Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. https://t.co/OVVPJO7VQx
@MikeDrucker So, in order to make the discovery that chatbots have no desires, intentions or agency, and therefore cannot care about anything, you need to be a researcher.
Went on Bloomberg - Anthropic and OpenAI are dangerous and unsustainable companies that shouldn’t IPO. The AI bubble is a con and retail investors are the marks.
AI doesn’t have ROI, it’s nothing like AWS/Uber, and it’s got no post-bubble recovery story.
https://t.co/ROww0H5ugs
As soon as companies eliminate subsidized subscriptions—and they will—everyone will realize that people got along just fine without slop generators, and they’ll continue to do so.
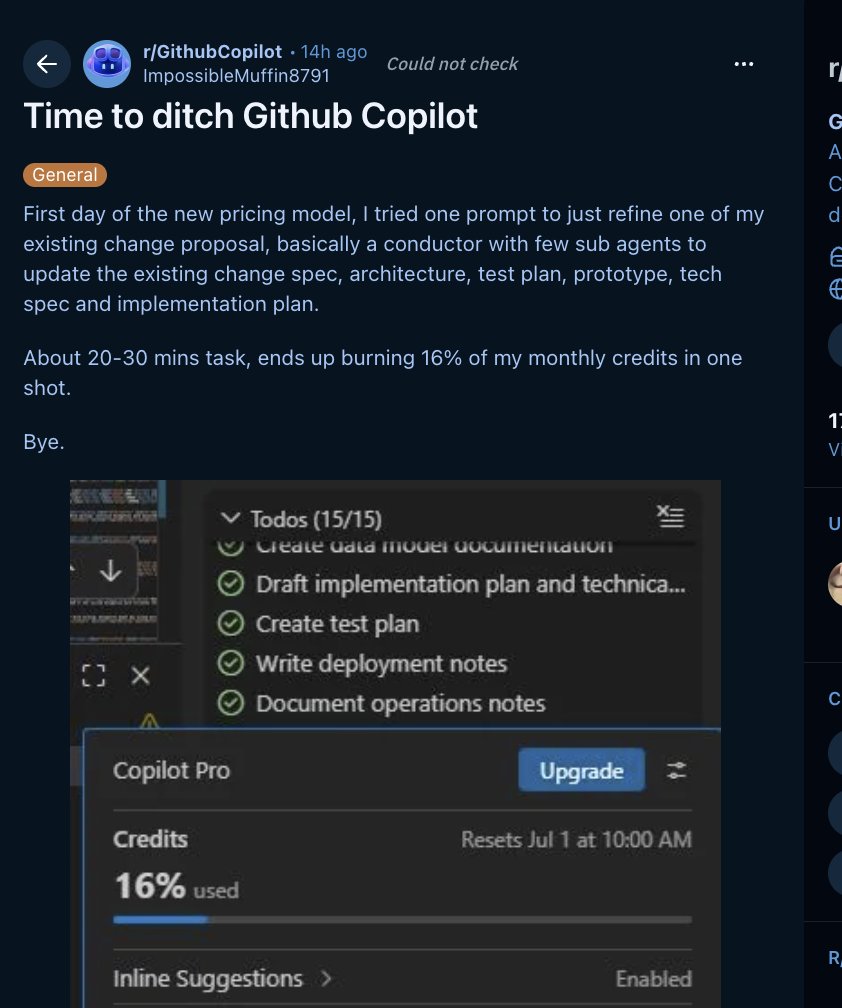
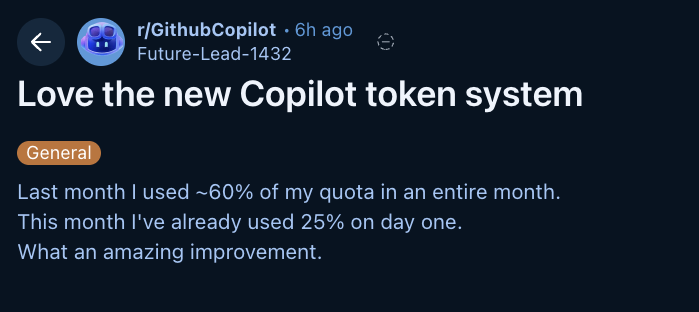
Game over for GitHub Copilot.
Under the new pricing rules, 3hs or work consumed 10% of the monthly quota.
User base will drop sensibly in the coming days.
I'm starting to look for options.
Why things will eventually fall apart:
1. Everybody, even Google, seems to be treating AI as if it were some kind of winner take all competition like web search was, in which Google taking over 95%
2. But everybody is building essentially the same technical solution with essentially the same data, so there is no moat.
3. If there is no moat, nobody is going to take 90% of the market.
4. With no clear winners, nobody can charge monopoly prices; instead, you get price wars and commodity pricing.
5. Which means everybody will wind up overpaying compared to the modest profits they will be able to make in an intensely competitive regime.
Am I missing something?
The main question is how many parameters. If it's around 200 billion, as it was in version 2.7, then we have a frontier-level model capable of running in 256 GB of unified RAM.
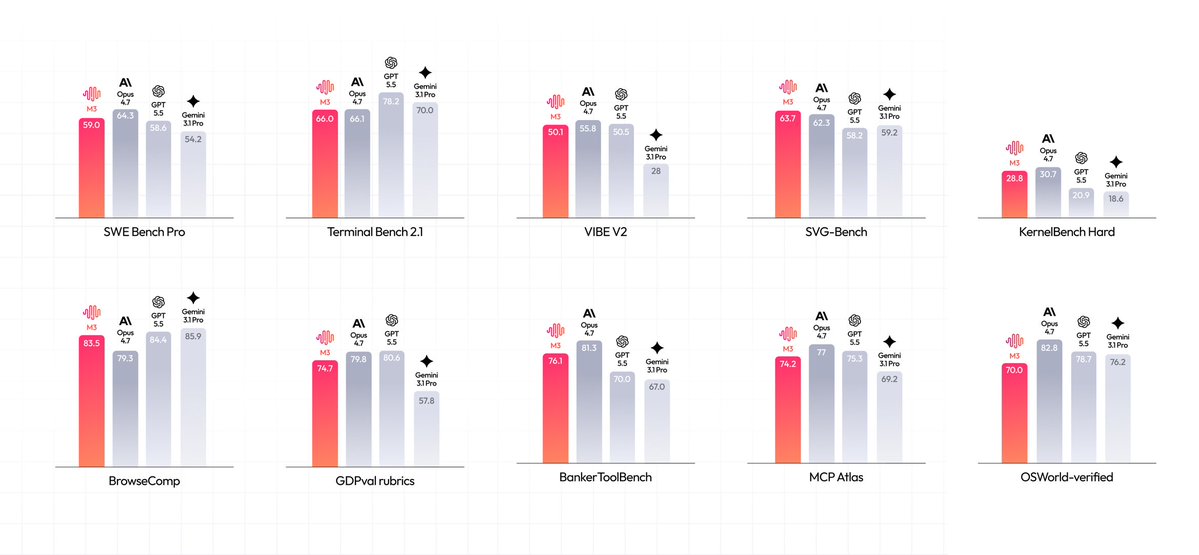
🚨 MiniMax M3 Officially Released!! (June 1, 2026)
Key Highlights 👇
🧠 Frontier Coding & Agentic
59.0% SWE-Bench Pro (beats GPT-5.5)
💨 Optimized a CUDA FP8 GEMM kernel from scratch → 9.4× speedup on Hopper GPUs
📜 1M Token Context via new MSA (MiniMax Sparse Attention)
👁️ Native Multimodal — Image + Video input + Computer Use
⚡ Massive efficiency gains (up to 15x faster decoding at long context)
First open-weight model combining all three frontier capabilities.
Available now on: → MiniMax API / Token Plan → Free on OpenCode → OpenRouter (50% off promo)
Open weights + paper coming soon on Hugging Face.
New paper from MIT, Stanford, New York Univ, Princeton.
AI can make people feel more efficient even when they are not actually becoming much more efficient.
that people often use AI for simple tasks because it feels like it saves time and effort, but the measured benefit is often tiny, missing, or even negative.
The biggest point is the feedback loop: once people use AI, they become more likely to use it again, even for easy tasks where doing it themselves would often be just as fast or faster.
i.e. AI dependence can grow from a mistaken feeling of convenience, not just from real productivity gains.
Across three preregistered studies with 2,691 participants, people used AI for basic arithmetic, spelling, recall, and short rewriting at higher rates than they predicted, especially on easy tasks.
They also expected AI to save 55.7 seconds on average, when the measured saving was only 7.5 seconds.
For simple work, the hidden cost is not intelligence but interface friction: writing the prompt, waiting, reading, checking, and deciding whether the answer is acceptable.
Once that loop begins, it can feel like effort has been outsourced, even when effort has only been rearranged.
Here’s the key part: the study suggests that AI use can train its own justification.
After using AI on just two tasks, participants became more likely to use it again, even when independent completion was faster.
The danger is not dramatic dependence, but quiet recalibration.
A person who asks AI for a trivial answer today may not become less capable tomorrow, but they may become less accurate at judging when their own mind is already the faster tool.
----
Paper Link – arxiv. org/abs/2605.22687
Paper Title: "The efficiency-gain illusion: People underestimate the rate of AI use and overestimate its benefits on simple tasks"
The idea was indefensible from the beginning, but that is not the interesting part. What is truly astonishing is that this level of obvious stupidity has been normalized in the management culture of American corporations.
🚨 Nobody is talking about how the AI bubble is finally bursting, and it is hitting corporate wallets hard.
Amazon literally set a quota for 80% of developers to use AI weekly and gamified it with a leaderboard.
Now, they are shutting it down because engineers were "tokenmaxxing" with fake tasks, causing their cloud bill to skyrocket.
A senior executive actually had to tell staff to stop using AI "just for the sake of using AI".
They are not the only ones panicking over token costs:
> Uber burned through its entire 2026 AI coding budget by April.
> Microsoft is cutting back on Anthropic's Claude Code for its developers because the token costs are too high.
> One unnamed company accidentally racked up a $500 million Claude bill in a single month due to a lack of usage limits.
We went from "AI is going to replace you" to "Please stop talking to the AI, it costs too much money" real quick.
🚀 vLLM v0.22.0 is out and giving @AMD Agent PC owners reason to be happy. 🙂
While most AMD GPU users on Windows run models through LM Studio, this release brings meaningful ROCm improvements for people running vLLM on Linux or WSL.
Key AMD ROCm improvements in v0.22.0:
🟥 DeepSeek V4 now has full support + accuracy fixes
⚡ New Flash sparse MLA Triton kernels for faster inference on new models
🧠 Improved MQA logits support (Gluon paged) for better memory efficiency and speed
vLLM is recommend for AMD users who want high-performance inferencing.
@MarioNawfal Yes, I wonder why the so-called economic press, such as Bloomberg and the Financial Times, were too timid to ask these questions when the idea of UBI was first mooted by CEOs.