it's a big ocean. There are a lot of sharks! It’s not impossible, but it’s very unlikely. So we said, 'Fine, we’ll do the analysis. Can you give us the shark data?' They were like, 'No, we can’t give you the shark data.'
Well, then, okay, we’re in a bit of a quandary. How do we solve this shark probability issue? They said, 'Well, we could give it to our western division, but we don’t trust them.' I’m like, 'Am I in a comedy sketch here?!'
Eventually, we got the data and could run the analysis to say, 'Yeah, the sharks are going to be fine.' But they wouldn’t let us proceed with the launch until we did this crazy shark analysis.
Then we thought, 'Okay, now we’re done.' But then they said, 'What about whales?'
When you look at a picture of the Pacific, what percent of the surface area do you see as whale? If Starship did hit a whale, honestly, it’s like the whale had it coming, cause the odds are... so low. It’s like Final Destination: Whale Edition.
And then they said, 'What if the rocket goes underwater, then explodes, and the whales have hearing damage?' This is real!