I don't really want to have to go to bat against Anthropic, but they've just been unnecessarily antagonistic to all of China, then not so subtly to open weight models, and now more broadly open AI research. What's next on the list?
On-Policy Distillation is the most active new research direction being explored in RL for LLMs. Had the chance to discuss how it works with Dwarkesh and why it fits so nicely into large-scale pipelines.
Super excited to announce seven new world-class MAI models today. They represent what we consider a new era in AI designed to keep you in control and on the frontier.
First is our text foundation model, MAI-Thinking-1, exceptionally strong on reasoning and SWE tasks.
- It’s a 35B active parameter MoE with a 256K context window. Independent human raters on Surge prefer it for overall quality in blind side-by-sides versus Sonnet 4.6, and it’s achieved 97% on AIME 2025, the key measure of its general-purpose reasoning abilities.
- It's at 53% on SWE Bench Pro, placing it right alongside Opus 4.6 on one of the toughest coding benchmarks.
- And since we co-designed our models with our own silicon, MAI-Thinking-1 is optimized on our MAIA 200 chip. Benchmarking head-to-head against the GB200, we see 30% better performance per dollar as well as a 1.4x performance-per-watt gain when running our MAI models on the MAIA 200 end-to-end.
Next is MAI-Image-2.5 and its Flash variant. Two super strong models now at #2 on the leaderboards, surpassing the score of Nano Banana 2 on image editing.
Last for now is MAI-Code-1-Flash, our new inference efficient coding model, especially tuned for VS Code and GitHub Copilot CLI.
- Code-1-Flash achieves 51% on SWE Bench Pro, despite having just 5B parameters, putting it closer to Haiku in size but cheaper in cost.
All of this is the foundation for Microsoft Frontier Tuning. It lets you customize our models to create custom, company-specific agents that only you control. You can make our model, your model. Your data. Your agents. Your moat.
Early adopters are already seeing a difference. When we tuned our models for McKinsey’s tasks, MAI delivered the highest win rate, outperforming GPT-5.5 on quality, while being 10x lower on cost.
Also really excited to be collaborating with the amazing team at Mayo Clinic to jointly train a new frontier AI model for healthcare.
Our announcements today mark another milestone on the road to humanist superintelligence. You can learn more and about our other new models in our latest blog: https://t.co/v65eop5Ixq
loved reading this! truly a clarifying and foundational take on moving from language-dominated AI to embodied, world-understanding systems.
the next big leap needs generative, multimodal, interactive “world models” that create consistent 3D/physical simulations from multiple (partial) inputs (text, images, actions), reason about geometry/physics/dynamics, and enable true interaction. this potentially could revolutionize robotics, immersive storytelling, scientific discovery, digital twins, and more.
My MLSys keynote on AI writing systems code got more interest than I expected. The recording will take a while, so in the finest tradition of AI labs sharing blog posts, we’re starting the Core Automation Blog with this one https://t.co/h4uSOyrglf
there is no better time in tech than now to be a jack of all trades, master of a few.
just make sure to keep adding to the few year over year, such that the cumulative breadth of expertise you collect becomes an increasingly rare combo. remember, if you're top 10% in 3 different areas, that already makes you top 0.1%. keep switching it up until you get to "your best", and then switch it up again (great for a particular flavor of people who don't enjoy resting on laurels, maybe not so great for others).
question all institutional value and pedigrees, all traditional career paths or corporate ladders: the college industrial complex is getting shaken up, alongside a disappearing managerial class, so if you're pursuing either make sure you are fully internally aligned with why. social/political capital in a particular institution can feel incredible, but if you're spending all your energy on complex political people games, you're not a technologist anymore, you're an unelected politician. if you're ok with that, then all's well.
critical thinking is more important than ever: take nothing at face-value, question everything and everyone. the equivalent of ai slop can be found in humans operating under misaligned incentives and interests. the sooner you're clued into disambiguating the talkers/larpers from the doers, the better off you'll be figuring out where and who to invest your time in.
the anxiety of job displacement is very real, since a surprising amount of white collar work/prestige is built on a performative house of cards, significantly lacking in correlation with technical breadth, depth, and skill. as long as you keep learning, keep building, keep producing receipts, you will be fine.
if all that sounds ok to you, welcome to the world of technology! it's truly one of the few places you can experience child-like wonder every few years, and be constantly humbled & excited by new adventures, as scary as they may seem at first.
don't give up, drink your water, get your sunlight, and take breaks as needed. tech careers are notoriously nonlinear, so you might as well embrace it and enjoy the ride!
DEEPSEEK VISION PAPER is here!
Thinking with Visual Primitives.
«By interleaving spatial markers (points and bounding boxes) directly into the reasoning trajectory as minimal units of thought, we anchor abstract linguistic concepts to concrete physical coordinates»
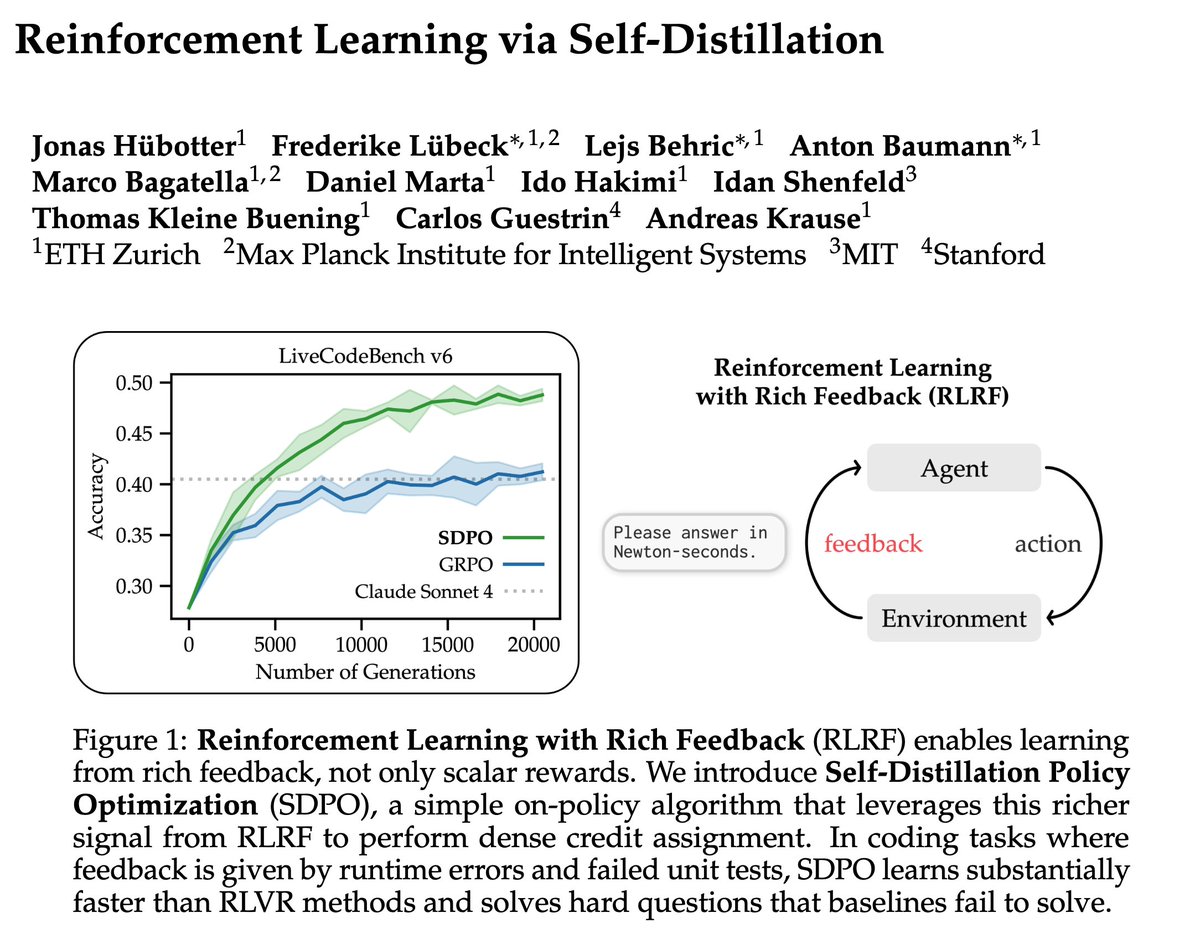
RL against verifiable rewards in LLMs has clearly opened a very powerful regime. It works, and because it works, there is a strong tendency to view more and more problems through that lens.
You optimize for tasks where the reward is clean, where success is easy to check, where the feedback loop closes quickly. This is productive and will keep paying off. But it also creates a bias: you start emphasizing what is legible to the training setup, not necessarily what is most valuable.
Scientific reasoning is a good example. Not every step in science is something that can be cleanly graded at the moment it is produced. A hypothesis can later fail experimentally and still have been exactly the right kind of thinking at the time: creative, mechanistically grounded, and responsive to the available evidence. “Turns out to be wrong” does not imply “was low-quality thinking”.
A big part of the next frontier will be AI systems that can operate well under this kind of uncertainty, just like a big part of the last one was RL against verifiable rewards.
Training LLMs with verifiable rewards uses 1bit signal per generated response. This hides why the model failed.
Today, we introduce a simple algorithm that enables the model to learn from any rich feedback!
And then turns it into dense supervision.
(1/n)
The Terence Tao episode.
We begin with the absolutely ingenious and surprising way in which Kepler discovered the laws of planetary motion.
People sometimes say that AI will make especially fast progress at scientific discovery because of tight verification loops.
But the story of how we discovered the shape of our solar system shows how the verification loop for correct ideas can be decades (or even millennia) long.
During this time, what we know today as the better theory can often actually make worse predictions (Copernicus's model of circular orbits around the sun was actually less accurate than Ptolemy's geocentric model).
And the reasons it survives this epistemic hell is some mixture of judgment and heuristics that we don’t even understand well enough to actually articulate, much less codify into an RL loop.
Hope you enjoy!
0:00:00 – Kepler was a high temperature LLM
0:11:44 – How would we know if there’s a new unifying concept within heaps of AI slop?
0:26:10 – The deductive overhang
0:30:31 – Selection bias in reported AI discoveries
0:46:43 – AI makes papers richer and broader, but not deeper
0:53:00 – If AI solves a problem, can humans get understanding out of it?
0:59:20 – We need a semi-formal language for the way that scientists actually talk to each other
1:09:48 – How Terry uses his time
1:17:05 – Human-AI hybrids will dominate math for a lot longer
Look up Dwarkesh Podcast on YouTube, Apple Podcasts, or Spotify.
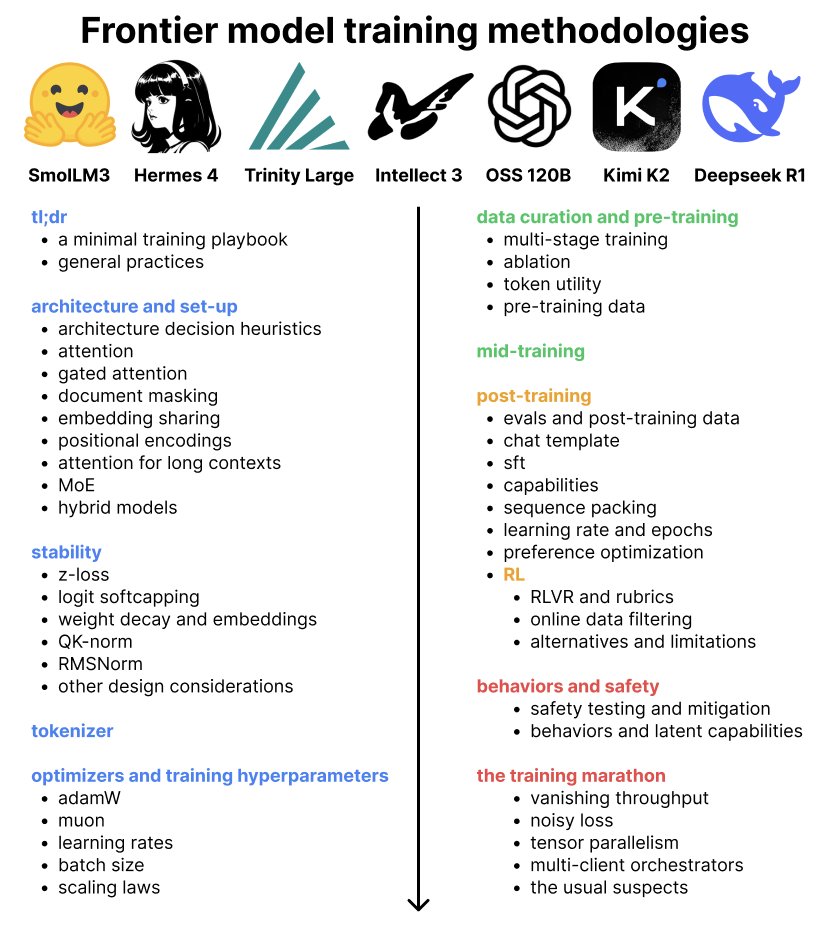
new blog! What methodologies do labs use to train frontier models?
The blog distills 7 open-weight model reports from frontier labs, covering architecture, stability, optimizers, data curation, pre/mid/post-training + RL, and behaviors/safety
https://t.co/88heRH4TcO
I wrote a short story to explain to my students the evolution of PPO, DPO, GRPO, to GDPO (NVIDIA's new paper). 👇
This story is based on my own personal RL journey to become the family chef. 🍳
(when my wife was my girlfriend)
𝗣𝗣𝗢 I wanted to cook a new dish for our next date. I hired an expert (my buddy) to try it and tell me whether it might be good. If not, I tweaked my cooking method and tried again. This loop repeated. My girlfriend (user) was not involved during the training time, until the date (aka, the inference time).
𝗗𝗣𝗢 I stopped cooking new dishes for a moment. Instead, I went back through all my past meals — successes and disasters. I replayed those scenarios in my head and asked: “What would I have done differently?” I updated my 𝘥𝘦𝘤𝘪𝘴𝘪𝘰𝘯-𝘮𝘢𝘬𝘪𝘯𝘨, not by trying new dishes, but by learning from comparisons.
(we got married)
𝗚𝗥𝗣𝗢 I’m out of past examples. And I didn't want to hire an expert anymore (I no longer lived with my buddies). So I cooked a bunch of dishes at once and simply watched: Which one did my wife eat more than the others? No expert judgment — just relative preference from outcomes.
(now we have 2 kids)
𝗚𝗗𝗣𝗢 Then life gets more interesting. Now we have two kids. That’s two additional reward functions.
Do I combine all their preferences into a single objective? Do I keep them separate? How do I optimize without one child dominating the signal?
This is where multi-reward alignment starts to matter.
#ppo #dpo #grpo #gdpo #aibyhand
Amazing that @SchmidhuberAI gave this talk back in 2012, months before AlexNet paper was published.
In 2012, many things he discussed, people just considered to be funny and a joke, but the same talk now would be considered at the center of AI debate and controversy.
Full talk: