A few months ago, while working on a project that required an open-source model for mathematical reasoning, we came across DeepSeek's project. At the time, we even considered building something on top of it, though unfortunately, my proposal didn’t get funded 😂.
If DeepSeek can push AI forward in areas like logical reasoning and mathematical derivation, the demand for compute power won’t decrease—it’ll skyrocket due to the long-tail effect. As AI applications become more widespread, compute needs will expand to everyday tasks.
AWS just released a new Multi-Agent AI framework
It lets you manage multiple AI agents, dynamically route LLM queries, maintain context across AI Agents and can be deployed locally on your computer.
100% opensource.
NeurIPS acknowledges that the cultural generalization made by the keynote speaker today reinforces implicit biases by making generalisations about Chinese scholars. This is not what NeurIPS stands for. NeurIPS is dedicated to being a safe space for all of us. We want to address the comment made during the invited talk this afternoon, as it is something that NeurIPS does not condone and it doesn't align with our code of conduct. We are addressing this issue with the speaker directly.
NeurIPS is dedicated to being a diverse and inclusive place where everyone is treated equally.
📢Postdoc Position📢
Dr. Xia Hu @huxia and I are looking for a Chairman's Postdoctoral Fellow in Efficient and Trustworthy LLMs @RiceCompSci
If you are interested, please do not hesitate to apply: https://t.co/6ZHafl4SNL
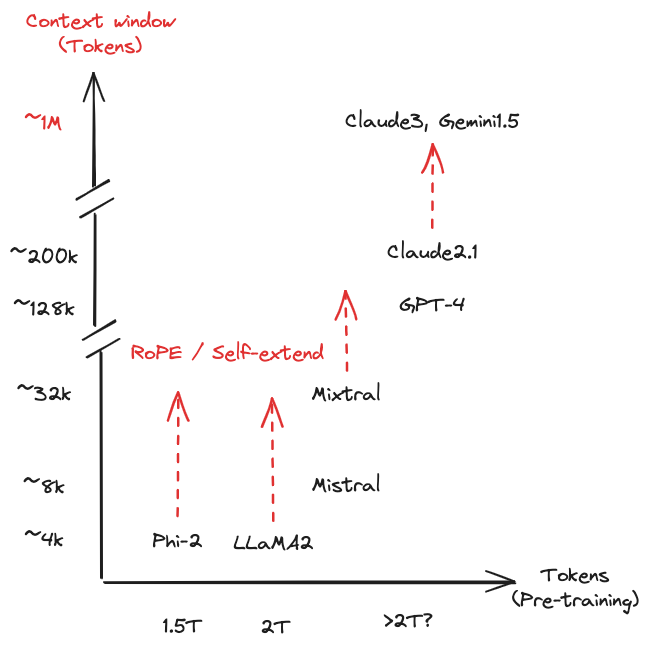
Thanks @LangChain for mentioning our work Self-extend. Here are my (biased) thoughts: 1) Long-context and RAG complement each other for now, at least till the long-context capability of models could become similar to short contexts.
RAG for long context LLMs: Video
Will long context LLMs really kill RAG? This is a talk @RLanceMartin gave at a few recent meetups that pulls together threads from a few different projects related to this question.
Multi-needle in a haystack shows limitations in long-context LLM reasoning & retrieval over multiple facts.
But, RAG may evolve in a few ways. While query analysis likely remains critical, we may see a shift towards full document indexing (e.g., RAPTOR, multi-representation indexing) & long context embeddings.
We also may see a shift away from a naive prompt : response paradigm to a "flow" paradigm where RAG answer are built iteratively (Self-RAG, C-RAG) with post-retrieval reasoning and feedback.
📽️ Video:
https://t.co/hCCV9eHcMY
📓 Slides:
https://t.co/KQVr99ZlbX
⛓️ Links:
1/ Multi-needle analysis w/ @GregKamradt
https://t.co/iaIB3AZfmq
2/ RAPTOR (@parthsarthi03 et al)
https://t.co/WJfiqvOKQE
https://t.co/Lx2mLCSBkv
3/ Dense-X / multi-representation indexing (@tomchen0 et al)
https://t.co/gmik0jhDI5
https://t.co/U5tymTXdYY
4/ Long context embeddings (@JonSaadFalcon, @realDanFu, @simran_s_arora)
https://t.co/yOftIifmBQ
https://t.co/CLr39dHN56
5/ Self-RAG (@AkariAsai et al), C-RAG (Shi-Qi Yan et al)
https://t.co/2oxTQOtViK
https://t.co/jWAa2Oxw8k
https://t.co/Gai8mxe81x
2) How to handle long contexts is challenging - The way how commercial models are handling this is unclear and they chose not to open it, also the community conjectures that they didn't deal with the problem in an elegant way that may cause other problems (no experiments).
Without fine-tuning, Self-Extend has significantly improved performance of the Gemma-2b-it performance in the needle in the haystack task, increasing its capability from less than 8k (pretraining window) to over 90k!!
https://t.co/1LzNIaWh3E
Despite the mixed feelings about Google's latest Gemma model, we're big fans! @GoogleAI Why? Coz we found it pairs incredibly well with our SelfExtend 🤣🤣🤣 - like, perfectly! With Self-Extend, no fine-tuning needed, we effortlessly expanded Gemma's window from 8k to 90k+! On the 'Needle in the haystack' task, Gemma-2b-it even struggled at 8k, but with SelfExtend, Gemma-2b-it easily tackles it within 90k range! #AI #Gemma #SelfExtend #LLMs 🚀
Paper: https://t.co/9lwtnrDpOL
Github: https://t.co/FmGkJpdpQn
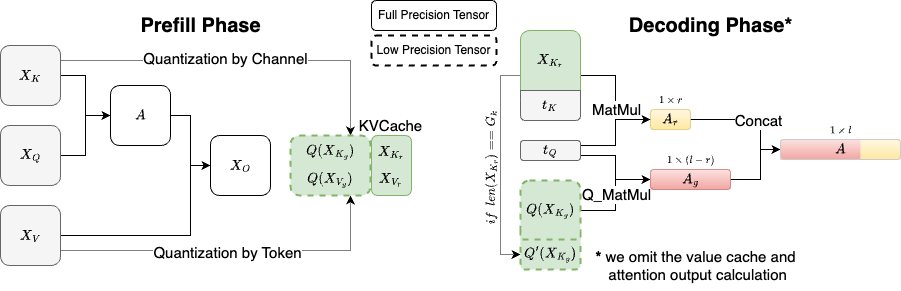
Excited to introduce KIVI🥝, the first 2bit KV cache quantization breakthrough! 🚀 KIVI can be directly integrated into existing LLMs without any tuning.
📄 Paper: https://t.co/UgC9L7KSm1
💻 Code: https://t.co/fQBAGrtaIC
#KIVI#LLM#AI#MachineLearning
Welcome more people to trying Self-Extend/LongLM on more diverse tasks and models to see when it works and identify its limitations. Here is our implementation https://t.co/N6SARaEJr4 . Credits to @serendip410 !