Building dumb machines with supervised learning; AI researcher in practice | past 》MERL, SamsungResearch | Current 》 Credit and Fraud modeling using AI
Very exhaustive and immersive draft ensuring #ResponsibleAI.
TLDR;
1/n👉 walks through various harms AI solution may have caused such as facial detection, resume screening with direct impact on citizens
Enforcement of Ethical use of AI encouraging govt/univ participation
Towards Responsible #AIForAll is a draft document on managing the risks of AI. Due to numerous requests, the last date for comments has been postponed to 28th August, 2020. #AIEthics
Read here: https://t.co/IvWvwAsQLB
ICYMI: we shipped a new type of channel in LangGraph 1.2 that's built for agents with lots of context!
this ships w/ deepagents v0.6, where we use this new channel for agent messages and files
files can have scratch work, todos, memories, skills, etc!
https://t.co/OSZG2Qmmx7
Recent thoughts:
The Shift to Long-Horizon Tasks
The most likely breakthrough this year will be in long-horizon tasks. We are moving toward a stage where Large Language Models (LLMs) learn to complete extended, complex missions by interacting with Agent environments. This is perhaps where the true value of LLMs lies. Take cybersecurity as an example: imagine a model that continuously hunts for software bugs and vulnerabilities. While it sounds like a search process, it’s actually the model learning the high-level intuition and methodology of a professional hacker. Unlike humans, AI can run 24/7 without fatigue. It could potentially find exploits at a much higher frequwill ency and claim bounties on platforms like HackerOne or BugCrowd. It sounds fun, but fundamentally, it's a revolution that displaces the hacker. If even hackers are being "disrupted," one can only imagine the impact on general programmers.
From One-Person to None-Person Companies
Building on long-horizon capabilities, Autonomous Agent Systems (AAS) will inevitably become the next frontier. Last year, we were discussing the rise of the "One Person Company" (OPC). I didn't expect us to move so quickly toward the "None Person Company" (NPC). It’s an ironic twist—we might all end up as NPCs in this new ecosystem.
Engineering the Impossible: Memory and Learning
To realize the vision above, we must solve three technical pillars: Memory, Continual Learning, and Self-Judging.
I used to think these would require massive paradigm shifts and years of research. However, the pressure from both the technical and application sides is so intense that we are seeing these capabilities emerge through ingenious engineering "tricks":
Memory: Long context windows (1M+) and RAG have significantly bridged the gap.
Continual Learning: While true continual learning remains difficult, the release cycles are shrinking. Global models are updated monthly; domestic models are catching up. If we reach weekly updates by next year, it will effectively function as continual learning.
Self-Judging: This remains the most elusive, yet models like Opus 4.7 are already demonstrating early self-correction and judgment capabilities.
The Self-Evolving Endgame
The most difficult—and most promising—path is Self-Evolution. The current wave is incredibly fierce. I suspect that models like Claude may have already achieved a baseline for self-training: writing their own code, cleaning their own data, generating synthetic data, and then training on it. It might "waste" some compute, but it saves the most precious resources: human labor and time. In the LLM era, speed is everything. Rapid iteration is what creates the cognitive gap between leaders and followers. Claude’s rumored 2-million-chip cluster for next year is likely dedicated to exactly this: autonomous model self-training.
Technical Summary:
1M Context: Necessary baseline.
Memory & Continual Learning: Prerequisites, likely solved first via "tricky" engineering.
Harnessing Environments: The breakthrough point.
Self-Judging: The tipping point.
Full Self-Training: The endgame.
Redefining AGI and the Industry
If this is the road to AGI, then AGI’s definition should be the sum of all human collective intelligence, not just an individual’s intelligence. It must possess the creative capacity to produce something as profound as the "Theory of Relativity"—meeting the bar set by Hassabis.
During this transition, every APP will need to be reconstructed as AI-native. In fact, we might move past the concept of APPs entirely. The most significant challenge will be the reconstruction of the operating system itself. In the future, you won’t see a traditional desktop; you will see an LLM OS, where applications are "generated on demand." This challenges the 80-year-old Von Neumann architecture and represents a total upheaval of the computer science industry.
The Irreversible Wave
From completing long-horizon tasks to fully autonomous operations, every sector—Security, Finance, Law, E-commerce—will be reshaped. Many friends have reached out lately, asking how to transform their enterprises to keep pace with AI. But few truly realize that this irreversible process has already begun. As this massive technical wave hits, we must be prepared to act, but we must also start thinking seriously about how to regulate it.
We took @karpathy's autoresearch agent, scaled it into a collaborative swarm, and topped @OpenAI's Parameter Golf Challenge—twice. Here’s how we did it:
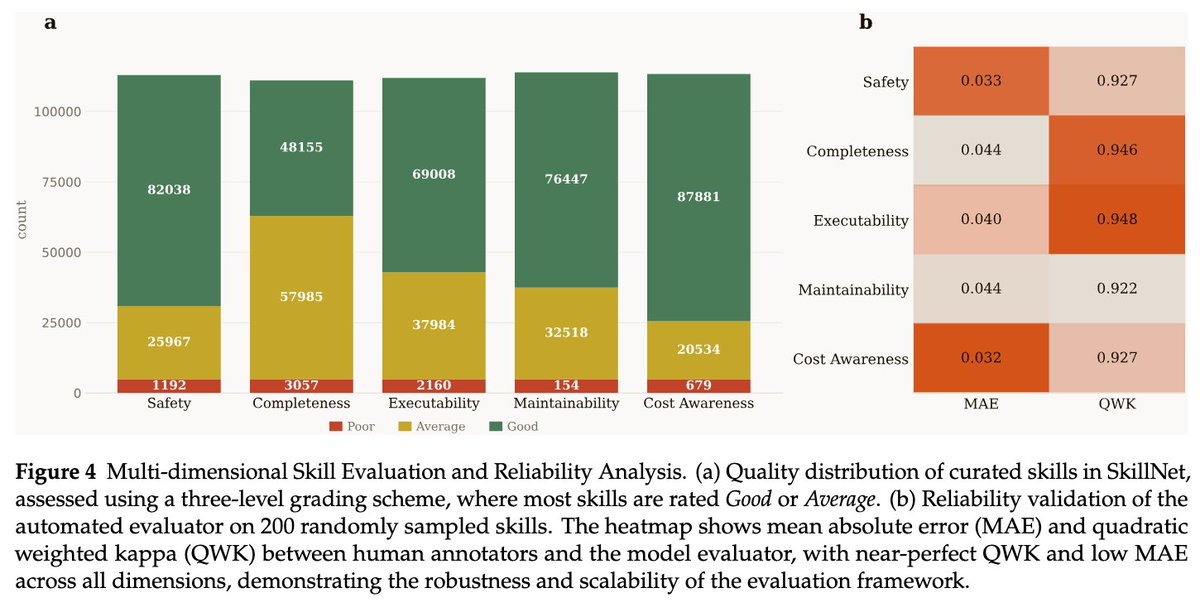
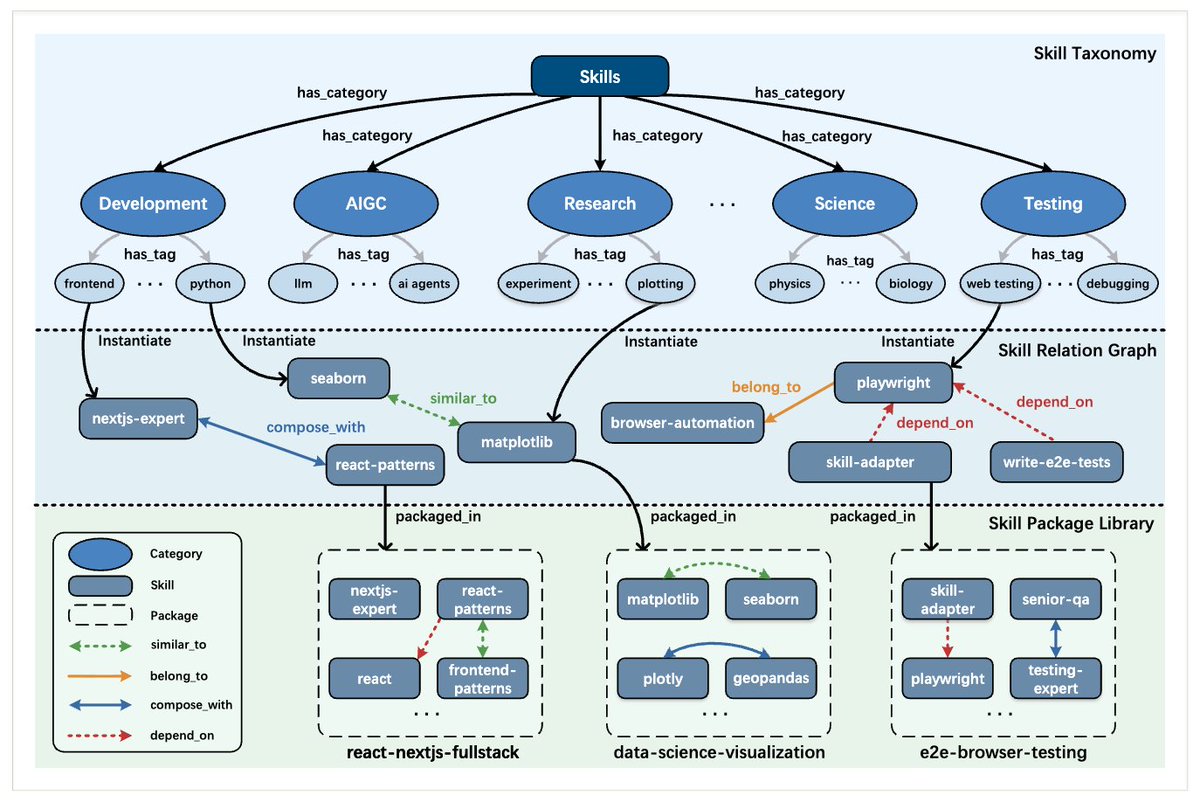
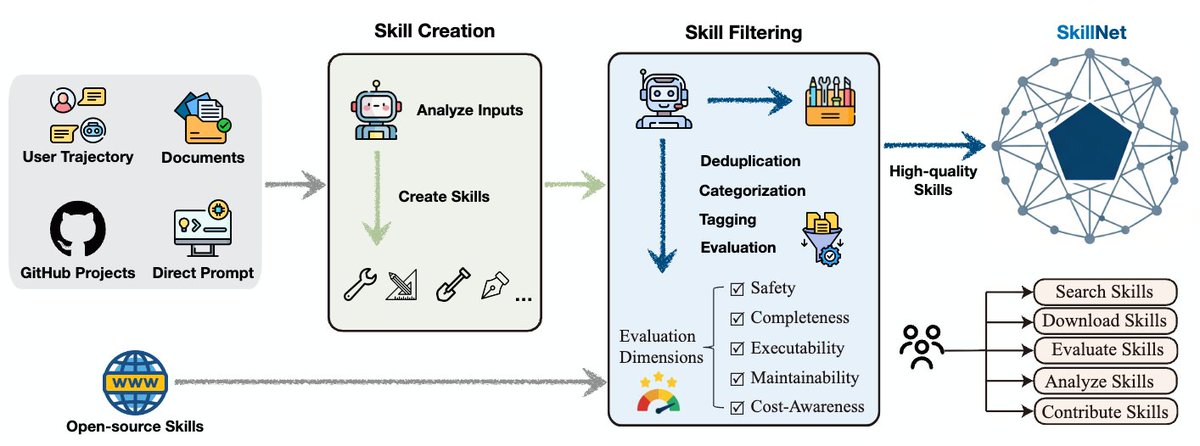
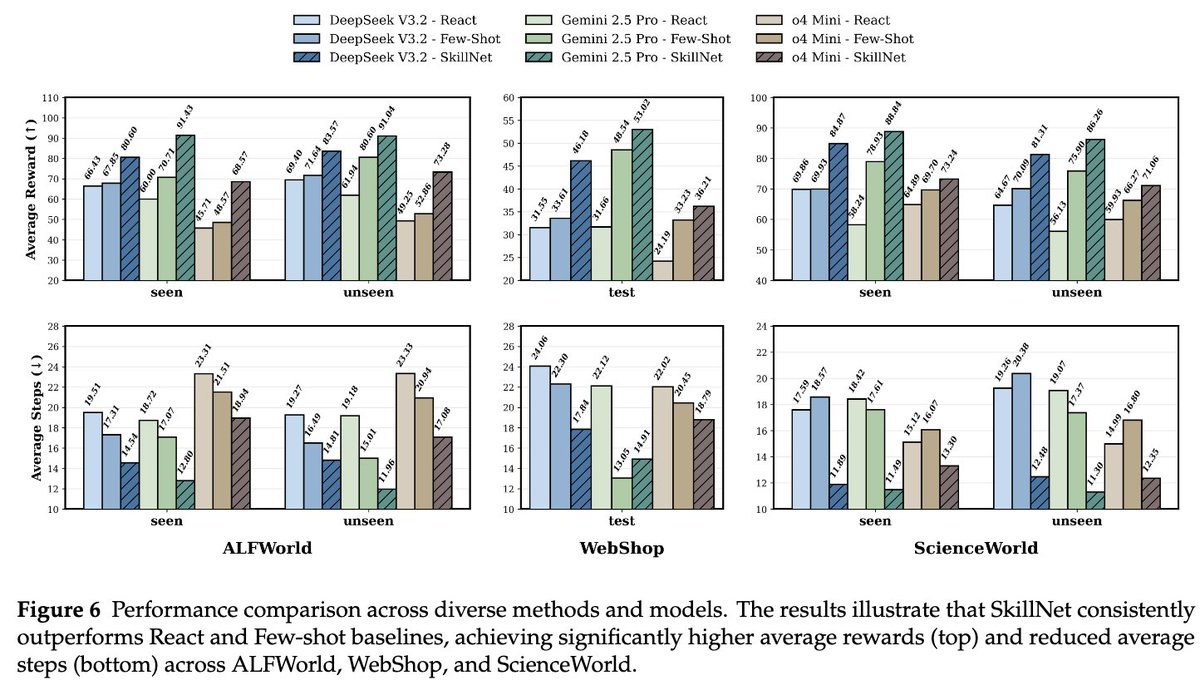
We’re releasing the technical report for SkillNet.
Report: https://t.co/9Hp3OcDI6y
Homepage: https://t.co/VEaFsY8YLV
Code: https://t.co/2Zej4VL7Rk
SkillNet explores this idea by providing a framework to create, evaluate, and organize executable AI skills at scale.
SkillNet is still experimental, but we hope it can serve as a foundation for scalable skill accumulation in AI agents.
Additionally, we have been exploring an interesting direction: Enterprise adoption through a private SkillNet.
For enterprises, SkillNet may act as an engine for accumulating operational knowledge, turning expert SOPs and internal APIs into reusable agent skills, enabling secure private skill repositories, and allowing agents across teams to invoke business capabilities as easily as library functions. 🚀
Feedback and suggestions are very welcome.
#SkillNet #AIInfrastructure #Agents #LLMs #NLP
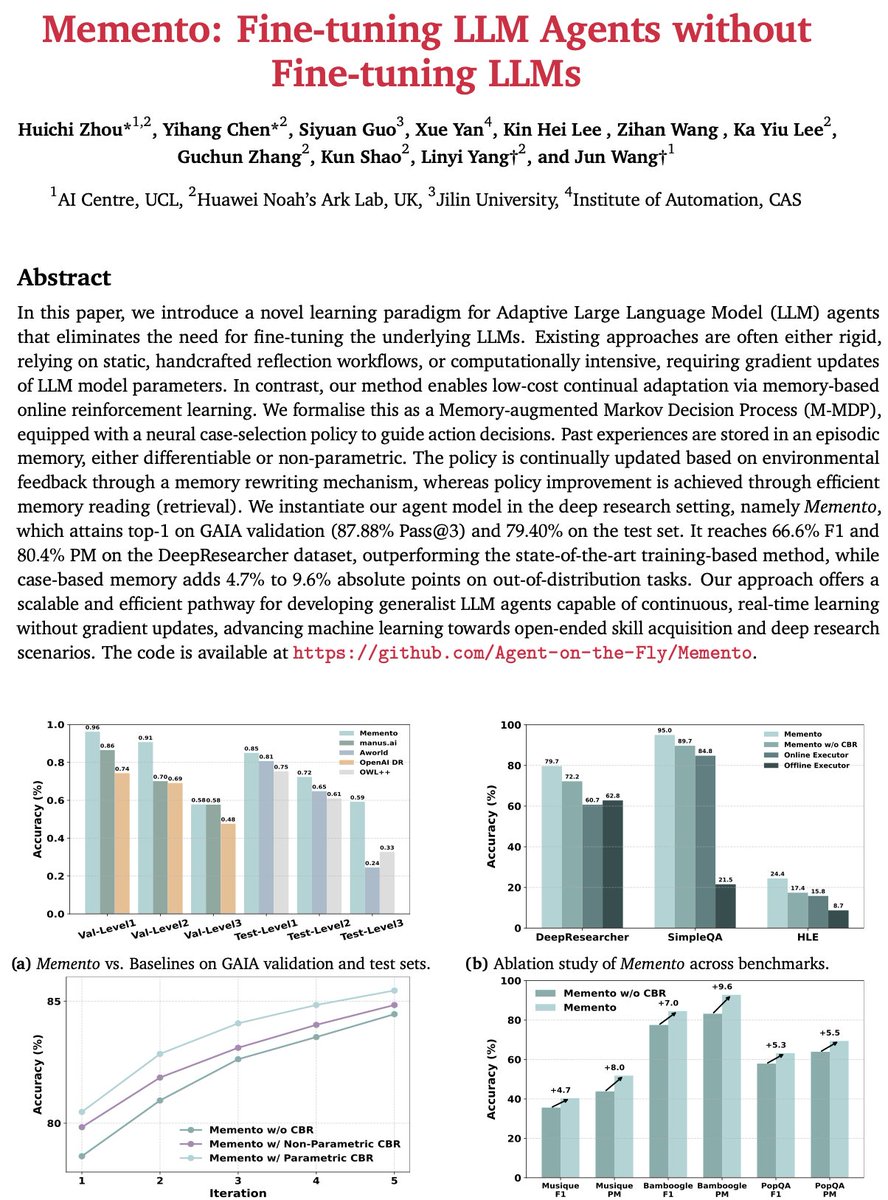
Fine-tune LLM agents without fine-tuning LLMs!
Memento is a memory based continual learning framework for LLM agents that lets them learn from experience over time without touching model weights.
It maintains a Case Bank of past trajectories including tasks, step sequences, tool usage, and outcomes.
When a new task comes in, the agent plans and acts by pulling from similar past cases instead of starting from zero.
Memento follows a planner and executor setup:
1. The Planner (an LLM) breaks the task into subtasks, retrieves relevant cases, and chooses a plan.
2. The Executor runs those subtasks using tools like search, code execution, or document processing through the Model Context Protocol (MCP), then logs the results back into memory.
Key Features:
• Memory based continual learning that improves agents through stored experience
• Planner and executor architecture with case based reasoning for task decomposition
• Unified tool ecosystem for search, code execution, document processing, media analysis and more
• Learning without weight updates by retrieving and reusing relevant past cases
• Strong results on long horizon and out of distribution tasks in reported benchmarks
It is 100% open source.
Link to the GitHub repo in the comments!
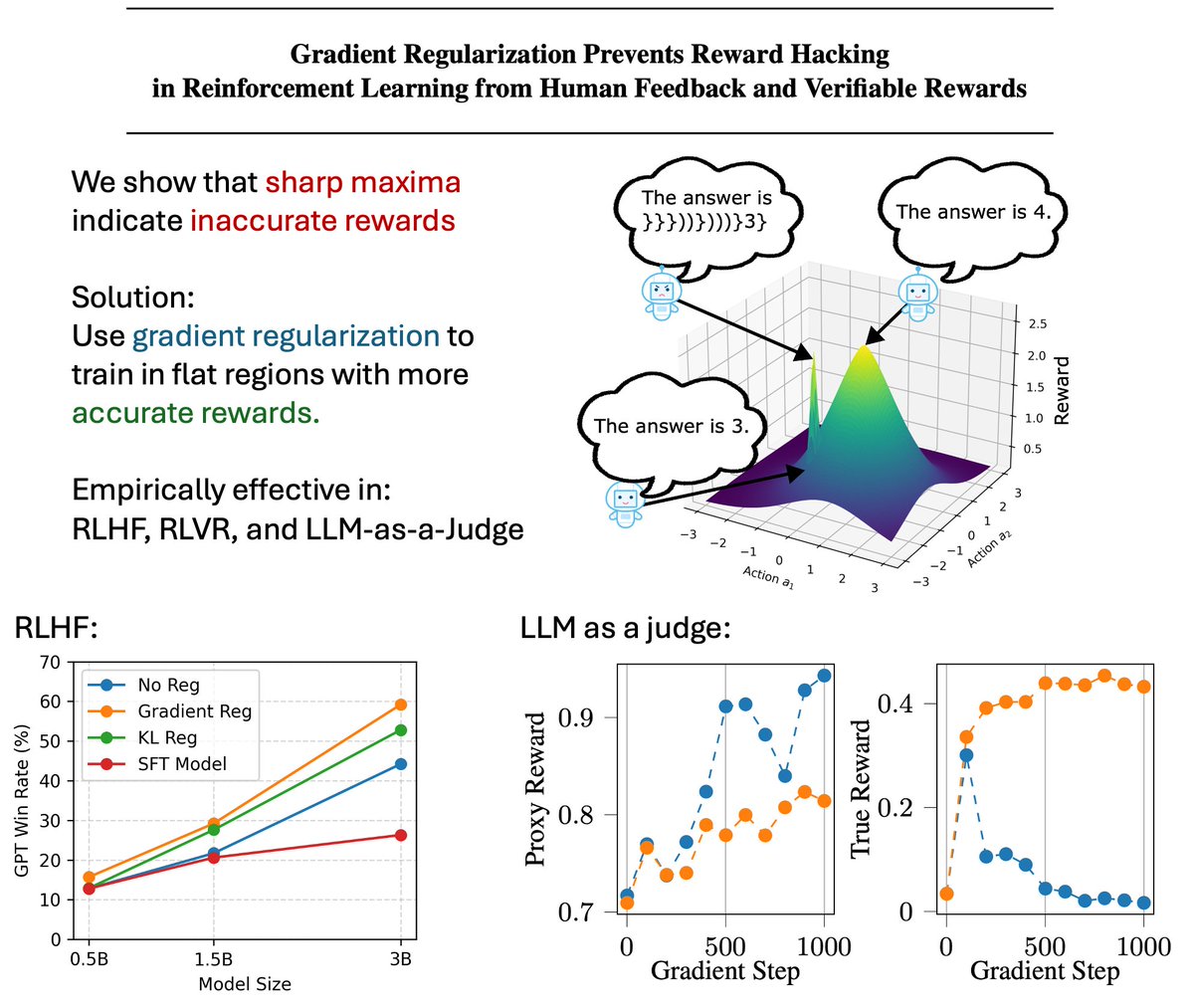
Tired of KL penalties constraining your model?
But don't want your policy to just hack the reward?
Try Gradient Regularization!
We show it beats a KL penalty in RLHF, RLVR and LLM-as-a-Judge!
🧵1/7
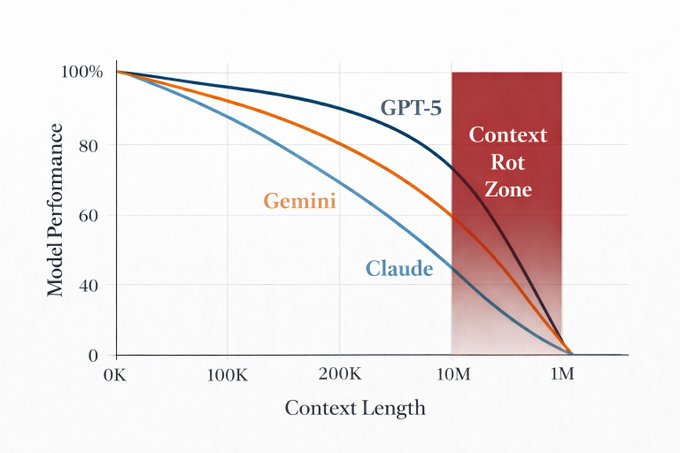
WTF DeepMind. 🤯
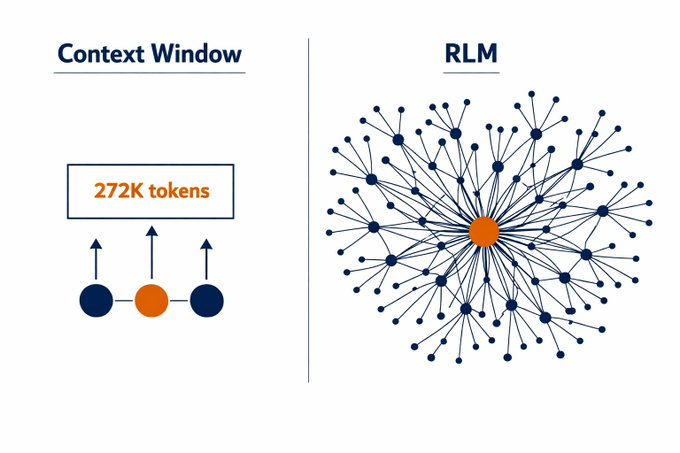
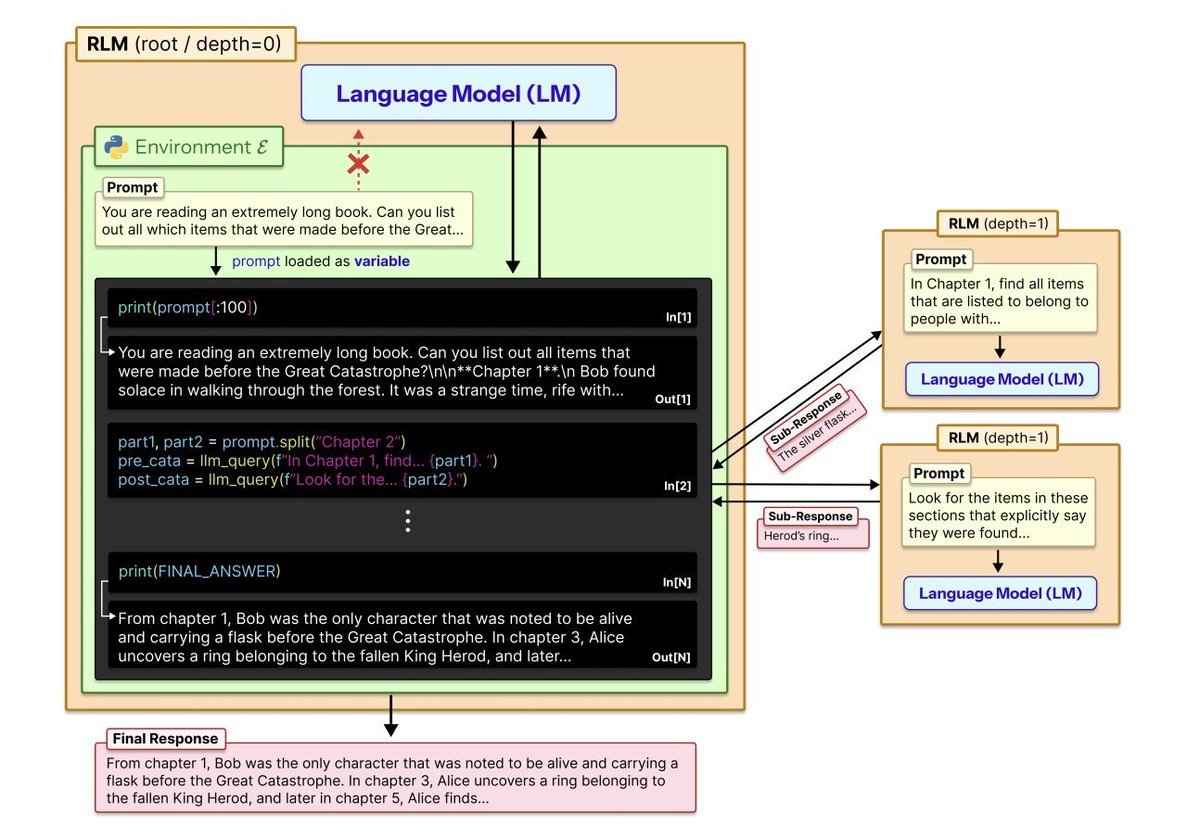
They built an AI that doesn't need RAG, and it has perfect memory of everything it's ever read.
It's called Recursive Language Models, and it might mark the death of traditional context windows forever.
- Everyone's been obsessed with context windows like it's a dick-measuring contest.
We have 2M tokens! No, WE have 10M tokens!
Cool. Your model still forgets everything past 100K. They call it "context rot" and every frontier model suffers from it.
- RAG was supposed to save us.
Just retrieve the relevant chunks, stuff them in the prompt, problem solved.
Except RAG is fundamentally broken for anything that actually matters.
It can't handle tasks where you need to look at multiple parts of a document simultaneously.
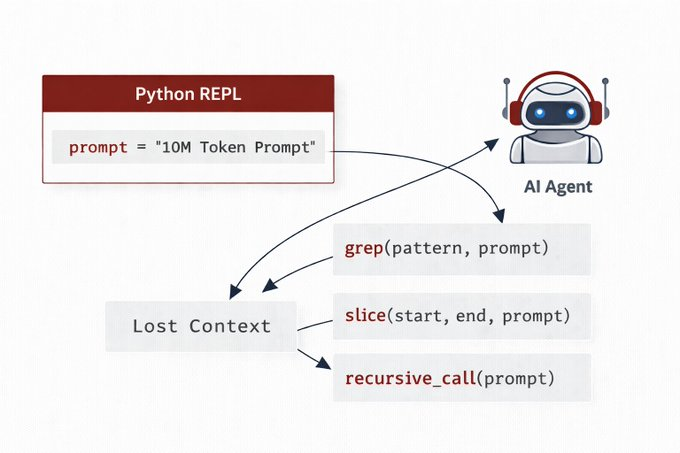
- Recursive Language Models flip the entire script.
Instead of shoving 10M tokens directly into the model, you load the prompt as a variable in a Python REPL.
The model writes code to search, slice, and recursively call itself on relevant snippets.
It's so obvious in hindsight.
- RLMs let AI do exactly that.
The prompt isn't processed linearly it's an environment the model navigates programmatically.
- The results are absolutely disgusting:
GPT-5 base model on multi-document research: 0% (literally couldn't fit it)
GPT-5 with RLM: 91%
On information-dense reasoning:
Base: 0.04%
RLM: 58%
That's not incremental improvement.
That's a different capability emerging.
- What's wild is the models figured out their own strategies without being trained for this.
They started using regex to filter context without reading it all. Breaking tasks into recursive sub-calls. Verifying answers by querying themselves again.
Zero special training.
Just emergent behavior.
- The cost situation is actually better than you'd think.
Yeah, some trajectories get expensive because the model keeps recursing.
But the median RLM run is cheaper than the base model.
Why? Because it only reads what it needs instead of ingesting 10M tokens upfront.
- This completely changes what's possible:
- Analyzing entire legal codebases
- Understanding million-line repositories
- Synthesizing hundreds of research papers
- Processing years of medical records
All of these were theoretically possible but practically broken. Not anymore.
- The researchers tested on GPT-5 and Qwen3-Coder with zero modification.
No fine-tuning.
No special training.
Just give them a REPL environment and recursive access.
That means you can use this approach right now with existing models.
- Here's the kicker: current models are terrible at this compared to what's possible.
They make dumb decisions. Repeat work. Sometimes compute the right answer and then... ignore it.
Imagine explicitly training models to think recursively. We're still at the starting line.
- Everyone's been focused on the wrong problem.
The question isn't "how do we cram more tokens into context windows"
It's "how do we let AI intelligently navigate unbounded information."
RLMs just proved you don't need bigger windows.
You need smarter navigation.
paper : https://t.co/8mcm19V2E1
Can AI agents design better memory mechanisms for themselves?
Introducing Learning to Continually Learn via Meta-learning Memory Designs. A meta agent automatically designs memory mechanisms, including what info to store, how to retrieve it, and how to update it, enabling agentic systems to continually learn across diverse domains. Led by @yimingxiong_ with @shengranhu 🧵👇 1/
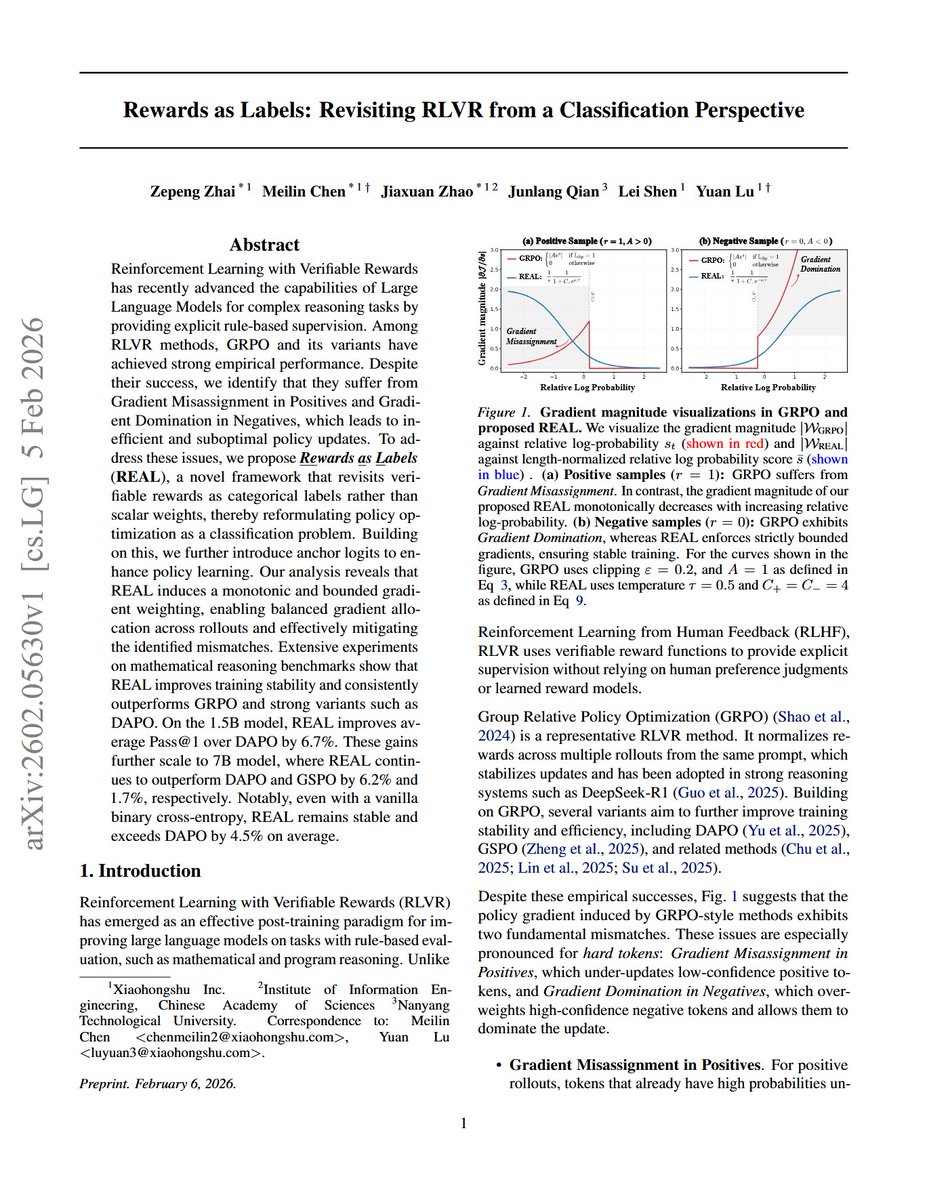
Rewards as Labels: Revisiting RLVR from a Classification Perspective
"we propose Rewards as Labels (REAL), a novel framework that revisits verifiable rewards as categorical labels rather than scalar weights, thereby reformulating policy optimization as a classification problem. "
A fundamental challenge in machine learning, feature selection is NP-hard (i.e., a problem that is mathematically "impossible" to solve perfectly and quickly for large groups of data), which makes it a highly challenging area of research.
We introduce Sequential Attention, an algorithm that optimizes subset selection in large-scale ML models.
This is an effective technique for multiple large-scale subset selection problems in deep learning and plays a key role in model architecture optimization. As these techniques evolve, they will solidify the future of machine learning.
If you have a 14–16-year-old, encourage them to apply to Stanford AI4ALL (by @StanfordHAI).
Incredible early exposure to AI and future careers in tech. (Applications close in 2 days)
Learn more and apply: https://t.co/8JN6qmosGJ
If you used to work at Zomato, whether you chose to move on, or I was the one who asked you to leave, this is for you.
I know that for many of you, Zomato didn't have the environment, or the leadership you needed at the time. But I know for sure, that you loved being at Zomato, and it is quite possible that you never felt like home anywhere else since you left.
We have over four hundred people at Eternal today in their second or third stints. Many of them are doing their best work now. Maybe because they've grown, but also because the company has grown. We are more organised, a little less chaotic, and hopefully, I've learned a few things along the way too.
If you haven't reached out because you think the door is closed, or because you think I'm holding onto the past, I'm not. I want you back.
There is so much to build at Eternal. We are today, a family of companies. Zomato, Blinkit Quick-Commerce, Blinkit Ambulances, District, Hyperpure, Nugget, and Feeding India. We need people who already know what good looks like here, and who care enough to fight for it. There is no better person for that than someone who has been here, left, grown, and wants to come back.
You might say that Eternal is not going to be the same, because I am not the CEO anymore. But ask yourself a question. Did titles ever matter at Eternal? I am still very much here, and I'd love for you to be a part of this next phase of Eternal.
If you feel like you have unfinished business here, please don't overthink it. Write to me at [email protected]. The Gurgaon pollution is still a bug, but being at Eternal is the feature. Let's talk and find a role that fits your life as it is today.
really solid technical read on agentic RL: detailed iterations, fixes, and lessons learned along the way!
love seeing the LinkedIn team share this kind of process 🫡
https://t.co/yktw2dQOR7
The gem is 👌
Important clarification: “test time” here is basically one episode / one prompt / one long sequence. You start from the same base model W_0, adapt within that sequence, then reset back to W_0 for the next sequence — so this is not persistent memory across sessions.
For some reason this latest LLM test-time training (TTT) paper reads a lot like a well-written paper from the “pre-LLM” era — where you can actually feel what the authors are thinking, instead of many “post-LLM” papers which may feel hollow at times.
The core idea behind what they call TTT-E2E is simple:
at “test time”, the model keeps doing next-token prediction on the context and updates its own weights, so it “writes” useful info from the prefix directly into parameters.
(They still use sliding-window attention for local context; the long-range part comes from weight updates.)
One practical detail that helped it click for me: “test time” has two phases — prefill and generation.
• During prefill (reading the prompt/context), they run these weight updates as the model consumes the context (in chunks).
• During generation (autoregressive decode), weights don’t change every token — but if you generate long enough, they can keep updating: decode normally until you accumulate a full mini-batch (≈1K tokens), take one TTT update on that batch, then continue decoding with the updated weights.
The key difference vs standard cross-entropy training is:
• In standard training, one fixed set of weights must work for all tokens in the sequence (e.g., 8K tokens).
• In TTT-E2E, the weights change inside the sequence — prediction at token t uses weights already updated from earlier tokens (in practice, earlier ~1K-token chunks).
Important clarification: “test time” here is basically one episode / one prompt / one long sequence. You start from the same base model W_0, adapt within that sequence, then reset back to W_0 for the next sequence — so this is not persistent memory across sessions.
Concretely:
• inner loop: do next-token prediction on the context and take gradient steps (they do this in ~1K-token chunks)
• outer loop: meta-train the model so it’s good at those test-time updates (optimize the loss after the inner loop)
Another subtle point: the inner-loop loss is still standard next-token CE, but the objective changes because they train the model so it performs well after these test-time updates.
So the loss isn’t “how good is this fixed model on all tokens?”
It’s “how good is this model after learning from the prefix?”
The results are kind of wild: with only sliding-window attention + test-time learning, they match full-attention quality scaling up to 128K context, while keeping constant inference latency (they report ~2.7× faster than full attention at 128K).
There’s also a very honest failure mode: they lose badly on Needle-in-a-Haystack retrieval tasks — which actually makes sense. This method is doing compression: long-range info has to be squeezed into a fixed-size set of updated weights, so it’s not lossless like attention.
It also reframes a bunch of recent long-context lines (RNNs, DeltaNet, Mamba, Titans, TTT-KVB): they start to look like different points in one space where weights are the state, and gradient descent is the state update rule.
Overall, highly recommend reading it slowly.
How do we know if RL is going well or not? Here are some key health indicators to monitor during the RL training process…
RL is a complex process made up of multiple disjoint systems. It is also computationally expensive, which means that tuning / debugging is expensive too! To quickly identify issues and iterate on our RL training setup, we need intermediate metrics to efficiently monitor the health of the training process. Key training / policy metrics to monitor include:
(1) Response length should increase during reasoning RL as the policy learns how to effectively leverage its long CoT. Average response length is closely related to training stability, but response length does not always monotonically increase—it may stagnate or even decrease. Excessively long response lengths are also a symptom of a faulty RL setup.
(2) Training reward should increase in a stable manner throughout training. A noisy or chaotic reward curve is a clear sign of an issue in our RL setup. However, training rewards do not always accurately reflect the model’s performance on held-out data—RL tends to overfit to the training set.
(3) Entropy of the policy’s next token prediction distribution serves as a proxy for exploration during RL training. We want entropy to lie in a reasonable range—not too low and not too high. Low entropy means that the next token distribution is too sharp (i.e., all probability is assigned to a single token), which limits exploration. On the other hand, entropy that is too high may indicate the policy is just outputting gibberish. Similarly to entropy, we can also monitor the model’s generation probabilities during RL training.
(4) Held-out evaluation should be performed to track our policy’s performance (e.g., average reward or accuracy) as training progresses. Performance should be monitored specifically on held-out validation data to ensure that no reward hacking is taking place. This validation set can be kept (relatively) small to avoid reducing the efficiency of the training process.
An example plot of these key intermediate metrics throughout the RL training process from DAPO is provided in the attached image. To iterate upon our RL training setup, we should i) begin with a reasonable setup known to work well, ii) apply interventions to this setup, and iii) monitor these metrics for positive or negative impact.
If you live in Germany, India, US or anywhere globally(open to relocate) and truly want to build the next way of work for humanity, join us as employee number 25 today.
We are working with frontier robotic labs already at large scale!
reach out at [email protected]
🚀 New paper drop on the path to continual learning: Entropy-Adaptive Fine-Tuning (EAFT)
A huge blocker to continual learning is catastrophic forgetting. This paper takes a meaningful step toward fixing it. Let me explain 👇
Catastrophic forgetting happens when fine-tuning improves a new task but overwrites existing capabilities. Standard SFT treats every error the same; even when the model is already very confident in its prediction.
The paper identifies Confident Conflicts: Cases where the model has low entropy (high confidence) but the training label strongly disagrees. SFT applies large gradients here → destructive updates → forgetting.
EAFT fixes this by scaling updates using token-level entropy:
• High entropy → learn normally
• Low entropy + conflict → dampen the update (to prevent destructive gradient updates)
RL tends to respect a model’s internal beliefs (sharpening distributions), while SFT often overwrites them (shifting distributions). Continual learning likely requires distribution-aware training with selective, uncertainty-aware updates.
⚠️ Your LLM RL training may be silently broken!
I recently had a deep dive podcast with @zzlccc from Sea AI Lab on the silent bugs in LLM Post-training. His recent work challenges the theoretical basis of DeepSeek’s GRPO and uncovered a precision issue highlighted by Andrej Karpathy.
1. The Math in GRPO is Actually Wrong?
The GRPO formula includes a term that divides by response length (1/L). This introduces length bias. With positive advantage, shorter responses get amplified weights so the model learns to take shortcuts. With negative advantage, long rambling errors get penalized less.
The Intuition Trap: We often apply SFT intuition (averaging loss over tokens) to RL. But RL optimizes for Expectation, not Average. Since the probability of generating a long response is naturally lower than a short one, the math already self-balances. Dividing by length again is "double-dipping" and breaks the unbiased nature of the policy gradient.
2. RL Training Instability? Blame BF16.
RL pipelines often split engines: vLLM for rollout (inference) and DeepSpeed for update (training). The industry standard BF16 trades precision for dynamic range. This low precision amplifies the numerical mismatch between engines, causing severe instability.
The fix is counter-intuitive: switch back to "legacy" FP16. In RL, you need precision, not range.
3. Not All Biases Are Created Equal. There is a "Hierarchy of Bias":
Level 1 (Theoretical): GRPO's length bias. A mathematical error that needs a fix.
Level 2 (Approximation): PPO Clipping. A deliberate variance-bias trade-off for stability. Acceptable.
Level 3 (Numerical): BF16 artifacts. Engineering noise. Mitigate via FP16.
4. Why Does This Only Break in RL? It comes down to Goal.
For pre-training, you're starting from scratch with wild gradient swings. You need BF16's range to prevent overflow.
For RL, the model is already smart and you're fine-tuning within a strictly bounded KL constraint. The gradients are tiny. The numerical noise drowns out the actual signal. You need the precision of FP16.