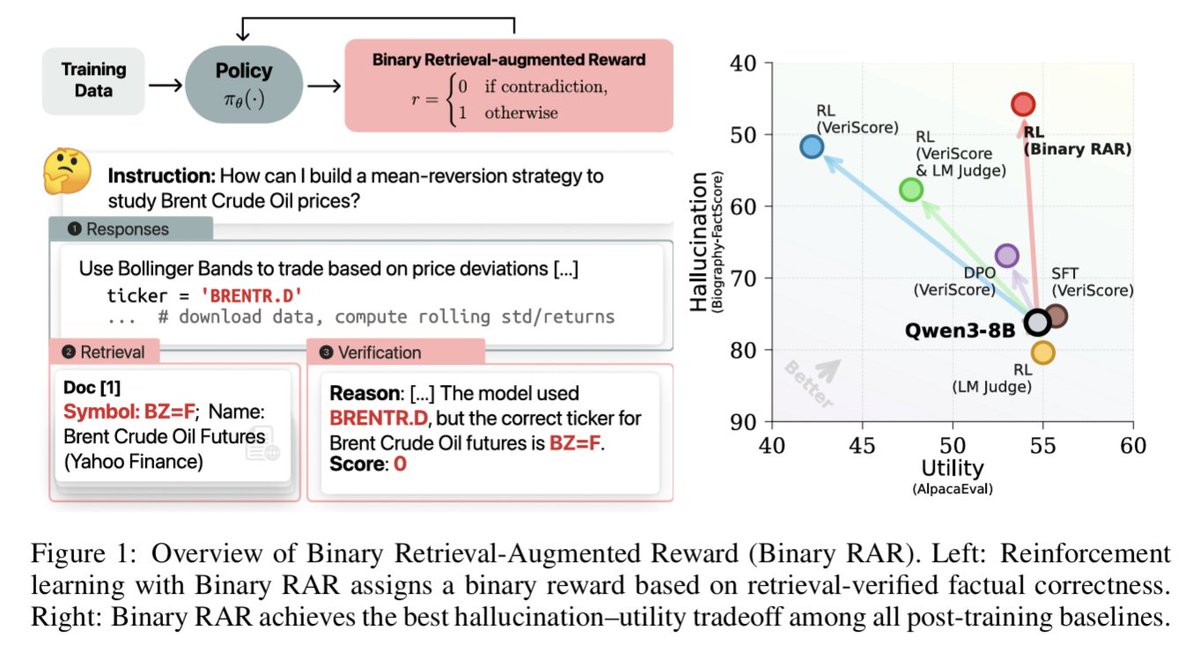
OpenAI's blog (https://t.co/VeNI85798G) points out that today’s language models hallucinate because training and evaluation reward guessing instead of admitting uncertainty. This raises a natural question: can we reduce hallucination without hurting utility?🤔
On-policy RL with our Binary Retrieval-Augmented Reward (RAR) can improve factuality (40% reduction in hallucination) while preserving model utility (win rate and accuracy) of fully trained, capable LMs like Qwen3-8B.
[1/n]
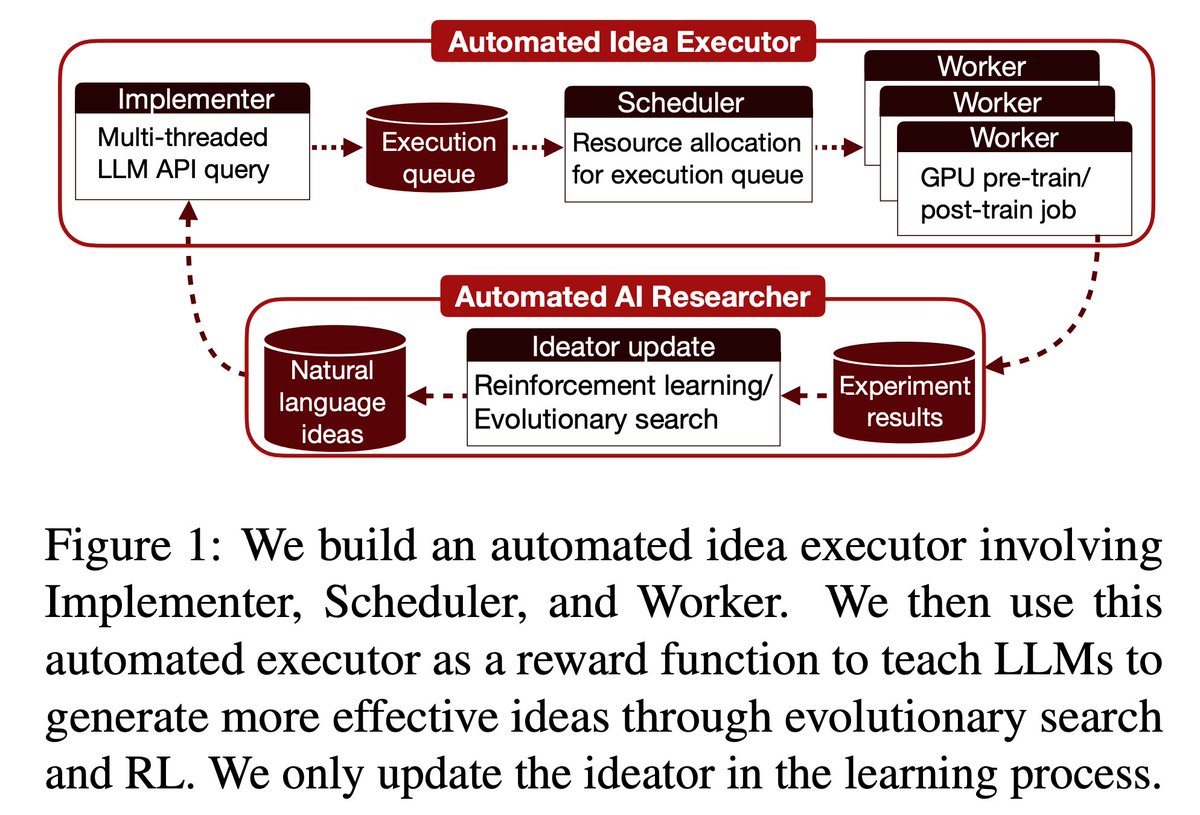
Claim: Autoresearch that moves the frontier will be about better data: we call that *Autodata*.
🧵1/6 -- Paper is out! https://t.co/b8gOALndzy
Key idea: agentic data creation provides a way to *convert increased inference compute into higher quality model training*.
We show our method gives gains on computer science, legal and math problems over classical synthetic dataset creation methods.
We also show how to train (meta-optimize) such a data scientist agent, so that it can create even stronger data.
Overall, we believe this direction has the potential to change how we build AI data!
Trained some terminal agents with friends!
Introducing Tmax, open RL terminal agent models. Under default settings and shorter length (65k) token budgets, tmax outperforms prior open work on terminal use. We are releasing all data+weights+rollouts publically!
Continuous reward models can measure partial progress on a task, unlike binary rewards (e.g. RLVR). But we find they inevitably assign wildly different scores to equally-good responses, which can lead to bad policies. Surprisingly, dense rewards are often better if discretized!🧵
I'm joining OpenAI next week!🥹 The job search turned out to be really challenging but also super rewarding, so I wrote a small blog to share what I learned along the way and hopefully make the process a little less mysterious for the next person. https://t.co/6FigSBdenD
Excited to share these preliminary results on our internal autoresearch system @Recursive_SI, where we achieve SOTA on nanochat / nanogpt speedrun / kernel benchmarks using the same underlying system without task-specific adaptations.
blog: https://t.co/INySSnZ8KN
Automatic research from mathematics to AI research:
We transfer the ScaleAutoResearch pipeline, which improves a 32-year-old Ramsey number bound, to the NanoGPT Speedrun optimizer track, using Claude Code and Codex with only 1–2 A40 nodes. We run ~300 experiments in ~5k A40 hours, and then:
⭕ Results: improve (non-interpolation) SOTA from 2875 to 2755 steps.
Changes:
+: non-gain aux β₂ = 0.997; SOAP for all hidden with freq=1; LR-horizon + momentum tuning
-: remove Circuit-/Contra-/Soft-Muon, Aurora, NorMuon 2nd-moment, V-SOAP-blend, attn denom-floor...
Clearly, the experiments are compute-bounded, and it is possible that more results could come with more resources!
[1/n]
MAI-Thinking-1 is out!
Excited to share what we are building and how climbing from scratch (no distillation) actually works: simple recipes, rigorous science, self-distillation, patience, and great infra.
Check out our tech report has the full story of our RL climbs.
https://t.co/aLW40sWz4d
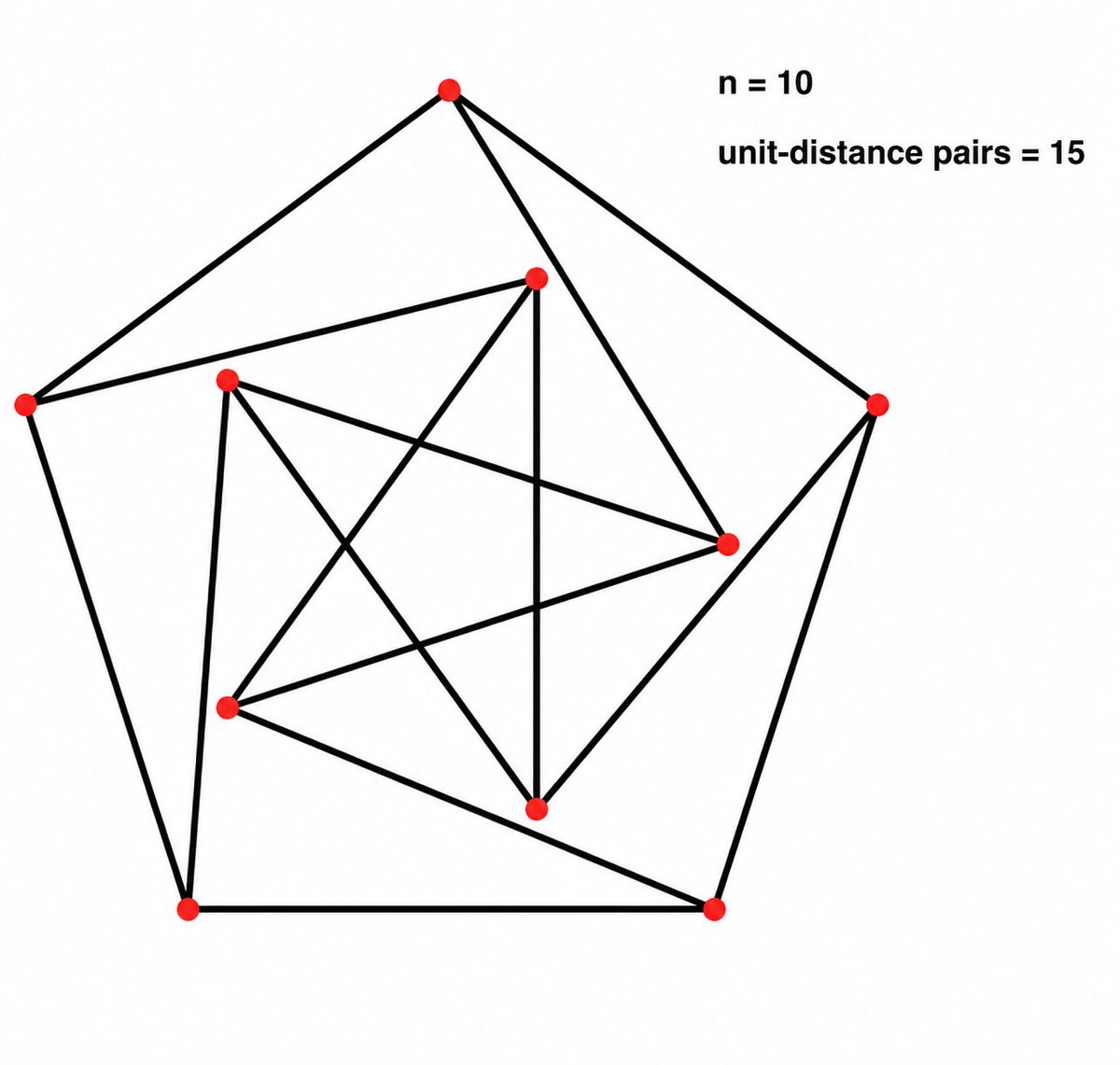
🧵(1/8) An @OpenAI internal reasoning LLM achieved an AI Math milestone: solving an open problem central to its mathematical subfield— in this case, the unit distance problem of discrete geometry.
We came across it in a side quest to truly push our model on the hardest problems.
LMs can learn from human labels, training data, and stronger teachers. But what happens when all of these run out when the model is already at the frontier and there is no stronger external source to learn from❓
In EvoLM, we extract the model's own evaluative knowledge into rubrics, and use them to improve its own generation🔁
This enables self-improvement with no external signals‼️
2 papers accepted to ICML as Spotlights (top 2.2%)🥳
- DR Tulu: RL w/ evolving rubrics for SOTA long-form deep research
https://t.co/8zvcfCC7cg
- Binary RAR: RL w/ binary rewards for the hallucination–capability trade-off
https://t.co/BmF6fJZ9Fv
Congrats to all collaborators!
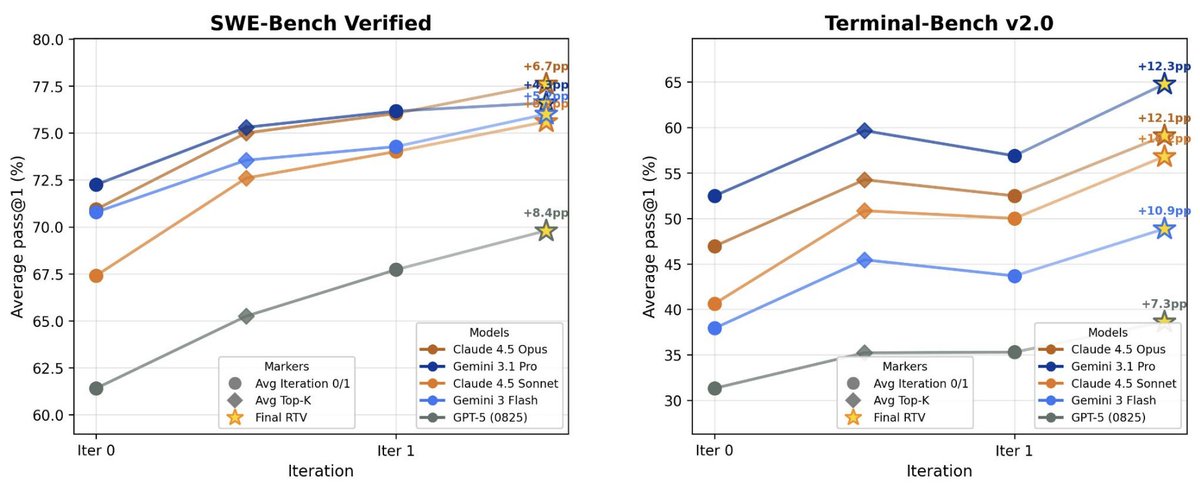
New work @AIatMeta: We enable test-time scaling for long-horizon coding agents by using better representations, selection and reuse of agentic trajectories, with Claude 4.5 Opus improving by +6.7% on SWE-Bench Verified and +12.1% on Terminal-Bench 2.0.
📄: https://t.co/tvhdw0DuYd
🚀 New work: Meta-Reinforcement Learning with Self-Reflection
LLM agents shouldn't just solve problems. They should learn from their own attempts. Most current RL methods optimize single independent trajectories.
Each attempt starts from scratch, with no mechanism to improve across attempts. But intelligent systems should get better after trying once.
This raises a fundamental question: How do we train models to learn from their own attempts?
We believe Meta-Reinforcement Learning may be a key paradigm for training future LLM agents, enabling models to adapt and improve across attempts and environments.
In this work we introduce MR-Search, a training paradigm built around:
🧠 In-Context Meta-Reinforcement Learning
🪞 Self-Reflection
🔁 Learning to learn at test time
📄 Paper: https://t.co/idEBvKavEA
💻 Code: https://t.co/m5b9HXgjM6
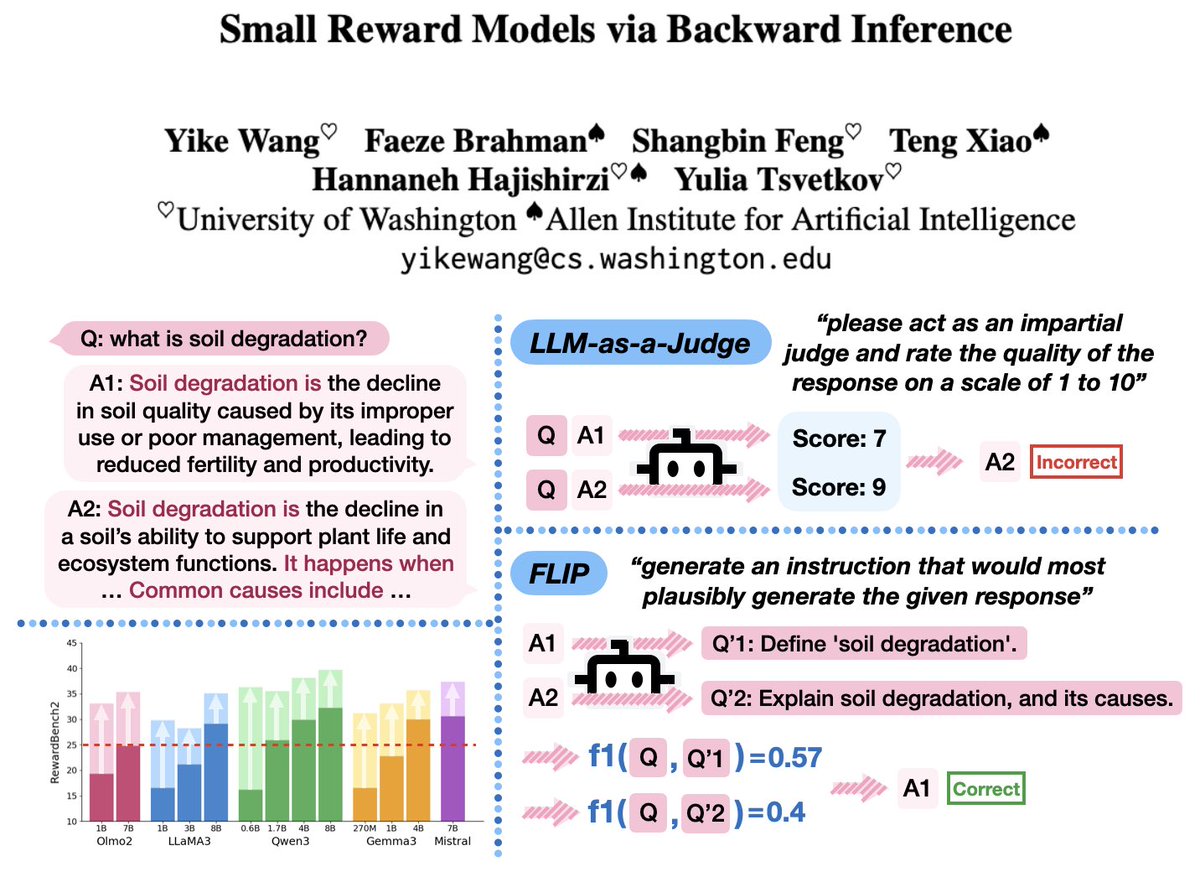
Small language models are not very helpful as judges, how about 🔄 backward inference—inferring the instruction given only the response, and using the similarity between the inferred and the original instructions as the reward signal?
Introducing ⚙️FLIP, a reference-free and rubric-free reward modeling approach that boosts the RewardBench2 performance of 13 small language models by an average of 79.6%, and substantially outperforms LLM-as-a-Judge under test-time scaling via parallel sampling and GRPO training.
📄paper: https://t.co/X1G5nrN2mx
🔗code: https://t.co/ArM5wPqYYy
For decades, we’ve trained AI to chase rewards. But humans don’t just optimize outcomes. We experience, reflect, then learn.
Can AI do the same?
Introducing 𝐄𝐱𝐩𝐞𝐫𝐢𝐞𝐧𝐭𝐢𝐚𝐥 𝐑𝐞𝐢𝐧𝐟𝐨𝐫𝐜𝐞𝐦𝐞𝐧𝐭 𝐋𝐞𝐚𝐫𝐧𝐢𝐧𝐠, a step toward AI that truly learn from experience.
Thrilled to share: OpenScholar - our work on scientific deep research agents for reliable literature synthesis -has been accepted to Nature! 🎉 Huge thanks to collaborators across institutions who made this possible!
Calling on behalf of infini-gram: does anyone know where I can get / apply for AWS credits? 💸💸
Keeping infini-gram alive costs quite some money, mostly SSD rental. If you're a fan of keeping open LLM training data readily inspectable, please reply / DM me some pointers!
🧵1/4
Can LLMs automate frontier LLM research, like pre-training and post-training?
In our new paper, LLMs found post-training methods that beat GRPO (69.4% vs 48.0%), and pre-training recipes faster than nanoGPT (19.7 minutes vs 35.9 minutes).
1/






![ypwang61's tweet photo. Automatic research from mathematics to AI research:
We transfer the ScaleAutoResearch pipeline, which improves a 32-year-old Ramsey number bound, to the NanoGPT Speedrun optimizer track, using Claude Code and Codex with only 1–2 A40 nodes. We run ~300 experiments in ~5k A40 hours, and then:
⭕ Results: improve (non-interpolation) SOTA from 2875 to 2755 steps.
Changes:
+: non-gain aux β₂ = 0.997; SOAP for all hidden with freq=1; LR-horizon + momentum tuning
-: remove Circuit-/Contra-/Soft-Muon, Aurora, NorMuon 2nd-moment, V-SOAP-blend, attn denom-floor...
Clearly, the experiments are compute-bounded, and it is possible that more results could come with more resources!
[1/n]](https://pbs.twimg.com/media/HKZhssDbIAAR0kQ.jpg)























![tomchen0's tweet photo. OpenAI's blog (https://t.co/VeNI85798G) points out that today’s language models hallucinate because training and evaluation reward guessing instead of admitting uncertainty. This raises a natural question: can we reduce hallucination without hurting utility?🤔
On-policy RL with our Binary Retrieval-Augmented Reward (RAR) can improve factuality (40% reduction in hallucination) while preserving model utility (win rate and accuracy) of fully trained, capable LMs like Qwen3-8B.
[1/n]](https://pbs.twimg.com/media/G5qRmg-acAQF4U6.jpg)






![ypwang61's tweet photo. Automatic research from mathematics to AI research:
We transfer the ScaleAutoResearch pipeline, which improves a 32-year-old Ramsey number bound, to the NanoGPT Speedrun optimizer track, using Claude Code and Codex with only 1–2 A40 nodes. We run ~300 experiments in ~5k A40 hours, and then:
⭕ Results: improve (non-interpolation) SOTA from 2875 to 2755 steps.
Changes:
+: non-gain aux β₂ = 0.997; SOAP for all hidden with freq=1; LR-horizon + momentum tuning
-: remove Circuit-/Contra-/Soft-Muon, Aurora, NorMuon 2nd-moment, V-SOAP-blend, attn denom-floor...
Clearly, the experiments are compute-bounded, and it is possible that more results could come with more resources!
[1/n]](https://pbs.twimg.com/media/HKZhssjbEAEy9mK.jpg)