Home
Language
English
Türkçe
Bahasa Indonesia
About
Privacy Policy
Terms of Service
Pricing
Sign In
Download All
Share
Mind
@gaomind
Blog📰:
Joined December 2014
388
Following
26
Followers
2.4K
Posts
gaomind
retweeted
CyrilXBT
@cyrilXBT
1 day ago
https://t.co/O0pmTcjwGL
gaomind
retweeted
Ren
@FakeMaidenMaker
20 days ago
https://t.co/ao42TbQ0HL
gaomind
retweeted
idoubi
@idoubicc
8 days ago
聊一聊 Agent 的存算分离架构设计👇 一个有灵魂,有记忆的 Agent,一次任务的生命周期包括以下步骤 1. 用户输入 query(text + files) 2. Agent 读取提示词文件(soul.md,identify.md,user.md 等) 3. Agent 读取可用的工具和技能(tools,skills 等) 4. Agent 读取记忆(memory.md,memory_search 查询) 5. Agent 构建上下文(prompt + tools + memory + query) 6. Agent 进入 Loop(LLM 调用 → 工具调用 → 观测 → 再推理) 7. Agent 交付结果(Artifacts) 什么需要存:提示词文件,工具和技能,对话记录,交付产物 什么需要算:上下文拼接,LLM 调用,工具调用 简单表示这个过程 fn(query, agent runtime) = artifacts 我们可以把 agent 运行方式简单分为三类 1. 本地裸机运行 2. 本地带沙盒(sandbox)运行 3. 云端多副本运行 --- 1. 本地裸机运行,是 OpenClaw 之类 Agent 的常见模式。Agent 提示词文件、skills,对话记录(sessions)全部存在本地磁盘,Agent 执行任务时,会在固定 workspace 目录下运行,用户上传的文件、Agent 产出的文件全部落在同一个 workspace,Agent Loop 完全依赖本地文件构建上下文和执行工具调用,存跟算是一体的。 这种模式好处是足够简单,避免了额外的文件挂载开销,弊端在于安全性,比如 Agent Loop 执行了一个 exec(rm -rf /) 工具调用,很容易对宿主机产生破坏 2. 本地带沙盒运行,是 Codex 之类的 Agent 的常见模式。主要解决两个问题。一是防止 Agent 越权操作,提高安全性;二是解决宿主机的依赖缺失导致工具调用异常的问题。 Agent Loop 执行工具调用时,涉及到敏感操作或者有外部依赖时,把宿主机的 workspace 目录挂载到 sandbox,在 sandbox 执行工具调用,输出产物自动同步到宿主机的 workspace 目录 这种模式下的存算分离,只在工具调用环节引入 sandbox 来动态计算,存储主要靠宿主机的文件系统 3. 云端多副本运行,是 Manus 之类的工具型 Agent 的常见模式。主要特点是多租户,多任务,长时间运行 像 genspark claw,kimi claw,max claw 之类的托管版小龙虾,本质上是在云端多副本运行的助理型 Agent,每个用户有独立的提示词文件,动态安装的 skills,需要长期记忆 这类 claw 托管服务,最简单的实现方式是搭建一套 k8s 集群,在每个 pod 部署一套 Agent 框架(OpenClaw,harmes 等),通过 pvc 挂载云硬盘,实现对用户资料的持久化存储。通过负载均衡策略把每个用户的请求路由到固定的 pod,在同一个 pod 做 Agent Loop,存算是一体的,每个 Agent 有独立的运行空间。这种方案隔离性很好,不好的地方在于 pod 需要常驻,运行成本很高,难以规模化 --- 云端 Agent 需要规模化(scalable),必然要结合 serverless 架构做存算分离。计算层依赖 k8s 集群的调度机制动态扩缩容,水平扩展 Agent 网关的并发处理能力 存储层结合 Agent 的运行生命周期,不同阶段的产物用不同的存储方案,主要分为四种 1. 热状态。Agent Loop 的 step,plan,游标等状态,用 kv(redis)来存,高性能,低延迟,用于异常重启后的断点恢复 2. 对话和任务记录。在任务完成后用关系型数据库(postgres)来存 3. 长期记忆。基于对话/任务记录做摘要,提取成记忆,用向量数据库(pgvector,milvus)来存 4. 工作产物。包括用户上传的文件,Agent 输出的文件,系统内置的 tools,动态创建的 skills 等,用对象存储(s3,oss)来存 --- 以 FastClaw 为例,演示基于存算分离架构的云端 Agent 的运行过程👇 1. 一套 k8s 集群,日常 2 个 pod,部署 fastclaw gateway,接收用户请求 2. 负载均衡把用户请求路由到其中一个 pod,Agent 开始计算逻辑: 2.1 从 db 读取提示词文件(soul,identity,user) 2.2 初始化 pod 内一个临时目录作为 workspace 2.3 初始化 sandbox,挂载 workspace 2.4 从对象存储下载用户资料和系统 skills 到 workspace 2.5 调用 memory_search 工具,从向量数据库查询记忆 2.6 拼接上下文,调用 llm,解析工具 2.7 在 sandbox 执行工具调用,读写 workspace 内的文件 2.8 把 Agent Loop 过程中的状态设置为 checkpoint,保存到 kv 2.9 Agent 输出结果给用户 3. 通过惰性检查,把不活跃的 sandbox 关闭,关闭前把 sandbox 内 workspace 的文件上传到对象存储 以上的存算分离架构,计算层依赖 pod + sandbox,pod 水平扩容支持并发调用,sandbox 承接少量的工具调用,使用 e2b 作为 sandbox 可以做到秒级启动,构建 sandbox 池可以提高并发容错;存储层依赖 kv + db + vector db + oss 的组合使用,瓶颈在于 io 延迟 这套架构最大的挑战在于分布式多副本场景下的数据一致性,需要合理使用锁机制和负载均衡策略。 理解了这套架构,再去看 Manus,Claude managed agents 的实现,就很好理解了。 篇幅有限,不能详述细节,欢迎留言讨论。🤗
See More
gaomind
retweeted
Jiayuan (JY) Zhang
@jiayuan_jy
3 days ago
如何从 0 到 1 玩转 Multica,开始搭建属于自己的 AI 开发团队。 视频来自
@alanhe421
https://t.co/a5i4lHKOiP
Who to follow
Owen
@verbo2013
Ex-PM & Founder, now a vibe coder/builder
扮咩吃老虎
@Uf9V5y68Do31oXP
m.otc
@otccobb
gaomind
retweeted
Serenity
@aleabitoreddit
13 days ago
在 X 上看到这么多中文社区的支持,真的让人很开心! 这体现了种非常有趣的文化差异: 大家会试图了解我的思考过程和选股逻辑,并以此来完善自己的投资体系。 相比之下,其他些文化背景的人可能上来就会全盘否定。 也许我会为了好玩,开始写写对两支中国股票的看法,哪怕我并没有持仓。
gaomind
retweeted
AYi
@AYi_AInotes
about 2 months ago
哇靠, 50个GPT-5.4同时开工, 一天之内关闭了4000个GitHub issue, OpenClaw 之父steipete昨天上线了Clawsweeper,一个专门治理代码洪流的AI维护机器人, 它24小时不间断扫描仓库里所有的issue和PR,只在证据极强的时候才建议关闭, 理由严格限定为5类,绝对不会乱关,最酷的是它没有任何传统仪表盘, 所有运行状态和统计数据直接实时写回README,极简到了极致, 50个AI agent制造了垃圾,现在用50个AI agent来清理, 以前大家都在吹AI写代码有多厉害,现在才发现,AI治理代码才是真正的刚需, 我之前也觉得这就是个高级stale bot,看完才反应过来, 这压根不是一个清理工具这么简单,更像是开源维护范式的彻底改变, 以前是人盯仓库,永远跟不上AI生成的速度,现在是AI管AI,维护成本再也不是开源项目的瓶颈了, 现在唯一的限制已经不是模型不够强,关键看GitHub和OpenAI的rate limit, 等这个问题解决了,整个GitHub的陈年垃圾可能都会被扫一遍。 老规矩GitHub地址评论区自取:
See More
gaomind
retweeted
汗青 HQ
@hq4ai
about 2 months ago
我们首次与理想汽车合作,用AI李想整了段活儿,看数据是要爆一下了。 Yuri也正式开启和理想的合作,这次先是音乐。 23年开始我们用AI尝试做“人”,庆幸一路的累积都有价值。
hq4ai's tweet video.
gaomind
retweeted
李不凯正在研究
@libukai
3 months ago
https://t.co/XI6ayn5JSr
gaomind
retweeted
艾略特
@elliotchen100
2 months ago
看了一下 CC 的 Memory 机制,不过如此嘛。 整套记忆系统的核心就是一个 MEMORY.md 文件,不超过 200 行,每次会话启动往上下文里一塞。记忆多了怎么办? 后台跑一个叫 AutoDream 的子进程,定期扫描、合并、修剪,确保塞得进去。 说白了就是:模型自己记不住,所以用文件系统 + LLM 自我管理来模拟记忆。 这个方案工程上很扎实,但有几个本质局限: 1. 存储和检索完全依赖文件系统 + Markdown,无法扩展到跨项目、跨 Agent 的场景,记忆是孤岛式的 2. 没有真正的语义索引,没有基于关联度的动态召回,200 行索引就是硬上限 3. AutoDream 的整合是规则驱动的(扫描、合并、修剪),不是认知驱动的,能去重压缩,但不能从经验中提炼出新认知 4. 没有遗忘曲线,没有记忆强化机制,记忆要么在要么被删,没有中间态 做 Memory 做久了你会发现,这类方案的天花板其实不在工程,在架构。只要模型的注意力机制本身不支持大规模历史上下文的高效检索,应用层就永远在打补丁。 这也是为什么我们在 EverMind 选了一条不同的路。前阵子发的 MSA(Memory Sparse Attention)就是在 Transformer 注意力层直接做内容感知的稀疏路由,让模型自己学会"想起什么、忽略什么",而不是靠外部脚本替它决定。 A 社的工程能力毫无疑问是顶级的。但这次泄露恰好说明:Agent Memory 这个问题,远没有被解决。
See More
gaomind
retweeted
艾略特
@elliotchen100
3 months ago
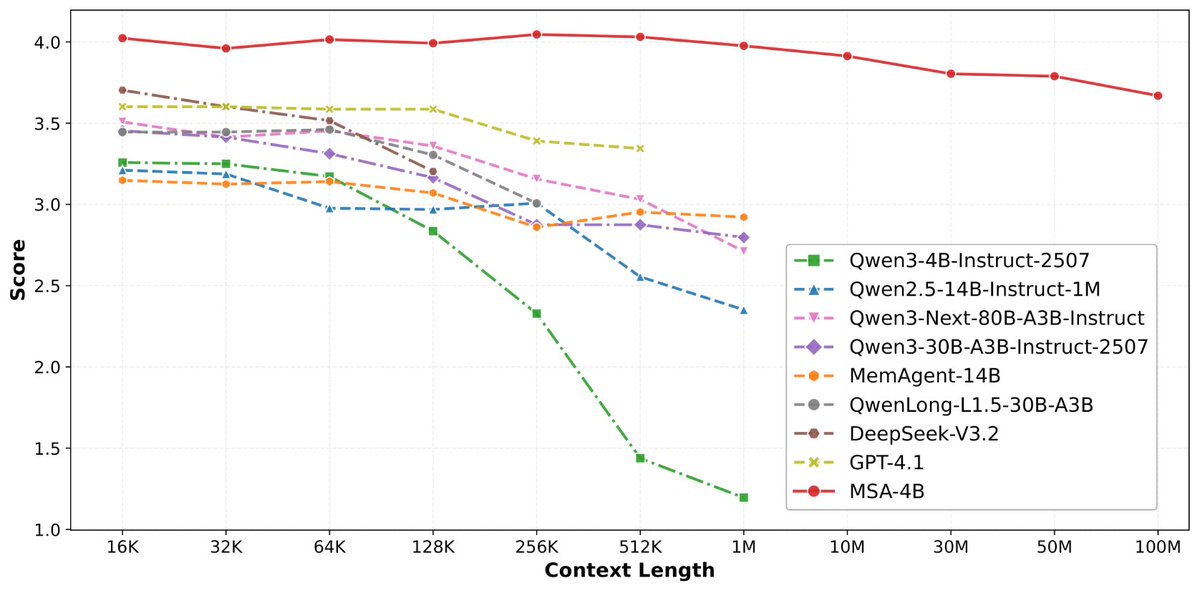
论文来了。名字叫 MSA,Memory Sparse Attention。 一句话说清楚它是什么: 让大模型原生拥有超长记忆。不是外挂检索,不是暴力扩窗口,而是把「记忆」直接长进了注意力机制里,端到端训练。 过去的方案为什么不行? RAG 的本质是「开卷考试」。模型自己不记东西,全靠现场翻笔记。翻得准不准要看检索质量,翻得快不快要看数据量。一旦信息分散在几十份文档里、需要跨文档推理,就抓瞎了。 线性注意力和 KV 缓存的本质是「压缩记忆」。记是记了,但越压越糊,长了就丢。 MSA 的思路完全不同: → 不压缩,不外挂,而是让模型学会「挑重点看」 核心是一种可扩展的稀疏注意力架构,复杂度是线性的。记忆量翻 10 倍,计算成本不会指数爆炸。 → 模型知道「这段记忆来自哪、什么时候的」 用了一种叫 document-wise RoPE 的位置编码,让模型天然理解文档边界和时间顺序。 → 碎片化的信息也能串起来推理 Memory Interleaving 机制,让模型能在散落各处的记忆片段之间做多跳推理。不是只找到一条相关记录,而是把线索串成链。 结果呢? · 从 16K 扩到 1 亿 token,精度衰减不到 9% · 4B 参数的 MSA 模型,在长上下文 benchmark 上打赢 235B 级别的顶级 RAG 系统 · 2 张 A800 就能跑 1 亿 token 推理。这不是实验室专属,这是创业公司买得起的成本。 说白了,以前的大模型是一个极度聪明但只有金鱼记忆的天才。MSA 想做的事情是,让它真正「记住」。 我们放 github 上了,算法的同学不容易,可以点颗星星支持一下。🌟👀🙏 https://t.co/Or3PVUv67q
See More
gaomind
retweeted
Kenny.eth
@_0xKenny
3 months ago
再次总结 - GitHub过去一周Coding AI开源项目星数增长Top20 1openclaw (+8.4k) 开源个人AI助手(龙虾),本地运行,支持连接WhatsApp、Telegram等任意消息平台,实现全自动化任务。 https://t.co/UNjZdVhawt 2autoresearch (+6.8k) Karpathy大神新作:AI代理在单GPU上自主进行LLM训练实验和研究优化。 https://t.co/3tQ5JAYd97 3agency-agents (+6.4k) 完整AI代理“公司”框架,内置51+专业人格代理(前端、社区、QA等),一键搭建AI团队。 https://t.co/GUlpR2vr3W 4MiroFish (+3.6k) 多智能体群智预测引擎,通过模拟平行数字世界预测新闻、政策、金融等现实事件。 https://t.co/GBmrXef8xQ 5paperclip (+3.2k) AI代理编排平台,把多个代理组成“零人力公司”,统一管理目标和成本。 https://t.co/uYOUEVLXFo 6CLI-Anything (+2.7k) 一键让任意软件生成CLI接口,让OpenClaw/Claude等AI代理轻松控制传统GUI应用。 https://t.co/DfPEZ1cyvK 7everything-claude-code (+2.6k) Claude Code全家桶工具包,包含技能、代理、钩子、规则等优化配置。 https://t.co/qb5hz8JFA1 8gstack (+2.1k) YC总裁Garry Tan分享的Claude Code实用技能栈,实现CEO/PM/QA等专业工作流。 https://t.co/ZjuVb3uqf9 9superpowers (+2k) AI编码代理技能框架+结构化开发方法论(spec→plan→TDD→review),让代理更专业。 https://t.co/qZJuR65Tiu 10RuView (+1.5k) WiFi信号转人体姿态/生命体征检测的边缘AI感知系统(无摄像头、无隐私泄露)。 https://t.co/e5MhhyGLoB 11page-agent (+1.5k) Alibaba开源的网页内GUI代理,用自然语言直接控制浏览器界面(一行代码集成)。 https://t.co/bGXDW47Ha1 12skills (+1.4k) OpenAI Codex技能目录,为AI编码代理提供可复用任务指导和脚本。 https://t.co/Xg75atYpTs 13awesome-openc la… (+1.4k) OpenClaw技能awesome列表,收集数千个实用扩展和真实用例。 https://t.co/IKQw2147LL 14public-apis (+1.1k) 经典免费公共API集合,AI代理集成外部数据的必备宝库。 https://t.co/VZQl45jO7N 15cli (+1.1k) Google Gemini CLI终端AI代理,支持代码生成、调试和复杂自动化任务。 https://t.co/5EDmXhoyLB 16OpenViking (+1.1k) AI代理专用上下文数据库(文件系统范式),管理记忆/资源/技能,支持自演化。 https://t.co/lmlXWnwoNM 17BitNet (+1.1k) Microsoft 1-bit LLM官方推理框架,极低资源运行大模型(CPU/GPU)。 https://t.co/uq0ZT5TOBN 18AstrBot (+1k) 多平台Agentic聊天机器人框架(QQ/微信/Telegram等),支持RAG、工具调用和子代理。 https://t.co/Tv3wBoXMS1 19worldmonitor (+1k) AI驱动的全球实时情报仪表盘,聚合新闻、地缘政治和基础设施监控。 https://t.co/z1reWnF5YE 20browser (+958) 专为AI代理设计的无头浏览器(Lightpanda),高速网页自动化和LLM训练支持。 https://t.co/ws1loWODsi
See More
gaomind
retweeted
阿蔺A-Lin
@alin_zone
3 months ago
https://t.co/j9mXC1SILX
Mind
@gaomind
3 months ago
哈哈
Fenng
@Fenng
3 months ago
你有哪些给 20 岁的年轻人的忠告系列之:
gaomind
retweeted
静曼婉儿
@BGlayds30098
4 months ago
哈佛研究發現斷絕孩子手機上癮最快的偏方:麵包效應
BGlayds30098's tweet video.
gaomind
retweeted
iGeekbb
@igeekbb
4 months ago
如今我好像明白什么是普通人了
gaomind
retweeted
Kieran Zhang
@ninthbit_ai
4 months ago
https://t.co/STBpES2Bm2
gaomind
retweeted
Wang Shuyi
@wshuyi
5 months ago
解答星友疑惑,对几个相关概念做了讲解和辨析:
gaomind
retweeted
超级个体|柿子
@yaohui12138
4 months ago
我在百度做PM那几年,发现一个特别有意思的事 技术团队开会,聊的永远是架构、性能、代码优化 运营团队开会,关心的是DAU、转化率、活动RO 商务团队开会,盯着的是签约额、客户关系、商务谈判 每个团队都觉得自己的事最重要,自己的方法论最科学 更诡异的是,他们看不见彼此的价值 技术觉得运营只会提无脑需求 运营觉得技术只会说"做不了" 商务觉得产品不懂生意 每个人都活在自己的"正确"里 其实想了一下,这不是大厂独有的问题 这是所有人都会遇到的认知陷阱 你在一个圈子待久了 那套话语体系、评价标准、行为模式就会固化成你的操作系统 体制内的人张口就是编制、级别、退休年龄 创业圈的人满脑子都是PMF、融资、增长黑客 打工人念叨的永远是KPI、跳槽、涨薪 每个圈子都有一套自己的"成功学" 问题不在于这些规则本身 问题在于:你以为这就是全世界的规则 这就是你的认知边界 我刚从大厂出来做独立开发者的时候 花了很久才意识到一个残酷的事实 在大厂那套"需求评审→排期→上线→复盘"的完美流程 在超级个体这里完全不work 用户不care你的需求文档写得多漂亮 他们只在乎:你的东西能不能马上解决我的问题 这就是圈层差异带来的认知断层 大多数人其实意识不到自己在塔里 他们会说: "我这行就是这样的" "行业规则就是如此" "不这么做肯定不行" 这种笃定的语气背后,是认知的固化 PM这个岗位教会我最重要的一件事: 跨部门协作的本质,就是在不断打破认知边界 你得学会用技术的语言跟工程师沟通 用数据的逻辑说服运营 用商业价值打动老板 不是你厉害,是你被逼着在不同的"象牙塔"之间来回切换 久而久之你就会发现 原来世界不只有一套规则 每个圈层都有自己的信息密度、认知深度和价值判断 真正的认知升级,不是学会某个圈子的规则 而是能在不同圈子之间自由切换 结合我的过往经历,总结了我实践过的3个具体的方法 方法1:主动接触"不舒服"的圈子 如果你是技术 去跟销售聊聊他们怎么谈客户 去看看运营怎么做活动策划 如果你是运营 去了解技术架构的底层逻辑 去理解为什么有些需求"做不了" 不是为了转行 是为了看见更大的世界 方法2:用翻译思维沟通 我做PM时有个习惯 跟技术沟通,我会把需求翻译成"技术实现成本" 跟运营沟通,我会把功能翻译成"用户价值" 跟老板汇报,我会把进度翻译成"商业回报" 同一件事 在不同圈层里要用不同的语言表达 这不是八面玲珑 这是降低信息不对称的成本 方法3:定期"反思"自己的认知边界 每个季度问自己: 我最近接触了哪些新领域 我的信息来源是否过于单一 我是否在用老方法解决新问题 如果答案都是"没有" 那你大概率正在塔里 AI时代,超级个体最大的竞争力不是掌握某个工具 而是跨圈层的认知整合能力 技术圈的人懂产品思维 产品圈的人懂商业逻辑 商业圈的人懂技术趋势 这种 T型人才 才能在信息密度爆炸的时代里 看到别人看不见的机会 如果你现在的朋友圈、信息源、话题都高度一致 如果你听到不同观点的第一反应是反驳而不是好奇 如果你觉得我这行就是这样 那恭喜你 你已经在塔里了 突破的第一步 不是学什么新技能 而是承认:我可能活在一个我不知道的认知泡泡里
See More
gaomind
retweeted
沉浸式翻译
@immersivetran
4 months ago
这个一定要推荐给你们!!!昨天刷到了一个宝藏书库 https://t.co/3UskGQgU9a,它厉害的地方在于:不是让你在海量书海里随便翻,而是把「人」放在前面。 它不是那种常见的「大而全书库」,而是专门去整理“世界上最成功、最有影响力、最有意思的人”都推荐过什么书。 这网站做得很克制,只干一件事:从公开信息里,把这些人的书单扒出来,认真整理给你看。 他们说自己分析了上万条公开推荐,最后筛出 8000+ 本被高频提到的书,等于帮你提前做了一遍“质量过滤”。 你可以按行业筛人:创业、科技、写作、媒体、投资、娱乐、体育等,各个圈子的代表人物都在里面。 如果你是在创业,想拉升自己的决策水平,那最简单的玩法就是: 先选 3–5 个你很认可的创始人或投资人,把他们重复推荐的那批书列出来,这就是你接下来一两年的核心清单。 相比到处搜“创业必读 50 本”,这个清单更像是“实战派给你开的处方”。 网站还有一个「All books」和「Most Recommended」专区,把所有书按分类和“被推荐次数”做了拆分。 你想看自我提升,就进 self improvement;想提升判断力,就看 psychology、business、economics 这些分类,所有书都是真实有人推荐过,而不是机器人拼出来的列表。 对普通读书人,它解决的痛点: 第一,信息太噪音了。 到处都是“年度必读”“改变命运的十本书”,但很多书一年后就没人提。 https://t.co/3UskGQgU9a 反其道而行,它不跟你玩情绪冲击,只给你看一个事实:哪些书,在不同的人、不同时间点,被一再提起。 第二,时间有限,不想再乱投。 我们这一生真正能完整读完、认真吸收的书,其实就那么几十到一两百本。 如果你承认这是现实,那问题就变成了:怎样让这几十本的“命中率”尽可能高? 这时候,跟着那些你认可的高成就者,去看他们反复推荐的书,是一个非常朴素但有效的策略。 第三,不知道怎么搭「阅读结构」。 有的人书买得很多,但书架像杂货铺:一点心理学、一点理财、一点故事,没有主线。 https://t.co/3UskGQgU9a 间接逼你先想清楚一个问题:你想成为什么样的人? 想提升写作,就去看成功作家在读什么;想写内容,就看媒体人和创作者在读什么;想走投资这条路,就看投资人密集推荐的那几本经典。 https://t.co/3UskGQgU9a 走的是一条很“人工”的路: 它不听你的历史行为,而是直接把你丢到一群厉害的人中间,让你自己选——你更想谁来当你的“阅读教练”。 与其被算法温柔包裹,不如主动对齐你认可的人,这就是它最大的杀伤力。 它特别适合这三类人: 想提升自己的知识密度,但不想再被各种“碎片化鸡汤”绑架 想认真做内容、写作、产品、投资,需要一套长期可复用的知识底座。 已经被各种书单刷麻了,开始在意“谁在推荐”远大于“书封面有多好看”。
See More
gaomind
retweeted
Marvix
@nanshanjukr
4 months ago
https://t.co/t45NxDaG8A
Last Seen Users on Sotwe
Not not
Seen from
Indonesia
jojoe225544
Seen from
Thailand
清水举
Seen from
Indonesia
baja hitam
Seen from
Indonesia
Budak nakal
Seen from
Malaysia
ellol🔥
Seen from
Germany
งานไทยเด็ดrarethaixxx
Seen from
Thailand
GMhijabpass
Seen from
Canada
Jancok69
Seen from
Germany
Gar 🔻
Seen from
Singapore
Trends for you
1
Karmelo
Under 10K tweets
2
Belfast
Under 10K tweets
3
Nintendo
Under 10K tweets
4
#loveislandusa
Under 10K tweets
5
Ireland
Under 10K tweets
6
Knicks
Under 10K tweets
7
Fable 5
Under 10K tweets
8
Zelda
Under 10K tweets
9
California
Under 10K tweets
10
Ocarina of Time
Under 10K tweets
Most Popular Users
1
Elon Musk
@elonmusk
240.1M followers
2
Barack Obama
@barackobama
119.3M followers
3
Donald J. Trump
@realdonaldtrump
111.6M followers
4
Cristiano Ronaldo
@cristiano
109.2M followers
5
Narendra Modi
@narendramodi
106.9M followers
6
Rihanna
@rihanna
97.3M followers
7
NASA
@nasa
92.1M followers
8
Justin Bieber
@justinbieber
90.6M followers
9
KATY PERRY
@katyperry
86.9M followers
10
Taylor Swift
@taylorswift13
80.7M followers
11
Lady Gaga
@ladygaga
72.3M followers
12
Kim Kardashian
@kimkardashian
69.4M followers
13
Virat Kohli
@imvkohli
68.7M followers
14
YouTube
@youtube
68.6M followers
15
Bill Gates
@billgates
63.5M followers
16
The Ellen Show
@theellenshow
62.5M followers
17
CNN
@cnn
61.9M followers
18
Neymar Jr
@neymarjr
61.3M followers
19
X
@x
60.9M followers
20
Selena Gomez
@selenagomez
60M followers
Olivia
Online
✨
⭐
💫