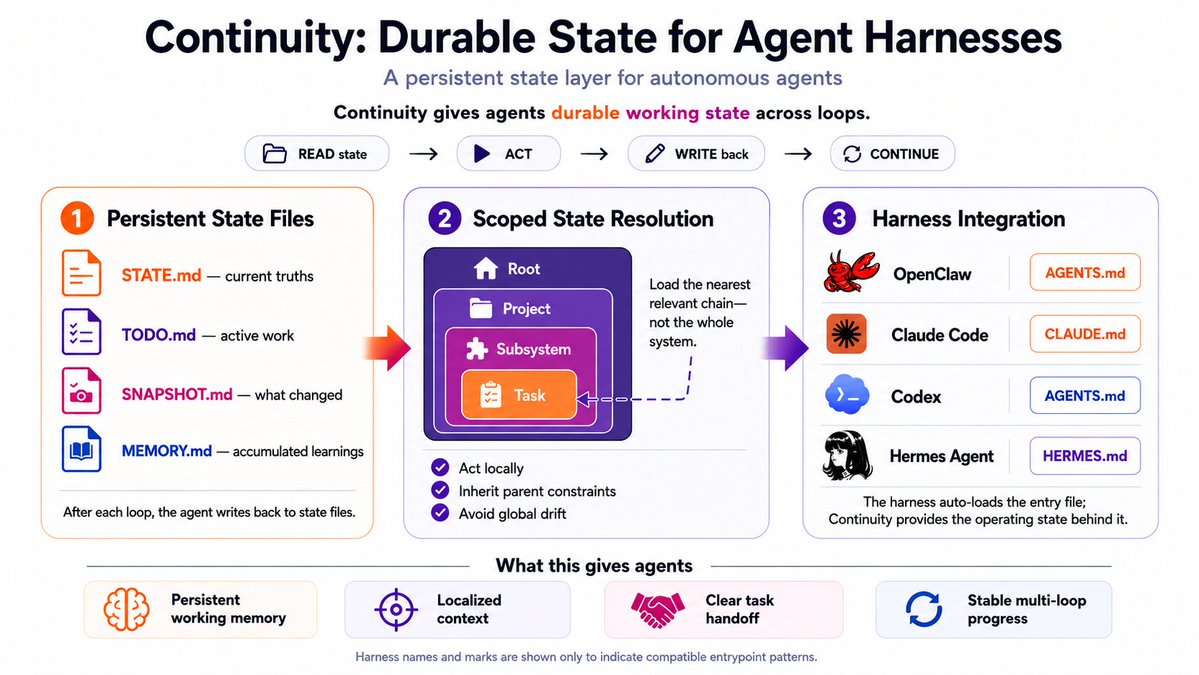
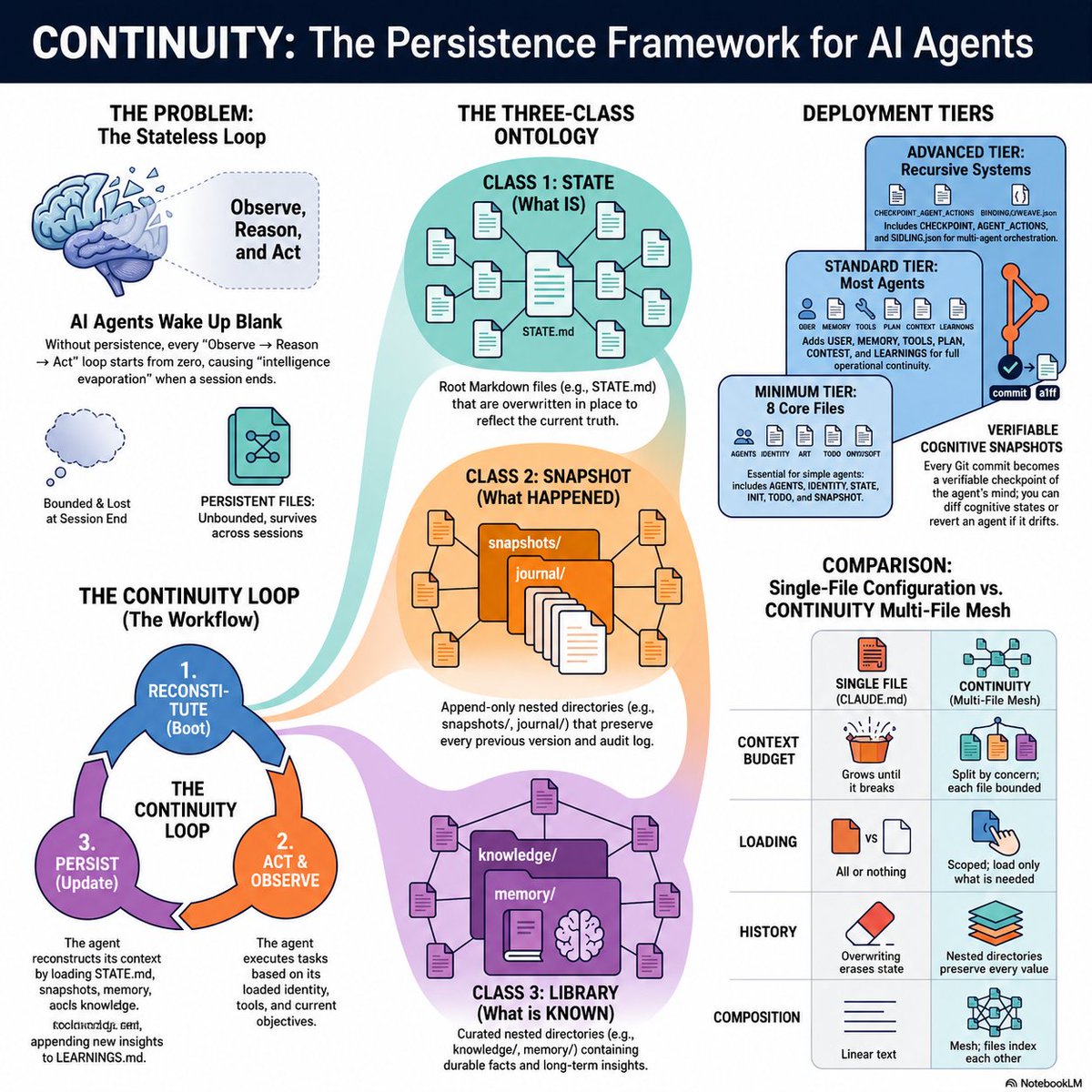
Loops are units of intelligence.
Continuity is a state-file system for managing those loops.
Agents get durable working state: what is true, what changed, what matters, and what to do next.
Agents keep context across loops.
🌐https://t.co/N0Gut4EVqh
💻https://t.co/wmVrJTpyHO
Markov Gave Randomness Memory then Kolmogorov Gave It Motion
Markov gave us a way to describe random systems where the future depends only on the present state.
Kolmogorov took that idea further by studying what happens when these random changes unfold continuously in time. Instead of only watching particles jump from one state to another, he described how the entire probability cloud evolves.
The jump rates are stored in a generator Q, where qᵢⱼ tells us how quickly probability moves from state i to state j. To keep the total probability equal to one, the diagonal term balances all the outgoing rates
qᵢᵢ = -Σⱼ≠ᵢ qᵢⱼ
The whole distribution then follows the forward equation
dp/dt = pQ
or state by state,
dpⱼ/dt = Σᵢ pᵢqᵢⱼ.
The small paths look chaotic, yet together they reveal one moving law.
#AndreyKolmogorov #RussianMathematician #ProbabilityTheory #MarkovProcesses #StochasticProcesses #KolmogorovEquations #Mathematics #Randomness #ScienceCommunication
Asimov 1 is an open-source humanoid robot you can build and customize yourself.
Two ways to get one:
1) Source the parts yourself: https://t.co/vtG89UlhiK
2) Get the DIY kit: https://t.co/tzvzNyXiq2
The kit bundles every part as a group buy, cheaper than sourcing one by one, and you build alongside others.
e^π > π^e follows from bounding the integral of 1/x over [e, π].
The integral equals ln(π) - 1 and is less than (π - e)/e, the rectangle area at maximum height 1/e.
Simplification gives ln(π) < π/e, then e ln(π) < π or ln(π^e) < π. Exponentiation yields π^e < e^π.
This bounding technique supports inequality proofs for exponential expressions in physics modeling of variable rates and in economics for growth comparisons.
Continuity fits agent harnesses that auto-load project files.
Define the state topology so that the agent boots with a native map of its own persistent operating states.
🔹 @claudeai Claude Code → CLAUDE.md
🔹 @NousResearch Hermes → HERMES.md
🔹 @OpenAI Codex → AGENTS.md
Loops are units of intelligence.
Continuity is a state-file system for managing those loops.
Agents get durable working state: what is true, what changed, what matters, and what to do next.
Agents keep context across loops.
🌐https://t.co/N0Gut4EVqh
💻https://t.co/wmVrJTpyHO
After completing a loop, the agent actually writes to the state files.
It updates STATE.md with new truths, moves finished tasks from TODO.md to an archive, and appends new insights to its memory.
The context window is ephemeral, but the state files are unbounded and persistent
Benjamin Bycroft’s 3D interactive tool visualizes an LLM’s layers, weights and matrix operations.
This is the best educational tool to understand how an LLM works i've seen.
httpx://bbycroft.net/llm
Science is entering a new era - one where AI agents can do scientific work.
🧬 Today NVIDIA is launching the BioNeMo Agent Toolkit - an open, agent-ready toolkit that gives any AI agent callable tools for protein structure prediction, molecular docking, generative chemistry, genomic analysis, and more.
(1/2)
Imagine programming protein, DNA, and RNA systems like you would write computer code, or even by natural language prompting of an AI agent. @brianhie and team just made this a reality with Proto: a high-level programming language for generative biology.
You run Kernels, not models
The model is just a graph
The Inference Engine serves as a scheduler, optimizer, and executor
But the actual work? That happens in the Kernels
- MatMul Kernels
- Attention Kernels
- RMSNorm Kernels
- KV cache Kernels
- Quantized linear Kernels
- Sampling Kernels
- Fused “please don’t write this back to memory 9 times” Kernels
Same model, same GPU, same VRAM
Wildly different performance
Because one stack is using optimized fused Kernels that understand your hardware
And the other stack is playing hot potato with tensors through 47 tiny launches and pretending the GPU is the problem
Bad Kernels make people say:
“this model is slow”
Good Kernels make people say:
“wait how is this running locally?”
This is why Inference Engines and the Kernels implemented within them matter
The model is the recipe
The hardware is the kitchen
The Kernels are the knives, pans, burners, and the chef not cutting onions with a spoon
Most people benchmark models
The real ones benchmark the Kernels underneath
Introducing the Open Knowledge Format (OKF), an open specification that formalizes the LLM-wiki pattern into a portable, interoperable format.
AI is only as smart as the context we give it. As we build more advanced, agentic AI systems, they need accurate metadata and context to be useful. But in most organizations, that context is locked inside fragmented data catalogs, isolated wikis, scattered code comments, or the minds of senior engineers. Every time a new AI agent is built, teams are forced to solve the exact same context-assembly problem from scratch.
To solve this, we've announced OKF, a vendor-neutral, open specification that formalizes the "LLM-wiki pattern" into a portable, interoperable format. It provides a standardized way to represent the enterprise knowledge that modern AI systems rely on.
— Just markdown: readable in any editor, renderable on GitHub, indexable by any search tool
— Just files: shippable as a tarball, hostable in any git repo, mountable on any filesystem
— Just YAML frontmatter: for the small set of structured fields that need to be queryable: type, title, description, resource, tags, and timestamp
We’ve also shipped reference implementations to help you hit the ground running, including an enrichment agent for BigQuery, a static HTML visualizer, and live sample bundles on @github → https://t.co/ilhAMCrcTc
➕ Knowledge Catalog can now natively ingest OKF!
Stop reinventing data models and building bespoke integrations for every new AI tool. Here's more about how OKF works → https://t.co/FR4kJRsgEH
Lagrange points ✍️
When two large objects orbit each other in space, like the Sun and Earth, their combined gravity creates five special points called Lagrange points. At these points, a smaller object like a spacecraft can remain perfectly still relative to both bodies without drifting away, because all the forces acting on it balance out. Three of these points, L1, L2, and L3, lie along the straight line connecting the two bodies. L1 is located between them, L2 is just behind the smaller body, and L3 is directly on the opposite side of the larger body. These three points are unstable; if you nudge something there, it will slowly drift away, much like a ball balanced on top of a hill. Still, they are very useful; the James Webb Space Telescope is positioned at L2, where it remains cool and has a clear view of deep space. The other two points, L4 and L5, are the truly special ones. They are positioned 60 degrees ahead of and behind the smaller body in its orbit, forming a triangle with the two large masses. These points are naturally stable, like a ball resting in a bowl; if something is nudged, it will gently drift back. Thousands of asteroids have been resting at Jupiter's L4 and L5 for billions of years because of this stability. The red figure-8 shape shown in the diagram is called the Roche lobe, which marks the boundary of the smaller body's gravitational zone. If a star in a binary system expands beyond this boundary, its gas spills over to the companion star through L1, similar to water overflowing between two connected bowls. In simple terms, Lagrange points are nature's free parking spots in space, and we are just beginning to explore their use.
























![mathemetica's tweet photo. e^π > π^e follows from bounding the integral of 1/x over [e, π].
The integral equals ln(π) - 1 and is less than (π - e)/e, the rectangle area at maximum height 1/e.
Simplification gives ln(π) < π/e, then e ln(π) < π or ln(π^e) < π. Exponentiation yields π^e < e^π.
This bounding technique supports inequality proofs for exponential expressions in physics modeling of variable rates and in economics for growth comparisons.](https://pbs.twimg.com/media/HME4qA-bwAA-58a.jpg)