Which models believe the death penalty can be a just punishment? o3 and Grok 3 do, others don't
I created a MicroEval to understand how models will respond to controversial questions including relating to political, ethical and social topics.
Link in the tweet below to read answers from o3, Grok 3, Gemini 2.5 Pro, DeepSeek R1 & others 🔗
Interestingly OpenAI's o3 and GPT4.1, and xAI's Grok 3 and Grok 3 mini respond with different answers
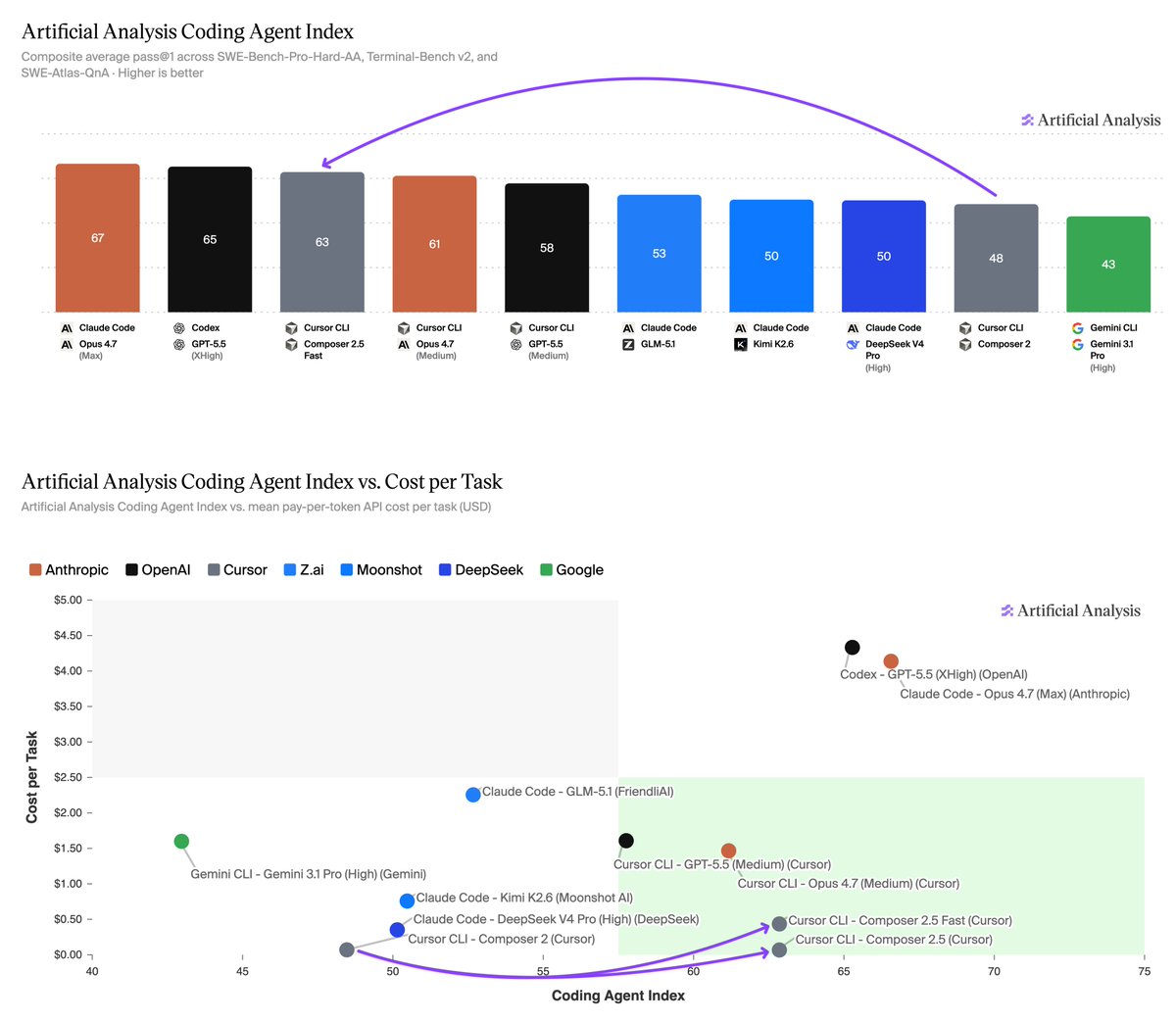
Cursor Composer models previously never made sense to use considering other models out there. Now there is a reason to use it, almost as good as Opus 4.7 and GPT-5.5 but >10X cheaper
Cursor's new Composer 2.5 takes third on the Artificial Analysis Coding Agent Index and is ~10-60x lower cost than the higher-effort Opus 4.7 and GPT-5.5 variants above it. This release puts Composer among the leading coding agent models, something that wasn’t clear for past releases
@cursor_ai has released Composer 2.5, the latest model in its Composer line. Composer 2.5 scored 62 on our Coding Agent Index, a 14 point gain over Composer 2 (48). This puts it in third place of our tested agents, behind only Claude Opus 4.7 (max) in Claude Code (66) and GPT-5.5 (xhigh reasoning) in Codex (65). These cost $4.10 and $4.82 per task respectively, ~10x the cost of Composer 2.5 Fast ($0.44) and ~60x the cost of Composer 2.5 standard ($0.07).
Key results for Composer 2.5 in Cursor CLI:
➤ Cost-quality Pareto frontier: At $0.07 (standard) and $0.44 (Fast) per task, Composer 2.5 is cheaper than every other agent scoring above 60 on the Index. Medium-effort peers cost $1.24–$2.21 per task; higher-effort variants land 3-4 points above at $4.10–$4.82
➤ Per-benchmark gains vs Composer 2: +35 points on SWE-Bench-Pro-Hard-AA (12% → 47%), +2 points on Terminal-Bench v2 (64% → 66%), and +3 points on SWE-Atlas-QnA (69% → 72%). At 47%, Composer 2.5's score on SWE-Bench-Pro-Hard-AA is comparable to Claude Opus 4.7 (max) in Claude Code
➤ Among the fastest coding agents: Composer 2.5 Fast runs at an average wall time of 6.7 minutes per task, the third-fastest agent on the Artificial Analysis Coding Agent Index, behind only Claude Opus 4.7 (medium) in Claude Code (5.8m) and GPT-5.5 (medium) in Cursor CLI (6.2m)
➤ Fast mode enables better responsiveness at 6x pricing: Fast runs 30% faster than standard Composer 2.5, but is ~6x the cost per task ($0.44 vs $0.07). Token pricing is 6x higher for Fast: $3.00/$15.00 vs $0.50/$2.50 per million input/output tokens
Model details:
➤ Base model: Continued training on @Kimi_Moonshot's open weights Kimi K2.5 as with Composer 2, with Cursor reporting ~85% of total compute from its own additional training and reinforcement learning
➤ Pricing: $0.50/$2.50 per million input/output tokens for the standard variant; $3.00/$15.00 for the Fast variant (the default in Cursor)
➤ Available exclusively in Cursor: both Cursor IDE and Cursor CLI, an externally accessible API is not available
Congratulations @cursor_ai and @mntruell on the impressive release!
@__codewithkai__@ArtificialAnlys This is just a legend component for where publishing claimed results. As none of the bars in the chart have striped pattern none are lab claimed - all these are independently benchmarked by us!
Anthropic launched Claude Opus 4.7 today, the new #1 in our GDPval-AA benchmark for performance on agentic real-world work tasks
Opus 4.7 scored 1753 on GDPval-AA at launch with its ‘max’ effort setting, surpassing GPT-5.4 xhigh.
This is a significant upgrade, placing Opus back on top of Sonnet on the GDPval-AA leaderboard. Compared to OpenAI’s GPT-5.4, it has an implied win rate of ~60% when compared head-to-head on the GDPval task set.
We supported @AnthropicAI with testing this model ahead of release and appreciate them referencing our evaluations in their announcement post and system card for both GDPval-AA and AA-Omniscience.
We’re actively conducting the rest of the Artificial Analysis Intelligence Index evaluations and will share complete results soon!
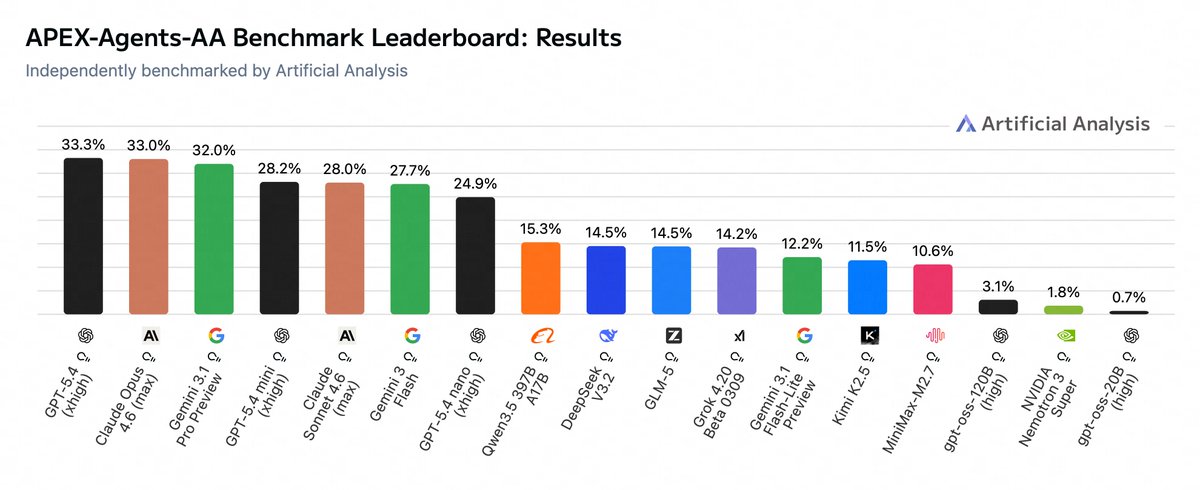
Announcing APEX-Agents-AA, our latest leaderboard on Artificial Analysis, evaluating AI agents on long-horizon professional services tasks with realistic application dependencies
This is our implementation of the APEX-Agents benchmark - an agentic work task evaluation open-sourced by @mercor_ai. It tests AI agent ability to execute realistic tasks created by investment banking analysts, management consultants, and corporate lawyers. Mercor released extensive data to enable model evaluation and training across the community, comprising 480 tasks including tool implementations, rubrics, and grading workflows.
We exclude tasks with external service dependencies and run the remaining 452 tasks for APEX-Agents-AA. Models complete tasks using Stirrup, our open-source agent harness as used in GDPval-AA, and a customized tool set based on the original benchmark implementation
Results overview:
🏅 OpenAI, Anthropic and Google are in close competition at the top of the leaderboard, with 33.3% for GPT-5.4, 33.0% for Claude Opus 4.6, and 32% for Gemini 3.1 Pro Preview
📈 The overall scores on Artificial Analysis today are similar to Mercor’s testing, but some models such as GPT-5.4 nano show improvements in score using our Stirrup test harness
↻ We’ll be updating this leaderboard with key releases for agentic work use as a metric for agent capability on well-defined, long horizon work tasks
APEX-Agents overview:
➤ Tasks span 3 professional domains: investment banking, management consulting, and corporate law
➤ The tasks are designed to require long-horizon work with a large number of tools, which are provided through MCP servers as would be used in many real-world deployments (including calendar, chat, spreadsheet and presentation operations, etc.)
➤ Required outputs include direct message responses (87%) and creating or modifying spreadsheets (6.6%), documents (4.8%), and presentations (1.3%)
➤ Model outputs are parsed and graded against binary rubrics using an LLM judge. Each task is run 3 times and scored pass@1 - a pass requires every rubric test to pass
➤ In our APEX-Agents-AA implementation, 452 tasks run in our open-source Stirrup harness with tool management and usage from @mercor_ai's original MCP implementation. This provides a consistent, reproducible baseline for comparing raw model capability that aligns with realistic agent deployments
Recap from #MiniMax AI Founder Day this weekend (3/21). 💫
Full house in SF with founders, engineers, and AI leaders packed the room. Conversations stayed high-signal all afternoon.
Cofounder keynote → M2.7 demos → a stacked founder panel.
Real builders in the room. Real conversations.
This is the ecosystem we're building.
More to come from MiniMax in 2026! 🦾✨
#IntelligenceWithEveryone
+++
Thanks to everyone who joined us, and to our partners and speakers.
@alexocheema (@exolabs)
@RobRizk1 (@blackboxai)
@tydsh (ex-@Meta FAIR)
@grmcameron (@ArtificialAnlys)
@yaboilyrical (@NousResearch)
@steveshou (@duolingo)
Our open source agent harness, Stirrup, now integrates with Slack! Build custom Slack bot agents directly into your workflows
The latest release of our lightweight, open source agent framework, Stirrup, now comes with Slack integration, featuring:
➤ 📁 Document input/output: The Stirrup Slack agent can read and create documents for you, so you can analyze documents, source images from online, or even generate charts, all without leaving Slack
➤ 👥 Custom subagents: Create specialized subagents with their own instructions, skills, and tools, so the right agent can handle each task (e.g. via '@ Stirrup agent:my-agent’)
➤ 🔄 Flexibility: Stirrup remains lightweight, so you can easily test different models, build custom integrations with external software, or add new functionality to your Slack agent
➤ 🪴 Extensible: Stirrup also natively supports other agent essentials including MCP, skills, browser use, code execution and more
Our v0.1.8 also includes a range of usability improvements to keep Stirrup easy to build with and run.
What should we build next for Stirrup?
Link to repo below
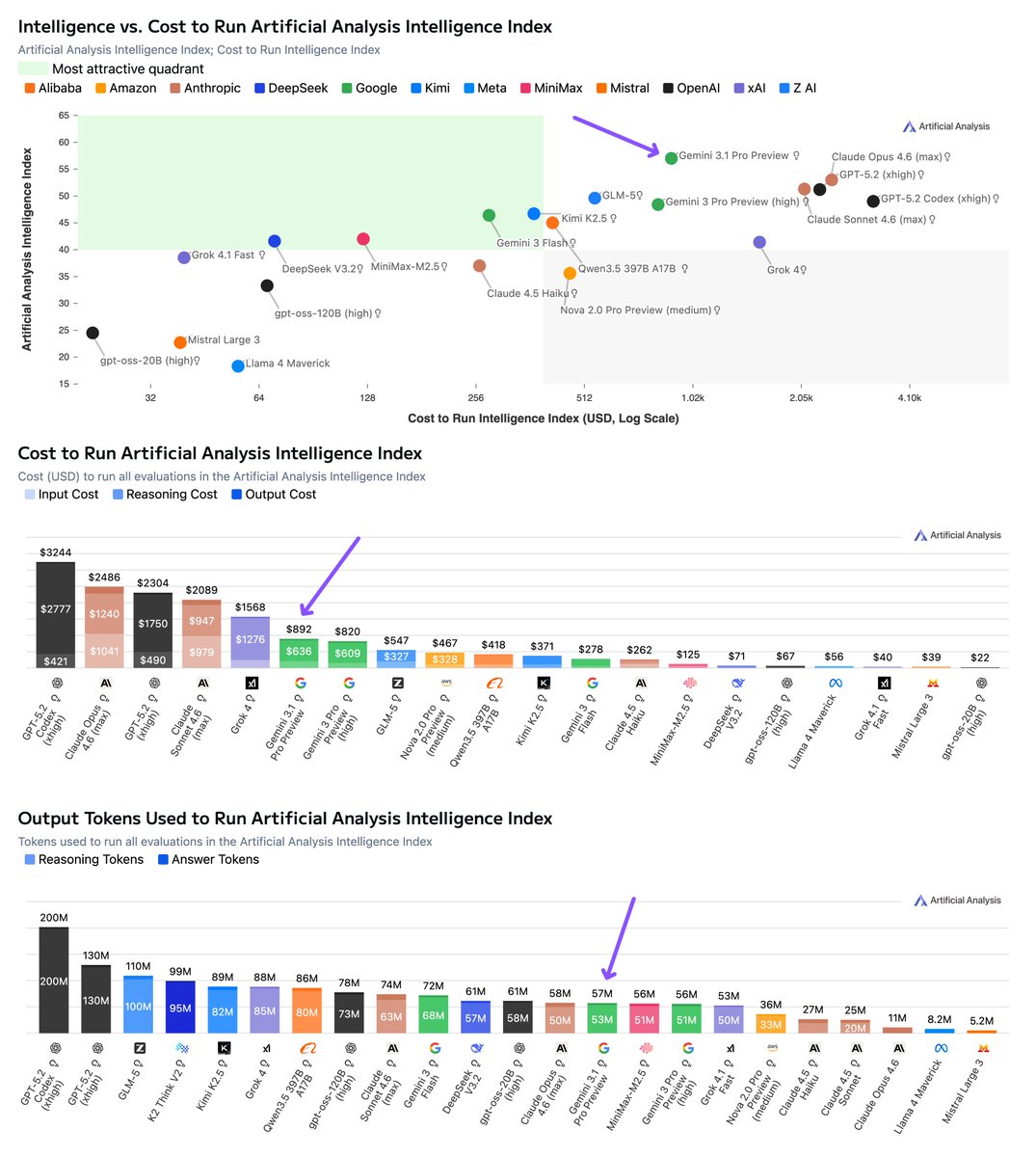
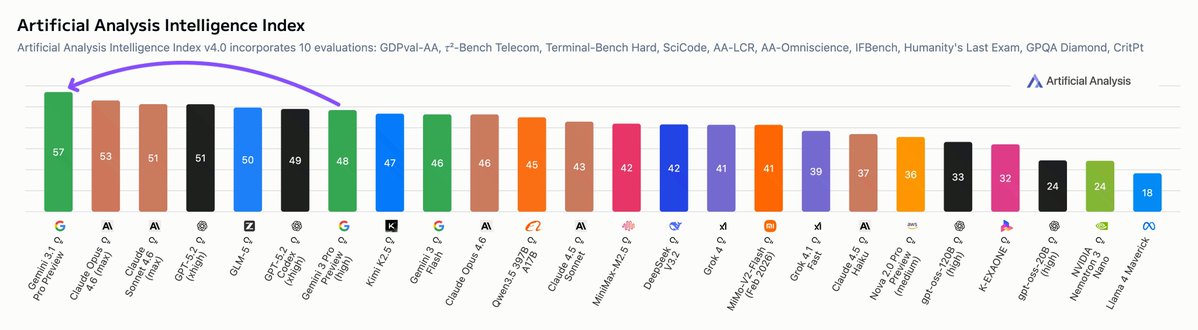
Gemini 3.1 Pro Preview scored highest in the Artificial Analysis Intelligence Index but its most significant advantage might be its price and token efficiency. Our evaluations cost <50% to run on Gemini 3.1 Pro Preview compared to Claude Opus 4.6 (max) and GPT-5.2 (xhigh)
Gemini 3.1 Pro Preview is priced at $2/$12 per 1M input/output tokens while Claude Opus 4.6 is priced at $5/$25 and GPT-5.2 at $1.75/$14.
To complete our Intelligence Index evaluations Gemini 3.1 Pro Preview used fewer tokens (high, 56M) than GPT-5.2 (xhigh, 130M) and Claude Opus 4.6 (max, 58M).
This results in Gemini 3.1 Pro Preview costing $892 to complete our evaluations - less than 50% of the cost of GPT-5.2 (xhigh, $2,304) and Claude Opus 4.6 (max, $2,486).
Google is once again the leader in AI: Gemini 3.1 Pro Preview leads the Artificial Analysis Intelligence Index, 4 points ahead of Claude Opus 4.6 while costing less than half as much to run
@GoogleDeepMind gave us pre-release access to Gemini 3.1 Pro Preview. It leads 6 of the 10 evaluations that make up the Artificial Analysis Intelligence Index and improves significantly over Gemini 3 Pro Preview across capabilities, with the biggest gains in reasoning and knowledge, coding, and hallucination reduction.
Gemini 3.1 Pro Preview also remains relatively token efficient, using ~57M tokens to run the Artificial Analysis Intelligence Index (+1M from Gemini 3 Pro Preview), lower than other frontier models at max reasoning settings such as Opus 4.6 (max) and GPT-5.2 (xhigh). Combined with lower per-token pricing, Gemini 3.1 Pro Preview is cost-efficient among frontier peers, costing less than half as much as Opus 4.6 (max) to run the full Intelligence Index, though still nearly 2x the leading open-weights model, GLM-5.
Key Takeaways:
➤ State-of-the-art intelligence at lower costs: Gemini 3.1 Pro Preview is leading 6 of the 10 evaluations that make up the Artificial Analysis Intelligence Index at less than half the cost to run of frontier peers from @OpenAI and @AnthropicAI. It obtains the highest score in Terminal-Bench Hard (agentic coding), AA-Omniscience (knowledge & hallucination), Humanity’s Last Exam (reasoning & knowledge), GPQA-Diamond (scientific reasoning), SciCode (coding) and CritPt (research-level physics). The CritPt score is particularly notable, scoring 18% on unpublished, research-level physics reasoning problems, over 5 p.p. above the next best model
➤ Improved real-world agentic performance, but not leading: Gemini 3.1 Pro Preview shows an improvement in GDPval-AA, our agentic evaluation focusing on real-world tasks, but is still not the leading model in this area. The model increases its ELO score over 100 points to 1316 (up from Gemini 3 Pro Preview), however still sits behind Claude Sonnet 4.6, Opus 4.6, GPT-5.2 (xhigh), and GLM-5
➤ Leading coding abilities: Gemini 3.1 Pro Preview leads the Artificial Analysis Coding Index, achieving the highest score in both Terminal-Bench Hard (54%) and SciCode (59%)
➤ Reduced hallucinations: Gemini 3.1 Pro Preview shows a major improvement in tendency to guess incorrectly when it doesn’t know the answer, reducing its AA-Omniscience hallucination rate by 38 p.p. from Gemini 3 Pro Preview
➤ Maintained token and cost efficiency: Gemini 3.1 Pro Preview improves without material increases in cost or token usage. It uses only ~2% more tokens to run the Artificial Analysis Intelligence Index than Gemini 3 Pro Preview, and keeps the same pricing ($2/$12 per 1M input/output tokens for ≤200k context). Its cost to run the Artificial Analysis Intelligence Index of $892 is less than half of frontier models such as Opus 4.6 (max) and GPT-5.2 (xhigh), though still ~2x the cost of leading open weights models such as GLM 5 ($547)
➤ Google takes top 3 spots in multi-modality: Gemini 3.1 Pro Preview ranks #1 on MMMU-Pro, our multimodal understanding and reasoning benchmark, ahead of Gemini 3 Pro Preview and Gemini 3 Flash, reinforcing Google’s leadership in multimodal reasoning
➤ Other model details: Gemini 3.1 Pro Preview retains the same 1 million token context window as its predecessor, and includes support for tool calling, structured outputs, and JSON mode
Model intelligence isn’t the only dimension that matters for agents; how quickly they complete tasks is critical. We’ve added end-to-end speed tracking to our open-source agent harness, Stirrup!
The latest version of our lightweight, open source agent framework, Stirrup, now includes:
➤ ⚡End-to-end speed tracking: Measure and compare model speeds under realistic agentic workloads. We measure end-to-end speed as the sum of reasoning and answer tokens divided by the total generation time (from request to response).
➤ 📊 Breakdown by model: When running multiple models in a single agentic workflow (e.g. as subagents), get a breakdown of end-to-end speed for each model
➤ 🔧 Tool call metrics: Measure the time impact of tool calls on your agentic workflows with average tool call duration breakdown in Stirrup’s output summary metrics
What should we build next for Stirrup?
What a great tool from @ArtificialAnlys! Use it to choose the right LLM for the right job. This helps keep your token costs down. I've even used it for my 🦞 Clawdbot (@openclaw ) prompt router when my Prompt Injection Scanner hands off to my Prompt Router once it passes a check.
Claude Opus 4.6 takes the lead in GDPval-AA, surpassing GPT-5.2 in our benchmark of agentic real-world knowledge work tasks
We worked with @AnthropicAI to benchmark Claude Opus 4.6 ahead of launch - it reached an Elo of 1606 with adaptive thinking, nearly 150 points ahead of GPT-5.2 (xhigh). This implies a win rate of ~70% when compared head-to-head with OpenAI’s December 2025 flagship.
Using ~160 million tokens in adaptive thinking mode to complete the 220 tasks in GDPval-AA, Claude Opus 4.6 used 30-60% more tokens than Opus 4.5, but still far fewer than GPT-5.2 (xhigh). This increased token use combined with its high per-token pricing ($5/$25 per million tokens, no change from Opus 4.5) makes Claude Opus 4.6 the most costly model we’ve tested on GDPval-AA so far.
See below for a breakdown of token use, turns and cost, along with example file outputs.
The full set of Artificial Analysis Intelligence Index benchmarks are in progress - we will share a full update on the performance of Opus 4.6 when complete.
GDPval-AA is our primary metric for general agentic performance, measuring the performance of models on knowledge work tasks from preparing presentations and data analysis through to video editing. Models use shell access and web browsing in an agentic loop through Stirrup, our open-source agentic reference harness.
The underlying GDPval dataset was released by @OpenAI in September 2025 to capture self-contained work tasks across 44 occupations in 9 different sectors. It offers insight into the types of tasks models can complete that are relevant to today’s workforce, and is highly realistic due to the OpenAI team’s expert filtering and curation.












![jtatarchuk's tweet photo. 👀 The panels at Beyond [CUDA] are going to 🔥 this year. I'm really looking forward to this one on the Current State of Benchmarking with @dylan522p from @SemiAnalysis_, @TheKanter from @MLPerf, and @grmcameron from @ArtificialAnlys. https://t.co/26TfWhYsWB](https://pbs.twimg.com/media/HEwwyvZaMAA7zZZ.jpg)