It was an honor to give the keynote at MLSys
Covered how AI systems have evolved, why AI is needed to improve them, why results have disappointed, why the future looks amazing, and why I’m working on this at Core Auto
Recording should be out soon, in the meantime slides
➡️ More experiments, details, and visualizations can be found in our paper!
Work co-led with @quentinlldc. Huge thanks to our collaborators Damien Scieur, @ylecun, and @randall_balestr for their help, guidance, and support! 🙏
Paper: https://t.co/6AUEe8xPHF
New video, starting to look at Diffusion Language Models. This one introduces some ideas, then shows how I turn ModernBERT into a LLaDA-style generative model. Lots of avenues to explore from here! Join me in playing with this? Project ideas in thread :)
https://t.co/OgzgwHEa2t
I love Cutlass, and this new Python DSL looks very well-designed. Will for sure accelerate kernel dev + exploring new ideas in ML + GPU. I'm already playing with it and having fun
We’re also releasing the SkyAgent-v0 models which achieve promising results on SWE-Bench-Verified across model lines.
Check it out!
Blog: https://t.co/y2uwd8MF7P
Model Collection: https://t.co/IrtiSNYiQX
Github: https://t.co/CDXGHvAnS4
3/N
A deep conversation with @SavinovNikolay, the Gemini long context pre-training co-lead…
We go from the basics to what is needed to scale to infinite context to long context best practices for devs:
Thrilled to share our new paper: MetaQueries! We've created novel approach that bridges MM-LLMs and diffusion models using learnable queries . The method enables knowledge augmented image generation while preserving SOTA understanding capabilities.
We find training unified multimodal understanding and generation models is so easy, you do not need to tune MLLMs at all.
MLLM's knowledge/reasoning/in-context learning can be transferred from multimodal understanding (text output) to generation (pixel output) even it is FROZEN!
Llama4 models are out! Open sourced! Check them out:
“Native multimodality, mixture-of-experts models, super long context windows, step changes in performance, and unparalleled efficiency. All in easy-to-deploy sizes custom fit for how you want to use it” https://t.co/sxlAKuymkR
We are bringing back Stanford’s CS 25 Transformers Course (https://t.co/Yvq4AcLiBV) today! It’s open to everybody!
This is one of @Stanford's hottest seminar courses. We open the course through Zoom to the public. Lectures start today (Tuesdays), 3-4:20pm PDT, at https://t.co/hhHwpf9L7h. Talks will be recorded and released ~2 weeks afterward.
Each week, we invite folks at the forefront of Transformers research to discuss the latest breakthroughs, from LLM architectures like GPT and Gemini to creative use cases in generating art (e.g. DALL-E and Sora), biology and neuroscience applications, robotics, and so forth!
Past speakers have included folks from @OpenAI, @GoogleDeepMind, @nvidia, @Meta, @AnthropicAI, etc. such as @karpathy, @geoffreyhinton, @DrJimFan, @ashVaswani, @_jasonwei, @hwchung27, @xiao_ted, @janleike, @YejinChoinka, @douwekiela, and many more! [Attached photos with some of them😎]
Our class has an incredibly popular reception within and outside Stanford, and over a million total views of our recordings [https://t.co/Eb4hKTZrbB] on YouTube. Our class with @karpathy was the second most popular YouTube video [https://t.co/vVMNYsKsEx] uploaded by Stanford in 2023 with over 750k views!
Also, livestreaming and auditing are available to all. Feel free to audit in person or by joining the Zoom livestream.
We also have a Discord server [https://t.co/vlDVm30x5F] (over 5000 members) used for Transformers discussion. We open it to the public as more of a "Transformers community". Feel free to join and chat with hundreds of others about Transformers!
Thanks to my co-instructors @DivGarg9@_KaranPS_@boson2photon Jenny Duan and the course's faculty advisor @chrmanning!
More details: https://t.co/Yvq4AcLiBV
@StanfordAILab@stanfordnlp@StanfordHAI@agihouse_org
#AI #ArtificialIntelligence #ML #DeepLearning #NLP #NLProc #Transformers #Stanford #Education #Innovation #TechEd #Community #naturallanguageprocessing
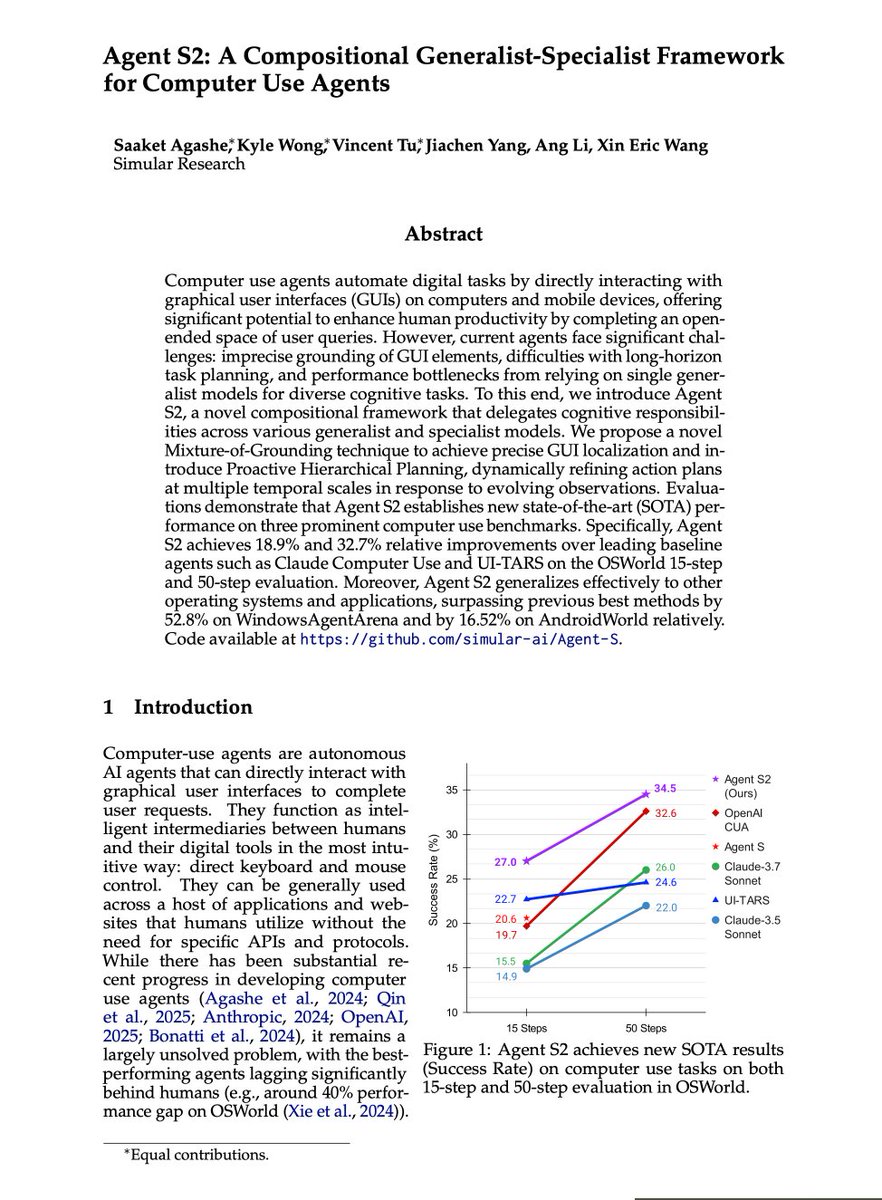
Since launching Agent S2, many folks working on GUI/computer-use agents asked for our tech report. Here we go! 🎉New SOTA on 3 major computer use benchmarks.
• OSWorld (15 steps): 27.0% 🚀 (+18.9%)
• OSWorld (50 steps): 34.5% 🚀 (+32.7%)
• WindowsAgentArena: 29.8% 🚀 (+52.8%)
• AndroidWorld: 54.3% 🚀 (+16.5%)
We strive for simple solutions that work best.
Agent S focused on Memory; S2 crushes Grounding & Planning. Bigger things ahead—stay tuned!
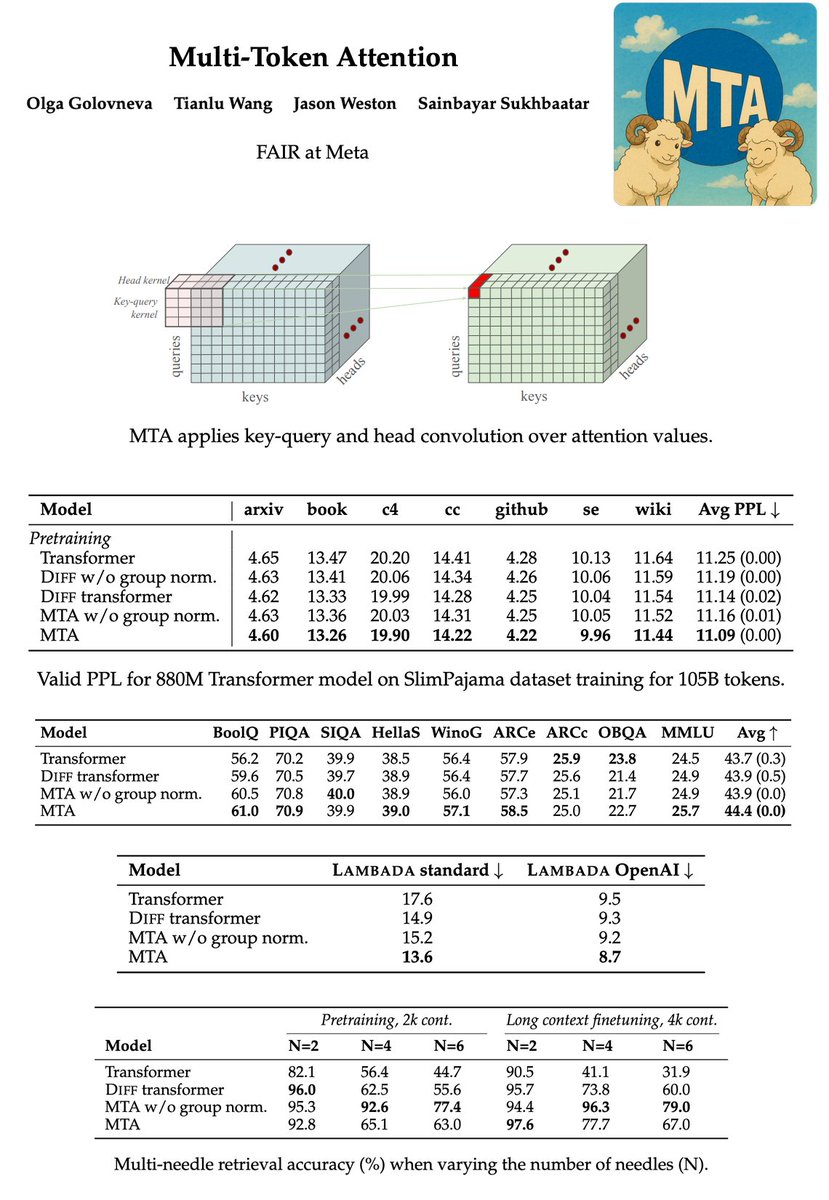
🚨Multi-Token Attention🚨
📝: https://t.co/79YMoUsGJD
Attention is critical for LLMs, but its weights are computed by single query & key vectors, limiting capability.
MTA combines query, key & head operations over multiple tokens, improving performance in terms of PPL, std benchmarks, and long-range tasks.
NOTE: this isn't an April Fool, this is a real paper🏛️👩⚖️💯
Interesting paper: Video-R1 improves temporal reasoning in MM LLMs using T-GRPO a variant of GRPO and high quality curated data for SFT.
Here's a summary: https://t.co/YLyZqsizIJ
Original paper: https://t.co/WVcX0rlFfY
🎨 Understanding GPU Architecture from Cornell
This GPU architecture roadmap is a good starting point for diving deeper, along with the CUDA C++ programming guide PDF - both freely available from Cornell and NVIDIA.
I read the R1 zero paper and the method is very simple , just a tweak to PPO to fine tune deepseek v3 base using a verifiable sparse binary reward. The fact that they got it to work even though others failed is likely due to better data and/or their very efficient implementation













![stevenyfeng's tweet photo. We are bringing back Stanford’s CS 25 Transformers Course (https://t.co/Yvq4AcLiBV) today! It’s open to everybody!
This is one of @Stanford's hottest seminar courses. We open the course through Zoom to the public. Lectures start today (Tuesdays), 3-4:20pm PDT, at https://t.co/hhHwpf9L7h. Talks will be recorded and released ~2 weeks afterward.
Each week, we invite folks at the forefront of Transformers research to discuss the latest breakthroughs, from LLM architectures like GPT and Gemini to creative use cases in generating art (e.g. DALL-E and Sora), biology and neuroscience applications, robotics, and so forth!
Past speakers have included folks from @OpenAI, @GoogleDeepMind, @nvidia, @Meta, @AnthropicAI, etc. such as @karpathy, @geoffreyhinton, @DrJimFan, @ashVaswani, @_jasonwei, @hwchung27, @xiao_ted, @janleike, @YejinChoinka, @douwekiela, and many more! [Attached photos with some of them😎]
Our class has an incredibly popular reception within and outside Stanford, and over a million total views of our recordings [https://t.co/Eb4hKTZrbB] on YouTube. Our class with @karpathy was the second most popular YouTube video [https://t.co/vVMNYsKsEx] uploaded by Stanford in 2023 with over 750k views!
Also, livestreaming and auditing are available to all. Feel free to audit in person or by joining the Zoom livestream.
We also have a Discord server [https://t.co/vlDVm30x5F] (over 5000 members) used for Transformers discussion. We open it to the public as more of a "Transformers community". Feel free to join and chat with hundreds of others about Transformers!
Thanks to my co-instructors @DivGarg9 @_KaranPS_ @boson2photon Jenny Duan and the course's faculty advisor @chrmanning!
More details: https://t.co/Yvq4AcLiBV
@StanfordAILab @stanfordnlp @StanfordHAI @agihouse_org
#AI #ArtificialIntelligence #ML #DeepLearning #NLP #NLProc #Transformers #Stanford #Education #Innovation #TechEd #Community #naturallanguageprocessing](https://pbs.twimg.com/media/GneEoBnbwAAzKp8.jpg)
![stevenyfeng's tweet photo. We are bringing back Stanford’s CS 25 Transformers Course (https://t.co/Yvq4AcLiBV) today! It’s open to everybody!
This is one of @Stanford's hottest seminar courses. We open the course through Zoom to the public. Lectures start today (Tuesdays), 3-4:20pm PDT, at https://t.co/hhHwpf9L7h. Talks will be recorded and released ~2 weeks afterward.
Each week, we invite folks at the forefront of Transformers research to discuss the latest breakthroughs, from LLM architectures like GPT and Gemini to creative use cases in generating art (e.g. DALL-E and Sora), biology and neuroscience applications, robotics, and so forth!
Past speakers have included folks from @OpenAI, @GoogleDeepMind, @nvidia, @Meta, @AnthropicAI, etc. such as @karpathy, @geoffreyhinton, @DrJimFan, @ashVaswani, @_jasonwei, @hwchung27, @xiao_ted, @janleike, @YejinChoinka, @douwekiela, and many more! [Attached photos with some of them😎]
Our class has an incredibly popular reception within and outside Stanford, and over a million total views of our recordings [https://t.co/Eb4hKTZrbB] on YouTube. Our class with @karpathy was the second most popular YouTube video [https://t.co/vVMNYsKsEx] uploaded by Stanford in 2023 with over 750k views!
Also, livestreaming and auditing are available to all. Feel free to audit in person or by joining the Zoom livestream.
We also have a Discord server [https://t.co/vlDVm30x5F] (over 5000 members) used for Transformers discussion. We open it to the public as more of a "Transformers community". Feel free to join and chat with hundreds of others about Transformers!
Thanks to my co-instructors @DivGarg9 @_KaranPS_ @boson2photon Jenny Duan and the course's faculty advisor @chrmanning!
More details: https://t.co/Yvq4AcLiBV
@StanfordAILab @stanfordnlp @StanfordHAI @agihouse_org
#AI #ArtificialIntelligence #ML #DeepLearning #NLP #NLProc #Transformers #Stanford #Education #Innovation #TechEd #Community #naturallanguageprocessing](https://pbs.twimg.com/media/GneEH-gaYAAi-Yn.jpg)
![stevenyfeng's tweet photo. We are bringing back Stanford’s CS 25 Transformers Course (https://t.co/Yvq4AcLiBV) today! It’s open to everybody!
This is one of @Stanford's hottest seminar courses. We open the course through Zoom to the public. Lectures start today (Tuesdays), 3-4:20pm PDT, at https://t.co/hhHwpf9L7h. Talks will be recorded and released ~2 weeks afterward.
Each week, we invite folks at the forefront of Transformers research to discuss the latest breakthroughs, from LLM architectures like GPT and Gemini to creative use cases in generating art (e.g. DALL-E and Sora), biology and neuroscience applications, robotics, and so forth!
Past speakers have included folks from @OpenAI, @GoogleDeepMind, @nvidia, @Meta, @AnthropicAI, etc. such as @karpathy, @geoffreyhinton, @DrJimFan, @ashVaswani, @_jasonwei, @hwchung27, @xiao_ted, @janleike, @YejinChoinka, @douwekiela, and many more! [Attached photos with some of them😎]
Our class has an incredibly popular reception within and outside Stanford, and over a million total views of our recordings [https://t.co/Eb4hKTZrbB] on YouTube. Our class with @karpathy was the second most popular YouTube video [https://t.co/vVMNYsKsEx] uploaded by Stanford in 2023 with over 750k views!
Also, livestreaming and auditing are available to all. Feel free to audit in person or by joining the Zoom livestream.
We also have a Discord server [https://t.co/vlDVm30x5F] (over 5000 members) used for Transformers discussion. We open it to the public as more of a "Transformers community". Feel free to join and chat with hundreds of others about Transformers!
Thanks to my co-instructors @DivGarg9 @_KaranPS_ @boson2photon Jenny Duan and the course's faculty advisor @chrmanning!
More details: https://t.co/Yvq4AcLiBV
@StanfordAILab @stanfordnlp @StanfordHAI @agihouse_org
#AI #ArtificialIntelligence #ML #DeepLearning #NLP #NLProc #Transformers #Stanford #Education #Innovation #TechEd #Community #naturallanguageprocessing](https://pbs.twimg.com/media/GneEFCDbYAA3di2.jpg)




























![stevenyfeng's tweet photo. We are bringing back Stanford’s CS 25 Transformers Course (https://t.co/Yvq4AcLiBV) today! It’s open to everybody!
This is one of @Stanford's hottest seminar courses. We open the course through Zoom to the public. Lectures start today (Tuesdays), 3-4:20pm PDT, at https://t.co/hhHwpf9L7h. Talks will be recorded and released ~2 weeks afterward.
Each week, we invite folks at the forefront of Transformers research to discuss the latest breakthroughs, from LLM architectures like GPT and Gemini to creative use cases in generating art (e.g. DALL-E and Sora), biology and neuroscience applications, robotics, and so forth!
Past speakers have included folks from @OpenAI, @GoogleDeepMind, @nvidia, @Meta, @AnthropicAI, etc. such as @karpathy, @geoffreyhinton, @DrJimFan, @ashVaswani, @_jasonwei, @hwchung27, @xiao_ted, @janleike, @YejinChoinka, @douwekiela, and many more! [Attached photos with some of them😎]
Our class has an incredibly popular reception within and outside Stanford, and over a million total views of our recordings [https://t.co/Eb4hKTZrbB] on YouTube. Our class with @karpathy was the second most popular YouTube video [https://t.co/vVMNYsKsEx] uploaded by Stanford in 2023 with over 750k views!
Also, livestreaming and auditing are available to all. Feel free to audit in person or by joining the Zoom livestream.
We also have a Discord server [https://t.co/vlDVm30x5F] (over 5000 members) used for Transformers discussion. We open it to the public as more of a "Transformers community". Feel free to join and chat with hundreds of others about Transformers!
Thanks to my co-instructors @DivGarg9 @_KaranPS_ @boson2photon Jenny Duan and the course's faculty advisor @chrmanning!
More details: https://t.co/Yvq4AcLiBV
@StanfordAILab @stanfordnlp @StanfordHAI @agihouse_org
#AI #ArtificialIntelligence #ML #DeepLearning #NLP #NLProc #Transformers #Stanford #Education #Innovation #TechEd #Community #naturallanguageprocessing](https://pbs.twimg.com/media/GneE2bibUAAFnZD.png)