Low-frequency electromagnetic fields can degrade collagen, weaken tendons, and cause soft-tissue damage at levels regulators call "safe."
We have a real world case study proving this:
An NFL team whose practice facility sits next to a massive electrical substation.
THREAD 🧵
https://t.co/4AFRlmqgZv
o1 has sparked tons of ideas for applying LLMs to reasoning problems in science and math, but one of the most interesting applications IMO is prompt optimization…
TL;DR: Prompt engineering is a black box even for recent frontier models–slight changes in prompts lead to big differences. Automatic prompt engineering (i.e., using an LLM to optimize a prompt) is one of the best tools for solving this black box, but it requires an LLM with very good reasoning capabilities. The proposal of o1–and its ability to leverage increased inference time compute for better reasoning–unlocks new potential for automatic prompt engineering.
What is automatic prompt optimization? There are several papers that have been published on using LLMs to propose better / improved prompts; e.g., APE [1] and OPRO [2]. I’m referring to these approaches as automatic prompt optimization techniques. The underlying idea here is to use an LLM to refine prompts that are sent to another LLM.
How does this work? Most of papers on automatic prompt optimization follow a similar approach:
1. Construct a “meta prompt” that asks the LLM to write a new prompt based on prior context (i.e., previous prompts and their performance metrics).
2. Generate new prompts with an “optimizer” LLM.
3. Evaluate these prompts using another LLM, producing an objective value / score.
4. Select prompts with the best scores.
5. Repeat steps 1-4 until we can’t find a better prompt.
Notably, the optimizer LLM and the LLM used for evaluation do not need to be the same! We could use o1 as an optimizer that finds better prompts for other LLMs.
Practical details. To make this approach work well, we need to include the correct information in our meta prompt In [2], authors propose including i) a description of the task, ii) few-shot examples from the task iii) prior prompts, iv) the performance of prior prompts, and v) general constraints for the prompt. Given the correct context, we can generate high-performing prompts pretty easily. In fact, APE just generates a single set of ~64 prompts, then scores / filters once to get the best prompt. Even this simple approach surpasses prompts written by humans!
Does this work? Interestingly, LLMs seem to be very good at inferring new / better prompts from prior context. For both APE and OPRO, the automatic prompt engineering system is able to discover new prompts that outperform those written by humans. Plus, the prompts produced by these systems can reveal interesting tricks / takeaways for how to prompt certain models properly. These takeaways even generalize to other tasks in many cases.
How does this relate to o1? The performance of automatic prompt engineering is heavily dependent upon the optimizer LLM’s reasoning capabilities. This LLM must be able to ingest prior prompt information and objective values, then infer new prompts that will perform well. This is a complex reasoning problem. As such, spending more on compute at inference time could potentially lead the LLM to discover more and better patterns for successful prompting.
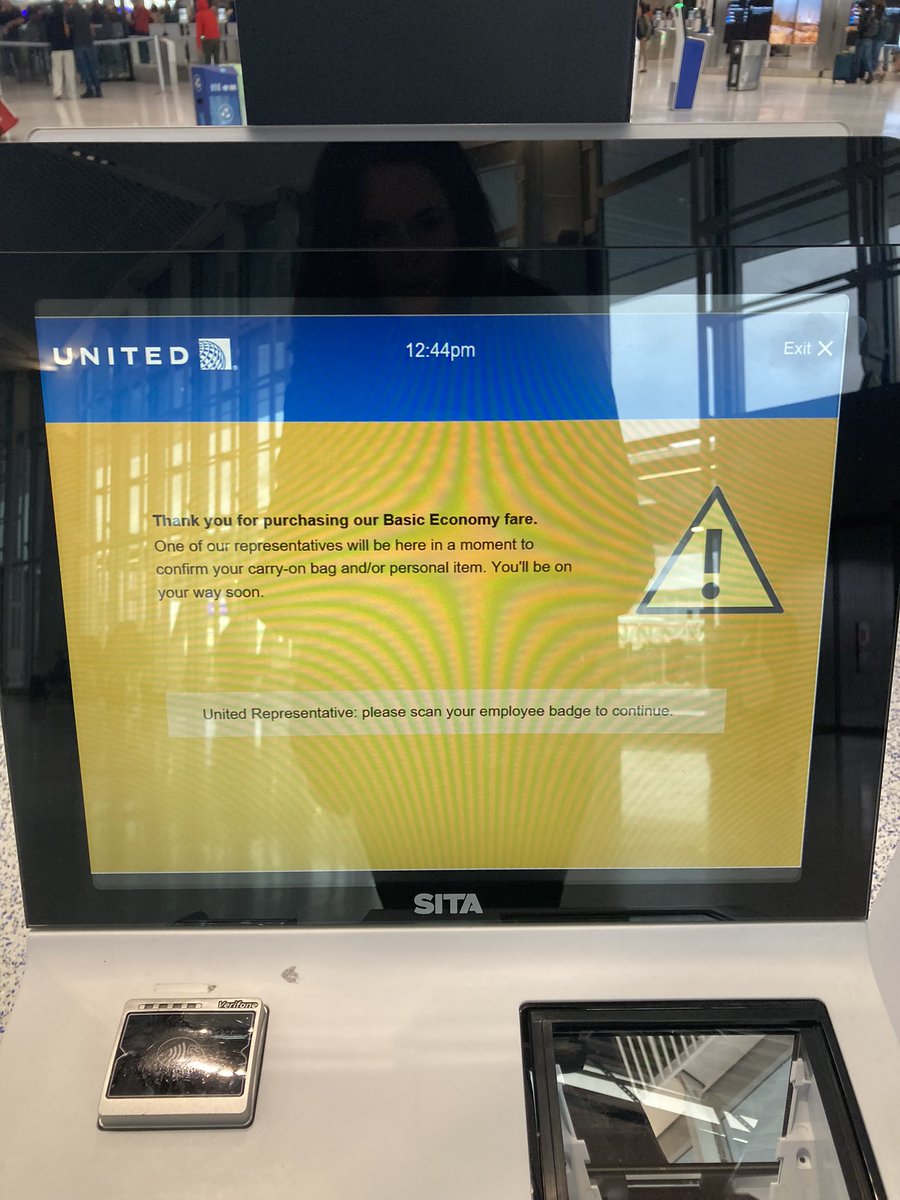
@FrontierCare my first time flying frontier - is this typical? We boarded, waited for take off then had to deplane. 30 min later we boarded again, sat on the tarmac for 30 min and left about 90 min late. Upon arriving at LGA we so far have sat on the tarmac for an hour.
⚡️ Excited to share that I am starting an AI+Education company called Eureka Labs.
The announcement:
---
We are Eureka Labs and we are building a new kind of school that is AI native.
How can we approach an ideal experience for learning something new? For example, in the case of physics one could imagine working through very high quality course materials together with Feynman, who is there to guide you every step of the way. Unfortunately, subject matter experts who are deeply passionate, great at teaching, infinitely patient and fluent in all of the world's languages are also very scarce and cannot personally tutor all 8 billion of us on demand.
However, with recent progress in generative AI, this learning experience feels tractable. The teacher still designs the course materials, but they are supported, leveraged and scaled with an AI Teaching Assistant who is optimized to help guide the students through them. This Teacher + AI symbiosis could run an entire curriculum of courses on a common platform. If we are successful, it will be easy for anyone to learn anything, expanding education in both reach (a large number of people learning something) and extent (any one person learning a large amount of subjects, beyond what may be possible today unassisted).
Our first product will be the world's obviously best AI course, LLM101n. This is an undergraduate-level class that guides the student through training their own AI, very similar to a smaller version of the AI Teaching Assistant itself. The course materials will be available online, but we also plan to run both digital and physical cohorts of people going through it together.
Today, we are heads down building LLM101n, but we look forward to a future where AI is a key technology for increasing human potential. What would you like to learn?
---
@EurekaLabsAI is the culmination of my passion in both AI and education over ~2 decades. My interest in education took me from YouTube tutorials on Rubik's cubes to starting CS231n at Stanford, to my more recent Zero-to-Hero AI series. While my work in AI took me from academic research at Stanford to real-world products at Tesla and AGI research at OpenAI. All of my work combining the two so far has only been part-time, as side quests to my "real job", so I am quite excited to dive in and build something great, professionally and full-time.
It's still early days but I wanted to announce the company so that I can build publicly instead of keeping a secret that isn't. Outbound links with a bit more info in the reply!
been learning a lot about LLMs etc over the past year, organized some of my favorite explainers into a “textbook-shaped” resource guide
wish i’d had this at the start, maybe it can useful to others on a similar journey
https://t.co/54gZimsOnO
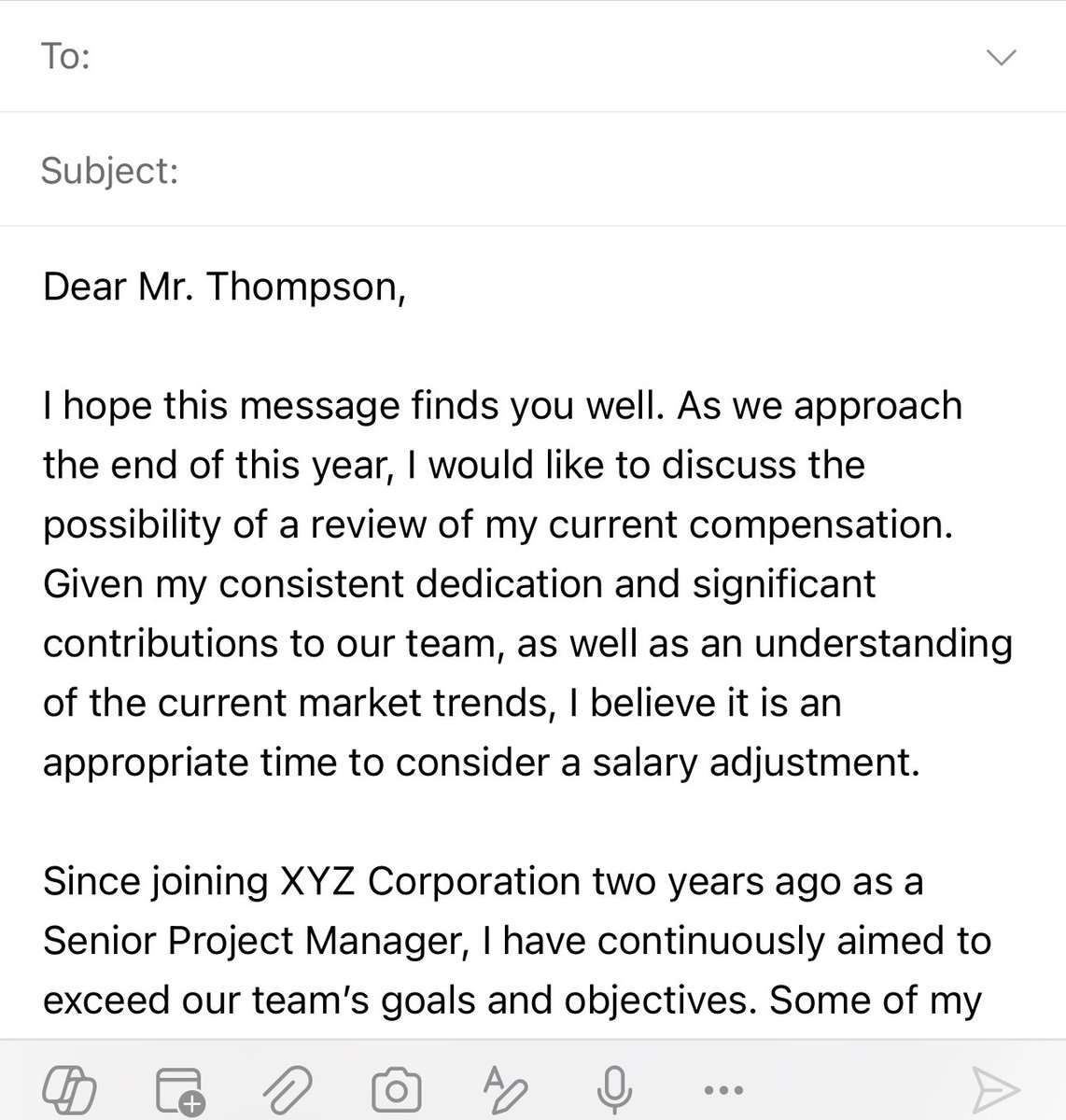
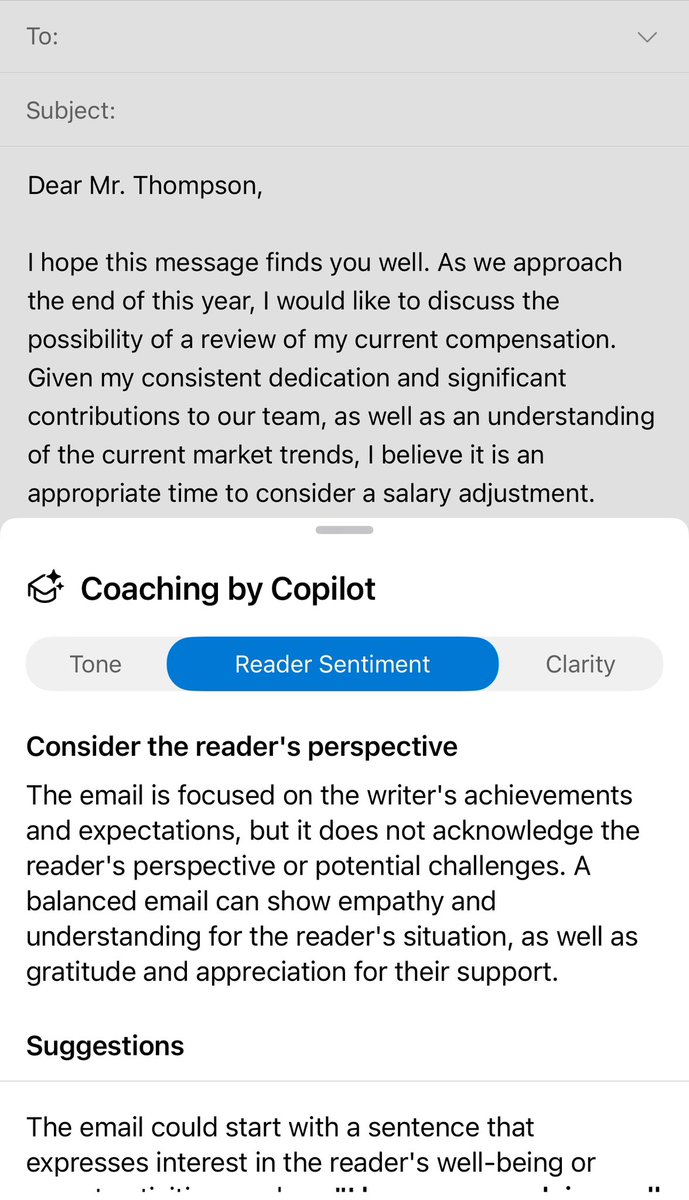
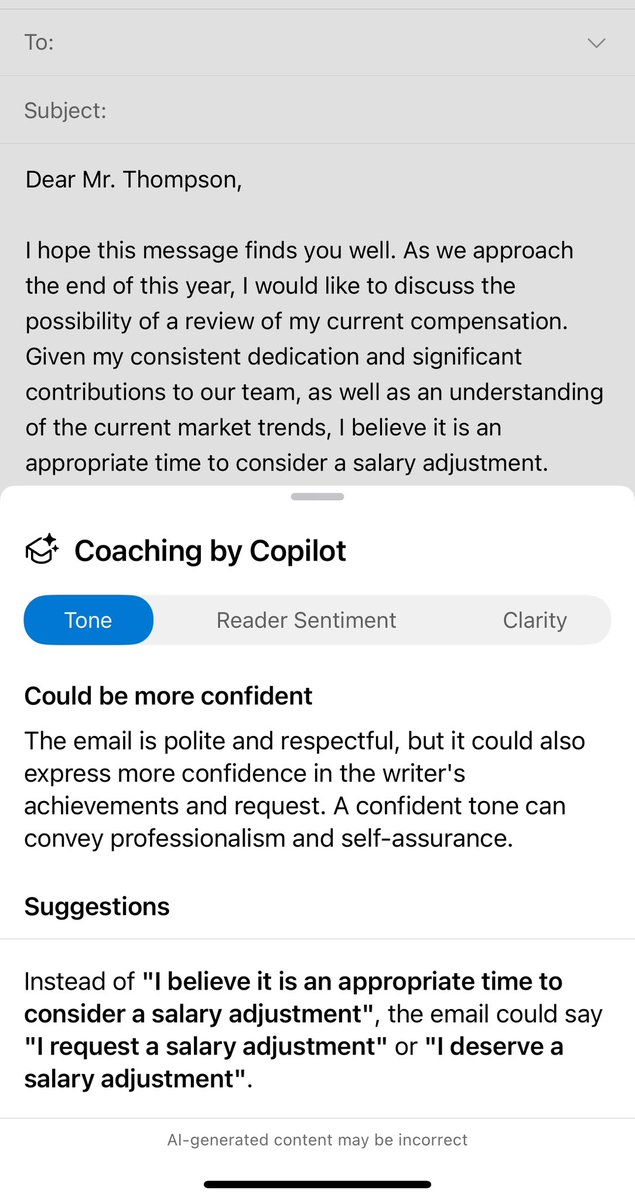
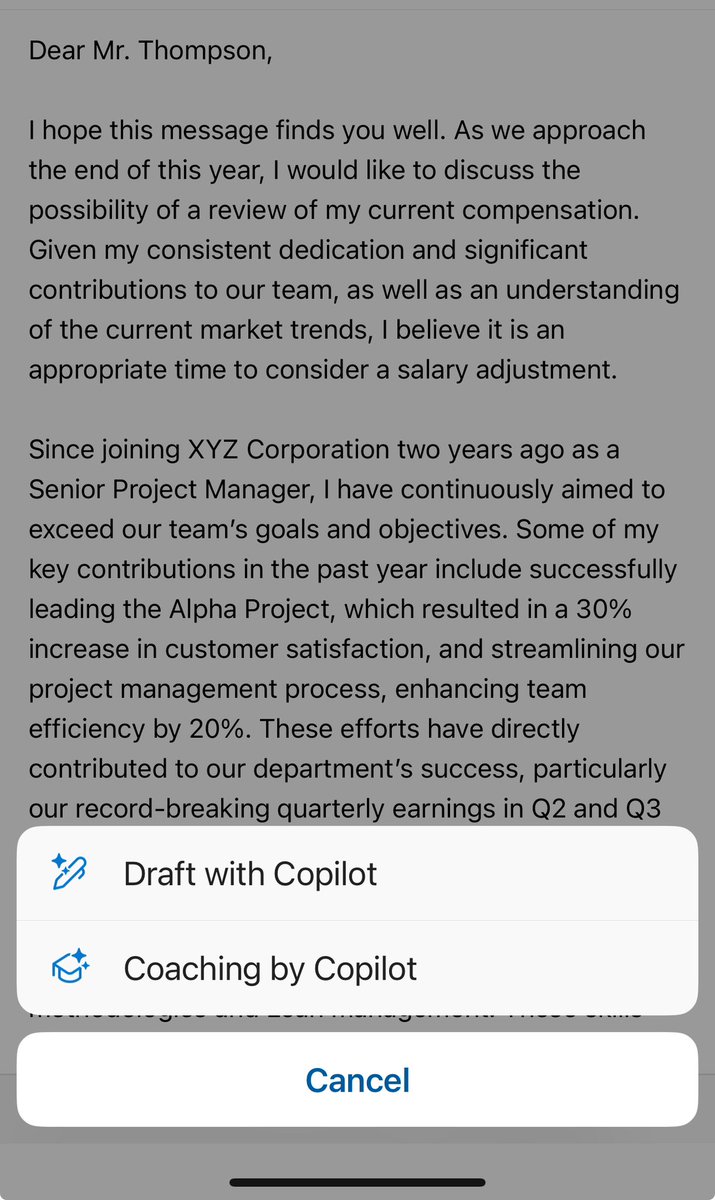
One really interesting choice Microsoft made with Copilot was to include “coaching” as an option.
I am not sure how many people will use it over just having the AI write content, but the advice is pretty solid, and shows an educational/mentoring use of AI to improve performance.
On Friday, I hosted a Space with @JonathanRoss321, the founder and CEO of @GroqInc - a company I invested in that is building custom chips for AI inference.
Jonathan, a former high-school dropout, entered the chip industry while working on ad optimization at Google’s New York office.
Jonathan overheard the speech recognition team complaining that they couldn't get enough compute. These were the early days of AI, and machine learning wasn’t really a thing yet.
So he asked for some budget from Google and started putting together a chip-based machine learning accelerator for them. During the day, Jonathan would work in the normal ads part of the business, and at night, he would work with the accelerator team.
After winning approval from Google, Jonathan and his team built a new chip called the Tensor Processing Unit, and began deploying it across Google’s data centers within a year.
The TPU was a huge success within Google, eventually underpinning more than 50% of all of Google’s compute power. When the other hyper-scalers learned of this success, they tried to hire Jonathan to build custom chips for them too.
During this process, it became increasingly clear to Jonathan that a gap would emerge between companies that had access to next-gen compute and companies that didn’t. So he founded Groq and set out to build a chip that would be available to everyone.
I led Groq’s founding investment in 2016, and since then, Jonathan and his team have developed several types of AI hardware including the Language Processing Unit (LPU), a new type of silicon that is hyper-efficient at running inference for LLMs.
In our conversation on Friday, we discussed the founding story of Groq, what you need for great AI hardware, large language models, and some of the implications for the key players in AI.
It’s one of the most interesting conversations I’ve had on AI with a lot of learnings.
You can listen to our conversation below:
@eightsleep
My device won’t connect to wifi. I’ve tried several attempts at troubleshooting including a factory reset and moving the device very close to wifi router. Nothing works. Customer service just told me refunds are only issued within the first month, it’s been 6.
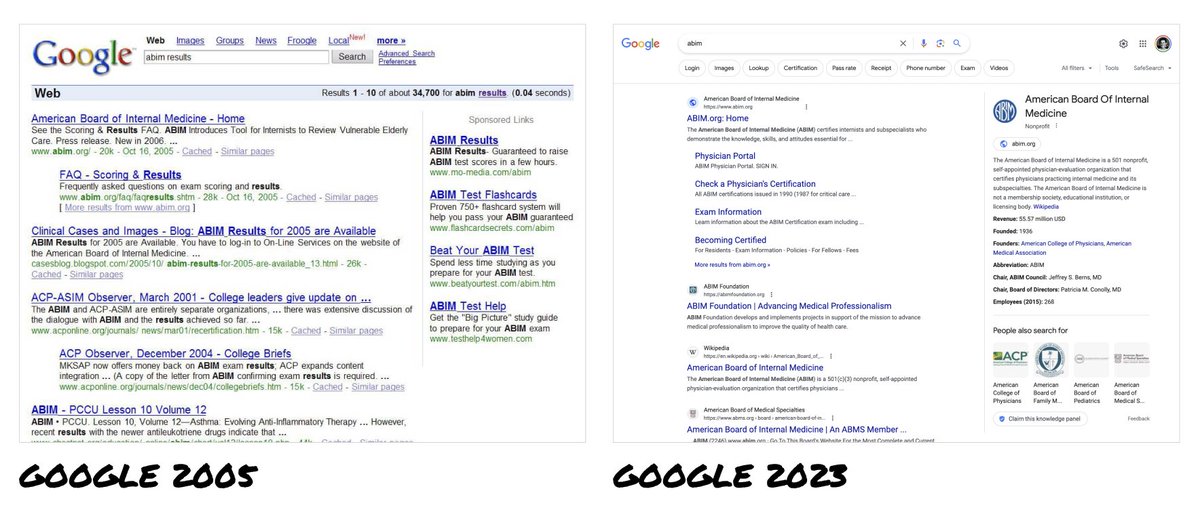
In 2006, I was 1 of 4 designers on Google Search.
For 20 years, every search engine has copied Google.
Now ChatGPT, Bard + Claude look like Google's offspring - "better” search engines.
But last week signaled we're on the brink of a design revolution.
ChatGPT unveiled incredible new features.
These could give us the opportunity to completely shift how we interface with AI.
Here's the full story:
–––
When I was a designer on Google Search, all major search engines looked the same – Google, Yahoo, MSN Bing.
Google was the market leader with a heavily optimized UI that supported billions of dollars in ad revenue.
Naturally, it became THE way to show search results.
Its success made it illogical for Google to consider big UI changes.
And any changes they did make were just mirrored by everyone else.
So 20 years later, we’ve only seen incremental changes to search engine UIs.
–––
Today, we have consumer-ready LLMs (Large Language Models) freshly in our hands.
As consumer products, these are in their infancy.
We’re very early in understanding their capabilities and defining how people interact with them.
These are uncharted waters.
And yet ChatGPT, Bard, Claude etc. all chose a text-based input box — just like Google’s search box — as the core interface.
Why?
The input box is simple, versatile, and familiar.
- It’s simple to understand → you type your questions into the box.
- It’s versatile → the box can handle all sorts of questions/queries.
- The paradigm is super familiar → people immediately know how to use it.
Because of this, LLMs have essentially become “a better Google.”
–––
But last week’s ChatGPT announcements thrust open the doors to new possibilities.
ChatGPT is now multi-modal — it can see, hear, and speak.
These are the recent announcements from @OpenAI :
Voice: https://t.co/hAeXxBTH9l
Photos: https://t.co/X3QbLnwT1V
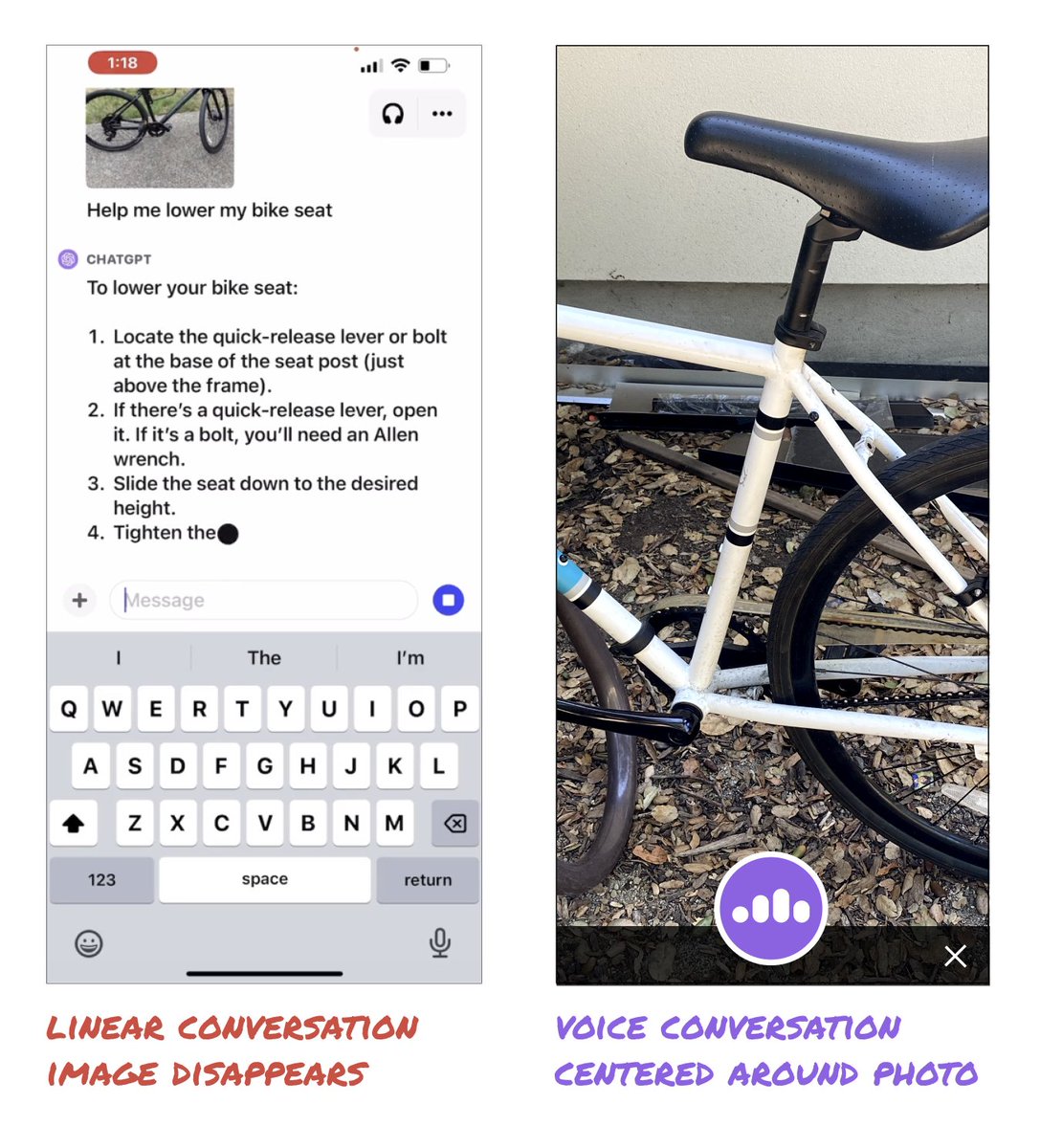
The example of ChatGPT explaining how to lower a bike seat was incredible.
But, it could be so much better!
The video showed you'll have to post multiple new photos to keep adding new information and to progress the conversation.
It was still a linear conversation centered around the text box.
But what if we rethought the interface to center around the image?
What if ChatGPT supported both images AND voice simultaneously?
Could we end up with a more immersive experience?
–––
How else could interacting with LLMs mimic IRL conversations?
Could we (or the AI) pinch to zoom or rotate the image?
Could we interact in real time with video?
What new possibilities open up with context being preserved over time?
–––
There is so much energy and excitement around what AI can do.
But we are limiting the potential by assuming the conversation box is the best interface.
Right now, designers have the chance to create truly novel interactions and bust through the 20+ year old search UI paradigm.
The ideas above are just to illustrate some potential options.
But they are also intended to spark a flame.
Now is the opportunity to be creative and explore divergent UIs.
What are the craziest, coolest, most creative UI ideas we can unleash?
LFG 🚀

























![cwolferesearch's tweet photo. o1 has sparked tons of ideas for applying LLMs to reasoning problems in science and math, but one of the most interesting applications IMO is prompt optimization…
TL;DR: Prompt engineering is a black box even for recent frontier models–slight changes in prompts lead to big differences. Automatic prompt engineering (i.e., using an LLM to optimize a prompt) is one of the best tools for solving this black box, but it requires an LLM with very good reasoning capabilities. The proposal of o1–and its ability to leverage increased inference time compute for better reasoning–unlocks new potential for automatic prompt engineering.
What is automatic prompt optimization? There are several papers that have been published on using LLMs to propose better / improved prompts; e.g., APE [1] and OPRO [2]. I’m referring to these approaches as automatic prompt optimization techniques. The underlying idea here is to use an LLM to refine prompts that are sent to another LLM.
How does this work? Most of papers on automatic prompt optimization follow a similar approach:
1. Construct a “meta prompt” that asks the LLM to write a new prompt based on prior context (i.e., previous prompts and their performance metrics).
2. Generate new prompts with an “optimizer” LLM.
3. Evaluate these prompts using another LLM, producing an objective value / score.
4. Select prompts with the best scores.
5. Repeat steps 1-4 until we can’t find a better prompt.
Notably, the optimizer LLM and the LLM used for evaluation do not need to be the same! We could use o1 as an optimizer that finds better prompts for other LLMs.
Practical details. To make this approach work well, we need to include the correct information in our meta prompt In [2], authors propose including i) a description of the task, ii) few-shot examples from the task iii) prior prompts, iv) the performance of prior prompts, and v) general constraints for the prompt. Given the correct context, we can generate high-performing prompts pretty easily. In fact, APE just generates a single set of ~64 prompts, then scores / filters once to get the best prompt. Even this simple approach surpasses prompts written by humans!
Does this work? Interestingly, LLMs seem to be very good at inferring new / better prompts from prior context. For both APE and OPRO, the automatic prompt engineering system is able to discover new prompts that outperform those written by humans. Plus, the prompts produced by these systems can reveal interesting tricks / takeaways for how to prompt certain models properly. These takeaways even generalize to other tasks in many cases.
How does this relate to o1? The performance of automatic prompt engineering is heavily dependent upon the optimizer LLM’s reasoning capabilities. This LLM must be able to ingest prior prompt information and objective values, then infer new prompts that will perform well. This is a complex reasoning problem. As such, spending more on compute at inference time could potentially lead the LLM to discover more and better patterns for successful prompting.](https://pbs.twimg.com/media/GY6G95xWsAAmyIH.jpg)