this weekend only: every serverless credit purchase is doubled through sunday 11:59 pm.
add $20 → get $40 to spend
add $100 → get $200 to spend
use the bonus credits to try glm 5.1 - delivered at 150-250 tok/s, among the fastest speeds available, while remaining 30%+ cheaper than the next closest competitor.
ends sunday at 11:59 pm: https://t.co/KrlZFPKK6C
Excited to announce Slashy
The first email client that works for you.
The real cost of email isn't the time. It's the mental load of constantly checking it, just in case something needs you.
Slashy kills that. You never need to open your inbox unless Slashy tells you.
Try it out at https://t.co/6tuQxWV7KR
New: A group of AI researchers from Google DeepMind, Apple, MSL, and OpenAI are launching a new startup called Trajectory to build a continual learning platform for companies.
They've raised a $15M seed round from Sarah Guo's Conviction, Jeff Dean, Fei-Fei Li, and others.
🎉 Excited to welcome @wafer_ai to Infron as a provider.
Wafer does what used to take a team of world-class performance engineers automatically. Their AI agents optimize GPU inference across any hardware, finding the configurations that matter.
Infron is a unified AI gateway: 400+ models, 100+ providers, one API key, zero markup.
⚡Cheap intelligence is the most essential technology for the future. Wafer and Infron are making that real.
Wafer-optimized Qwen3.6-35B-A3B is now available on Infron:
🔗 https://t.co/dtsJ7neqUU
#AIInfrastructure #AIGateway #LLMOps #Infron #Wafer
New blackboard lecture w @reinerpope
How do chips actually work – starting with basic logic gates, and working up to why GPUs, TPUs, FPGAs, and the human brain each look the way they do.
0:00:00 – Building a multiply-accumulate from logic gates
0:16:20 – Muxes and the cost of data movement
0:25:59 – How systolic arrays work
0:39:00 – Clock cycles and pipeline registers
0:51:40 – FPGAs vs ASICs
1:03:14 – Cache vs scratchpad
1:07:16 – Why CPU cores are much bigger than GPU cores
1:11:49 – Brains vs chips
1:15:22 – A GPU is just a bunch of tiny TPUs
Look up Dwarkesh Podcast on YouTube/Spotify/etc to watch. Enjoy!
New blackboard lecture w @reinerpope
How do chips actually work – starting with basic logic gates, and working up to why GPUs, TPUs, FPGAs, and the human brain each look the way they do.
0:00:00 – Building a multiply-accumulate from logic gates
0:16:20 – Muxes and the cost of data movement
0:25:59 – How systolic arrays work
0:39:00 – Clock cycles and pipeline registers
0:51:40 – FPGAs vs ASICs
1:03:14 – Cache vs scratchpad
1:07:16 – Why CPU cores are much bigger than GPU cores
1:11:49 – Brains vs chips
1:15:22 – A GPU is just a bunch of tiny TPUs
Look up Dwarkesh Podcast on YouTube/Spotify/etc to watch. Enjoy!
we recently optimized qwen3.5-397b-a17b to be the fastest deployment publicly hosted.
and the crazy thing: we did it by writing CUSTOM KERNELS for AMD MI355x. 🍿
see our post below outlining how we optimized kernels to achieve SOTA performance.
You have to read this one.
We just published a recap into how @wafer_ai pushed @AMD inference performance to a level that’s getting the entire ecosystem’s attention and the results are kind of wild.
What makes this story interesting isn’t just the performance itself. It’s how they achieved it: systems-level optimization, smart inference tuning, and a belief that AMD can compete at the very highest tier.
Proud this work was powered on TensorWave’s AMD-native cloud infrastructure and early #MI355X deployments.
https://t.co/8q1KPgHnYf
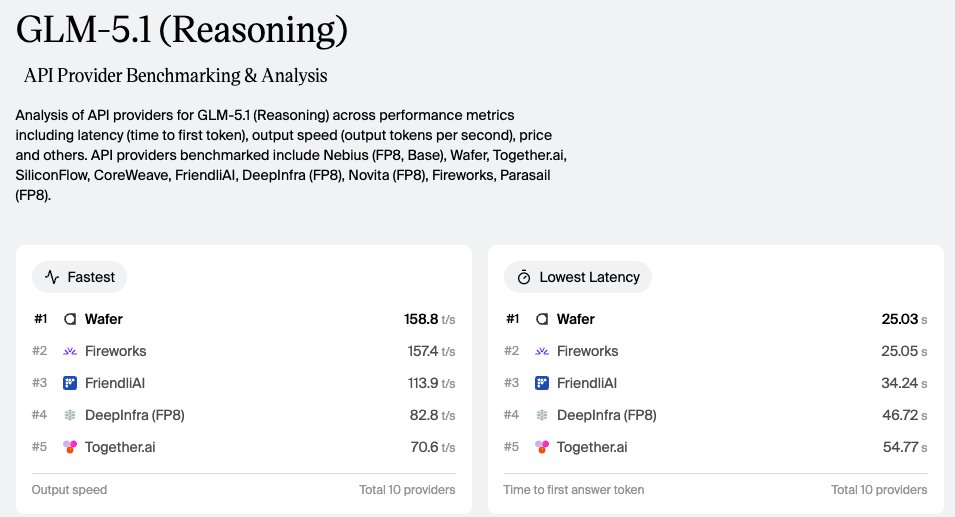
Incredible #1 result for @wafer_ai.
Wafer, $4M raised, ~1 year old
DeepInfra, $133M raised, ~3.7 years old
Together AI, ~$534M raised, ~4 years old
DigitalOcean, ~$493M raised, ~14 years old
Nebius/Eigen, ~$12.2B raised, 20 years old