Why is constrained neural language generation particularly challenging? https://t.co/tNArBL85XG
In our TMLR 2025 paper, we discuss approaches, learning methodologies and model architectures employed for generating texts with desirable attributes.
By modeling these features, we predict user-specific rankings and cut prediction error by up to 35% over aggregate baselines! 📉✨
Read the paper here: https://t.co/DINOTwG3Kz
When did you last check a leaderboard before picking an LLM? 🤔 Excited to share that our paper "Personalized Benchmarking: Evaluating LLMs by Individual Preferences" was accepted to ACL Findings 2026! 🎉 Joint work with Heran Wang and @ChenhaoTan
We found that for 57% of active Chatbot Arena users, individual rankings are statistically indistinguishable from a random ordering of models under Bradley-Terry. Users show substantial heterogeneity in topical interests and communication styles.
World models for better decisions.
Aug 31–Sep 2, hosted by @ChicagoBooth. WM@booth brings together CS, econ, finance + social science researchers, with keynotes from @ylecun and @Diyi_Yang.
CfP due June 12 → https://t.co/NwKitXGUsS
I find myself repeatedly explaining the difference between open-weight (DeepSeek), open-source (Olmo), open-development (Marin). Let's see if this restaurant analogy helps:
- Open-weight: food is made behind closed doors, server brings you the dish
- Open-source: food is made behind closed doors, server brings you the dish and the recipe
- Open-development: you see the chef make the dish in the kitchen (and can shout suggestions while its cooking)!
Day 1 afternoon keynote talk given by Max Welling @wellingmax#ICLR2026
From Physics to AI to Materials; A Journey from Foundations to Impact
"Do we reward strange new, potentially paradigm-shifting ideas or do we focus on engineering, scaling and bold numbers?"
Long COVID doesn’t come out of nowhere. It starts with COVID infection.
The most reliable way to reduce your risk is to prevent getting COVID in the first place. Clean air, well-fitted respirator masks, testing regularly and staying home when sick all help lower exposure and protect your health long term.
#InfectionPrevention #LongCOVID #COVID19 #COVID #COVIDIsNotOver #PublicHealth
Following positive feedback from other venues, like STOC and ICML, NeurIPS is pleased to announce a new initiative in partnership with Google: for NeurIPS 2026, authors will have access to Google's Paper Assistant Tool (PAT) to help improve their submissions.
This program offers authors the opportunity to receive free, automated, and actionable feedback on their manuscripts before the final deadline, private to the authors. It is a completely optional service that is kept strictly private to the authors and will not be used in the review process.
Read more in our blog post: https://t.co/TSipYCJ3CG
ICLR 2026 is almost there! We have 6 exciting keynotes covering a range of areas from machine learning to robotics, neuroscience and AI for science:
Maja Matarić, Max Welling, Percy Liang, Katie Bouman, Karen Adolph, Pablo Arbeláez
See you all soon! #ICLR2026
Not many PhD students know about compute grants, but they can make a huge difference. During my PhD, I got access to Stability AI's HPC cluster through a small proposal and used it for Self-RAG training.
Great practical post by @_emliu!
Excited to launch the accompanying free RLHF Course for my book. To kick it off, I've released:
- Welcome video
- Lecture 1: Overview of RLHF & Post-training
- Lecture 2: IFT, Reward Models, Rejection Sampling
- Lecture 3: RL Math
- Lecture 4: RL Implementation
I'm going to add question & answer videos throughout the lecture to go deeper on topics that need it, and potentially cover some topics that are too recent and in flux to go in print. I expect 10-15 videos in total over the next few months.
At the same time, development around the code for the book is picking up. It's a great time to build the foundation for post-training methods.
YT playlist and course landing page below.
Excited to announce the 2026 iteration of the Communication & Intelligence Symposium at UChicago!
We have an amazing lineup of speakers @Diyi_Yang@johnhewtt@dashunwang@TomerUllman
We have a simple call for abstract that is due on Apr 15 (links 👇). Please come and share your research!
Co-organized with the awesome @universeinanegg and @divingwithorcas
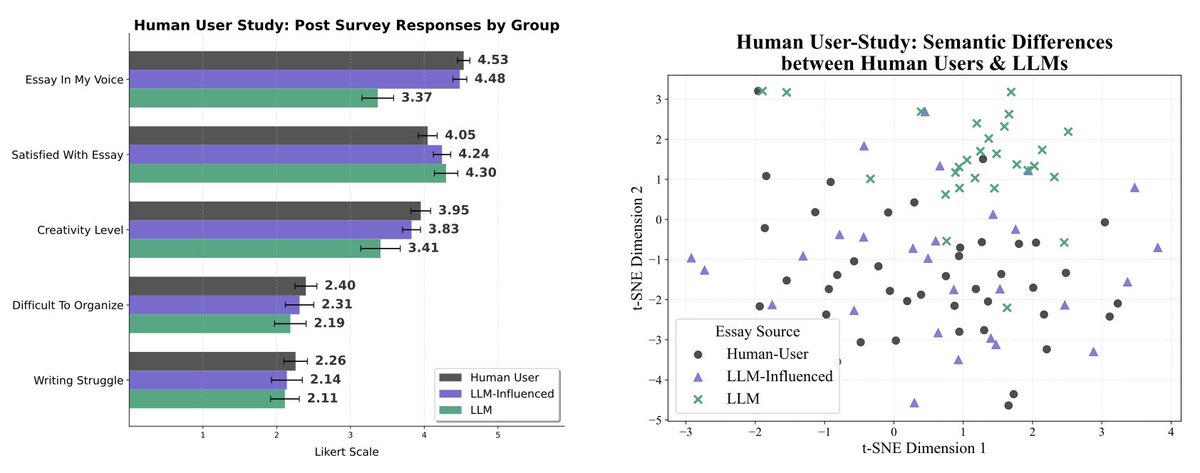
Why am I obsessed with this? LLMs do not preserve our intentions or diversity of thought in writing, and they’re already being adopted en masse. More than 1 billion people worldwide use them on a weekly basis. Existing work has shown that for individual scientists, using LLMs to generate papers increases your productivity and impact, even though it constricts science’s overall focus. In our study we show that even though participants who rely on LLMs say their writing is significantly less creative and not in their voice, they are paradoxically equally satisfied with the output. So, the adoption of LLMs is not going to slow any time soon. But it’s already affecting our cultural institutions and the way we conduct science. We urgently need more research into how massive, widespread LLM adoption will affect our science, politics, and culture.
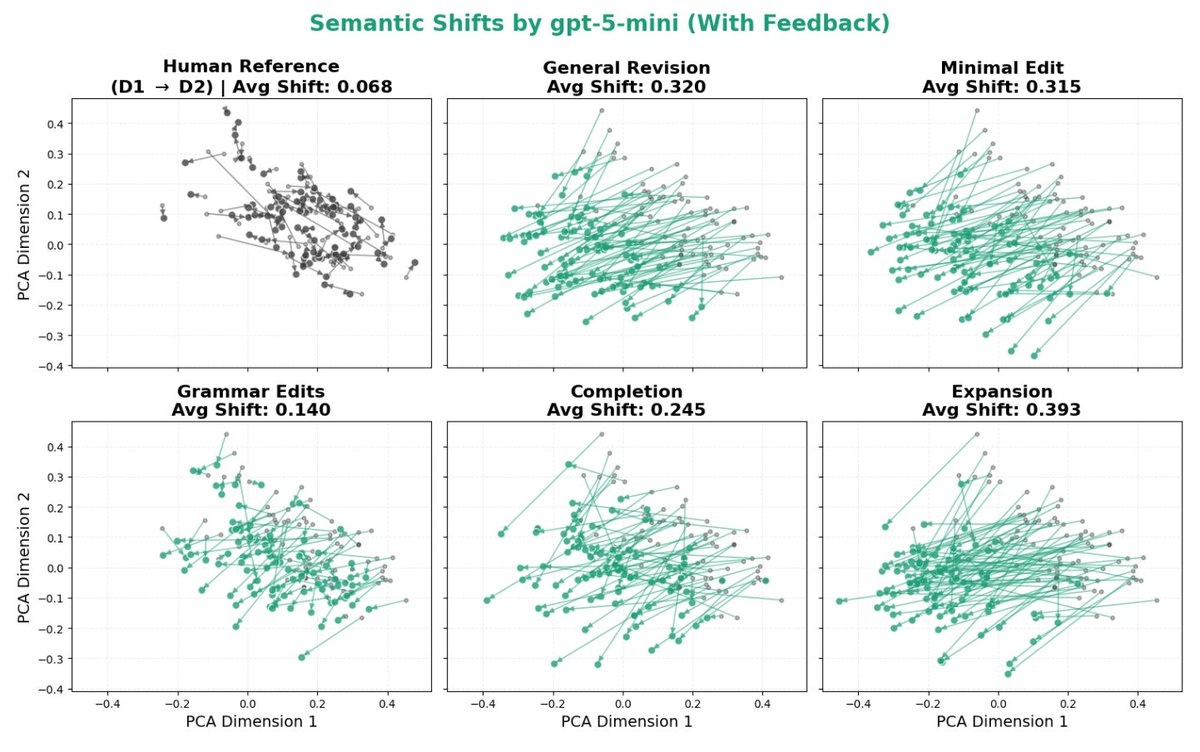
The paper I’ve been most obsessed with lately is finally out: https://t.co/KgdWKknCJK! Check out this beautiful plot: it shows how much LLMs distort human writing when making edits, compared to how humans would revise the same content.
We take a dataset of human-written essays from 2021, before the release of ChatGPT. We compare how people revise draft v1 -> v2 given expert feedback, with how an LLM revises the same v1 given the same feedback. This enables a counterfactual comparison: how much does the LLM alter the essay compared to what the human was originally intending to write? We find LLMs consistently induce massive distortions, even changing the actual meaning and conclusions argued for.