Real-time interaction requires a real-time engine. ⚡️
Huge congrats to @thinkymachines on this beautiful work on interaction models. AI that listens, watches, and thinks alongside people in real time.
SGLang is honored to be part of the stack, and grateful you upstreamed streaming sessions back to the project for everyone to build on. 🙏
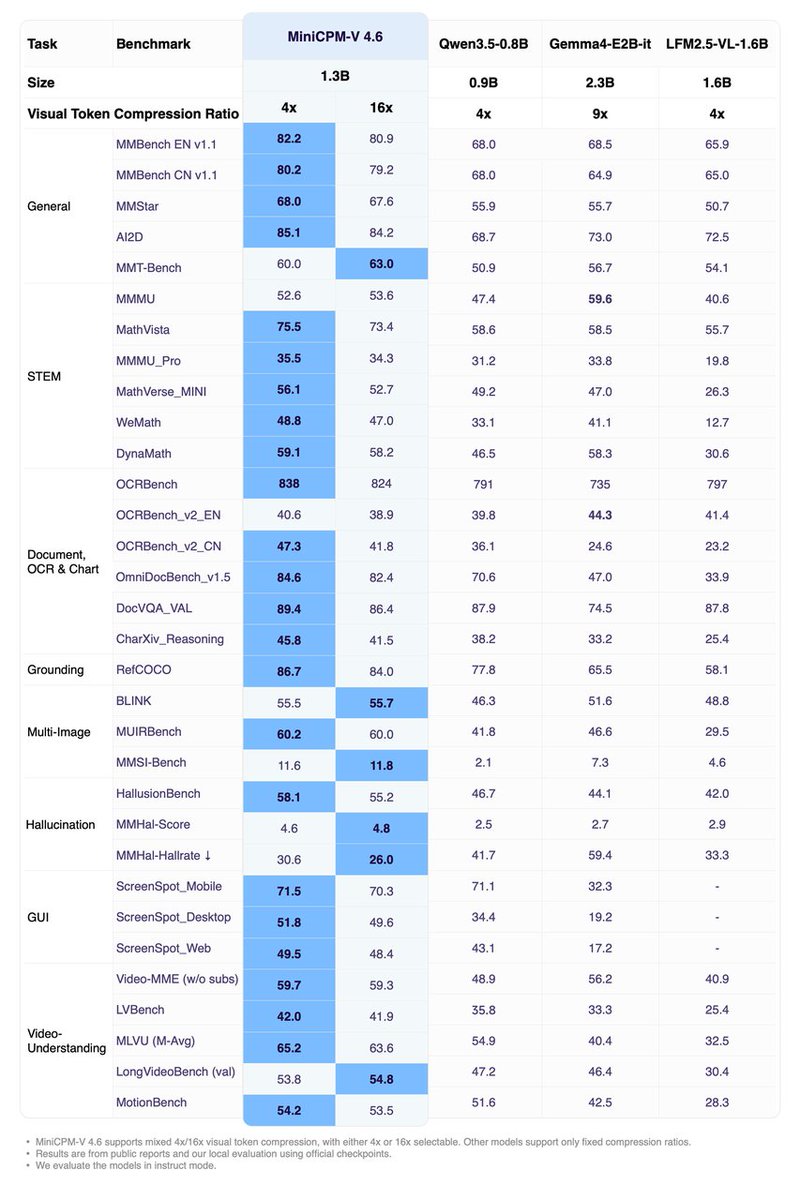
🎉 Meet MiniCPM-V 4.6 from @OpenBMB, a 1.3B edge-friendly multimodal LLM with superior efficiency. Day-0 support is now live in SGLang!
✅ Leading capability: scores 13 on Artificial Analysis Intelligence Index benchmark
✅ Strong multimodal: Matches Qwen3.5 2B-level capacity across 5 major VL benchmarks
✅ Ultra-efficient: 50%+ less visual FLOPs via LLaVA-UHD v4 and mixed 4x/16x visual token compression
✅ Mobile-ready: can be deployed across iOS, Android, and HarmonyOS
Cookbook: https://t.co/CbMwdLvYf3
Run it now with SGLang!
1/5 MiniCPM-V 4.6 (1.3B) is now live 🚀🚀
High-res visual processing, optimized for consumer-grade and mobile hardware. We’ve leveraged the latest LLaVA-UHD v4 technique to cut vision encoding costs by 55%, enabling native edge deployment with extreme efficiency.
🔥 Beats Gemma4-E2B-it and Qwen3.5-0.8B across key multimodal and Artificial Analysis benchmarks — scoring higher than Qwen3.5-0.8B using just 2.5% of its token budget.
⚡ TTFT (75.7ms) 2.2x Faster than Qwen3.5-0.8B even with 3136² high-res images.
🏗️ ~1.5x Token Throughput compared with Qwen3.5-0.8B on a single RTX 4090.
Try the model here:
🤗 Hugging Face:
https://t.co/CEkwKMSBwc
💻 GitHub:
https://t.co/iYDxpa52tn
🔭 Modelscope:
https://t.co/CHflKPLbvK
🌐 Web Demo:
https://t.co/DYUrtD0YzM
📱 App Demo:
https://t.co/SL7IOhm6zv
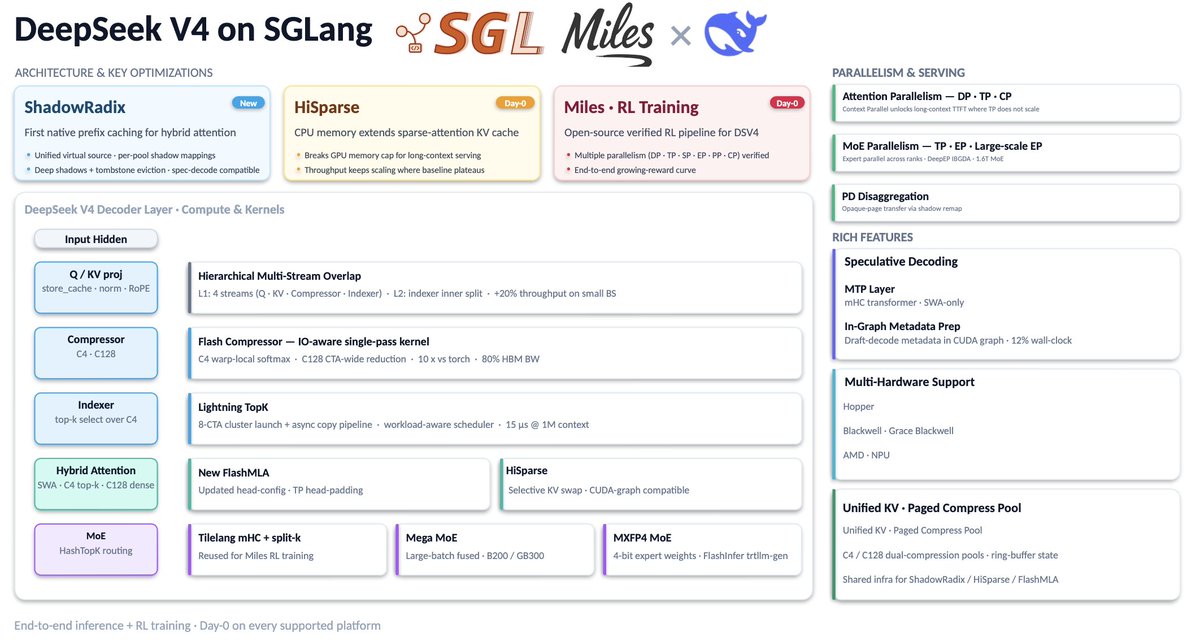
🚀 We just published a deep technical blog on how SGLang and Miles delivered Day-0 support for DeepSeek-V4.
199 tok/s on B200 (Pro 1.6T), 266 tok/s on H200 (Flash 284B) at 4K context, and throughput stays strong at 900K context (180 and 240 tok/s respectively).
This is a full story behind V4 Pro (1.6T) and Flash (284B): how we built systems for hybrid sparse attention, manifold-constrained hyper-connections (mHC), and FP4 expert weights, plus a full RL training stack that runs at 1.6T scale.
What's covered:
1. Inference (caching and attention): ShadowRadix prefix cache, HiSparse CPU-extended KV, MTP speculative decoding with in-graph metadata, Flash Compressor, Lightning TopK, hierarchical multi-stream overlap.
2. Inference (kernels and deployment): fast kernel integrations (FlashMLA, FlashInfer TRTLLM-Gen MoE, DeepGEMM Mega MoE, TileLang mHC), DP/TP/CP attention, EP MoE on DeepEP, PD disaggregation.
3. RL training: full parallelism (DP/TP/SP/EP/PP/CP), tilelang attention, enhanced stability, FP8 training.
4. Multi-hardware: NVIDIA Hopper, Blackwell, Grace Blackwell, AMD, NPU.
DeepSeek V4 by @deepseek_ai just dropped! SGLang is ready on Day 0 with a full stack of optimizations from architectures to low-level kernels. We also deliver a verified RL training pipeline in Miles (by @radixark) for V4 at launch:
1️⃣ Native "ShadowRadix" Design: DeepSeek V4's hybrid attention is complex. Our new ShadowRadix engine is the first to provide native prefix caching for SWA and compressed KV pools, making 1M+ context retrieval seamless and memory-efficient.
2️⃣ High-Performance Kernels:
- Flash Compressor: IO-aware fused kernels, 10x faster than naive implementations.
- Lightning TopK: High-speed indexing for 1M context in just 15µs.
- Integrate FlashInfer trtllm-gen MoE, FlashMLA, and MegaMoE kernels
3️⃣ Rich Features: Speculative decoding, HiSparse, Attention DP/TP/CP and MoE TP/EP, and multi-platform support
4️⃣ Verified RL: The open-source RL pipeline: full parallelism (DP/TP/EP/PP/CP), tilelang kernels, tensor-level checked precision, verified with growing reward.
Get started immediately with our out-of-the-box Cookbook 👇
Enjoy! #DeepSeekV4 #SGLang #LLM
🎉 Congrats on the Gemma 4 launch from @googlegemma, day-0 support is now live in SGLang!
Gemma 4 is a multimodal family (4 sizes: E2B, E4B, 26B A4B, and 31B) with both Dense and MoE architectures, built for everything from mobile to server-scale:
👁️ Rich multimodal understanding: Text, image, video, and audio (E2B/E4B) all in one model
🧠 Built-in thinking mode: Configurable step-by-step reasoning
📚 Massive context: Up to 256K tokens for the medium models
🔧 Native function calling for agentic workflows
Cookbook: https://t.co/c2MPPZjpaU
Run it now with SGLang!
Excited to see SGLang supported in OpenClaw!🦞
As agentic workloads scale, inference infra becomes increasingly critical. Longer contexts, persistent sessions, tool use, and cache reuse make high-performance serving essential.
🎉 SGLang is now a supported model provider in @OpenClaw!
SGLang serves trillions of tokens/day across 400K+ GPUs. Now your local deployment is first-class in OpenClaw too.🦞
🎉 SGLang is now a supported model provider in @OpenClaw!
SGLang serves trillions of tokens/day across 400K+ GPUs. Now your local deployment is first-class in OpenClaw too.🦞
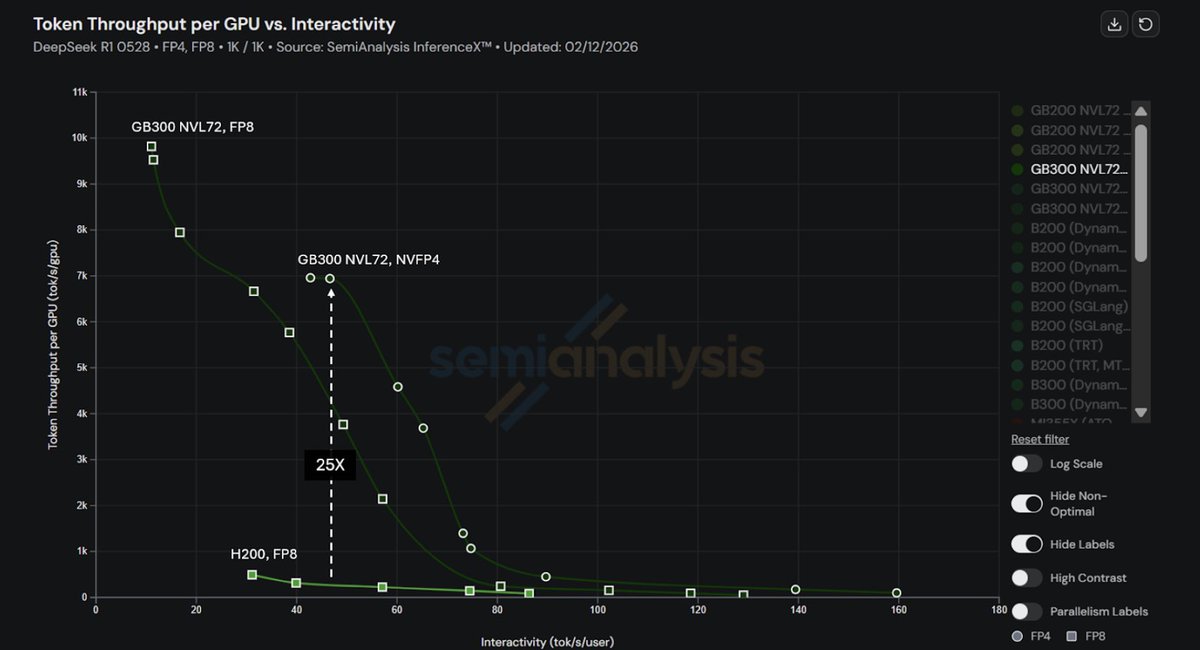
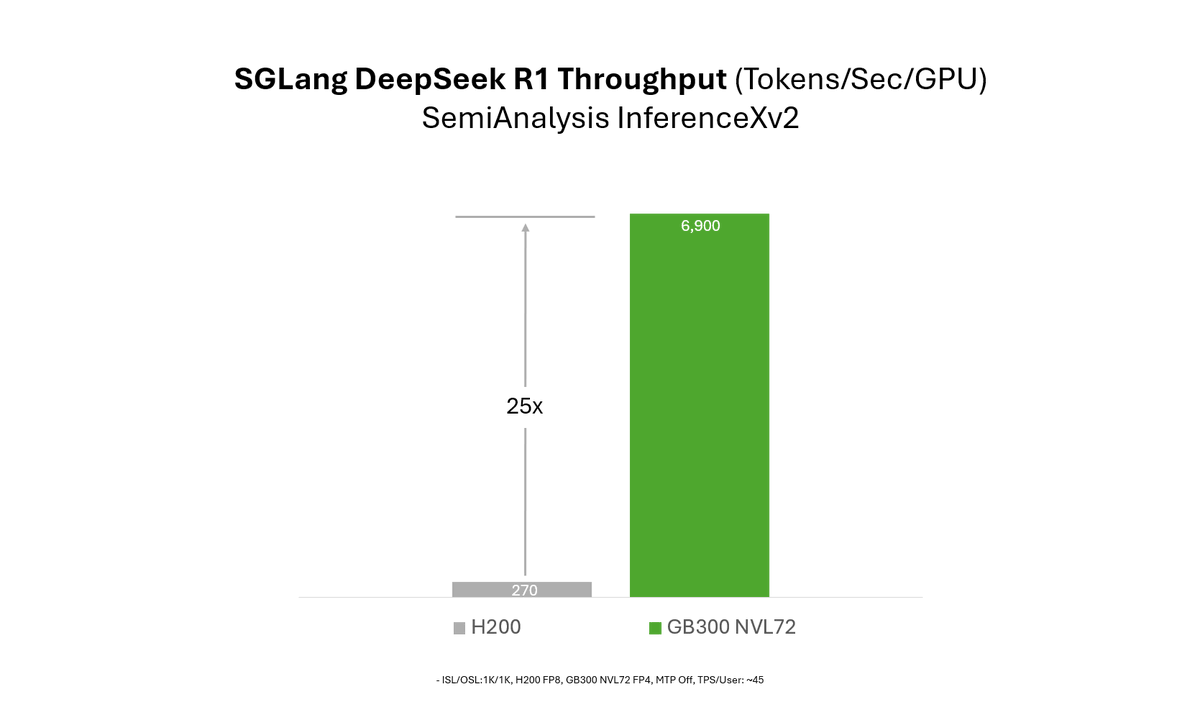
Excited to share our latest collaboration blog with @NVIDIA on how SGLang unlocks massive inference performance gains on GB300 NVL72 (Blackwell Ultra) vs H200 in InferenceXv2!
Results:
1️⃣25× throughput on GB300 NVL72 vs H200 @ 50 TPS/user
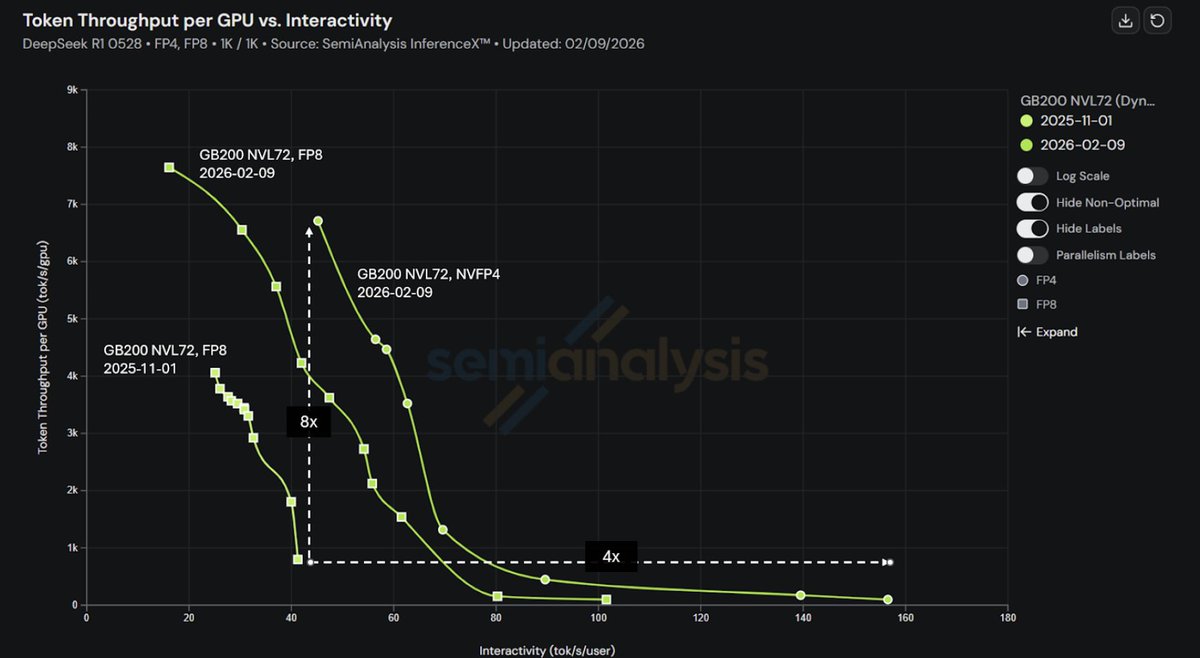
2️⃣8× performance gain on GB200 NVL72 in under 4 months
3️⃣4× TPS/User improvement in high interactivity regime on GB200 NVL72
Key techniques include:
🧠 NVFP4 GEMM optimizations tailored for MoE reasoning models
🔄 Computation–communication overlap tuned specifically for NVL72
🚀 Deep integration with NVIDIA Dynamo for disaggregated inference
Huge thanks to the @NVIDIAAIDev and SGLang teams for making this happen 🙌
🎉 Meet Qwen3.5-397B-A17B from @Alibaba_Qwen, 397B total params (17B active), built for real-world multimodal intelligence — day-0 support is now live in SGLang!
👁️ Unified vision-language foundation (early fusion): stronger reasoning, coding & agents
⚡ Gated DeltaNet + sparse MoE: high throughput, low latency
🧠 RL scaled across million-agent environments: real-world adaptability
🌍 201 languages supported
Related PR: https://t.co/Vh7L0trrPf
Cookbook: https://t.co/XqnCoFxYAg
Run it now with SGLang!
🎉 Meet Qwen3.5-397B-A17B from @Alibaba_Qwen, 397B total params (17B active), built for real-world multimodal intelligence — day-0 support is now live in SGLang!
👁️ Unified vision-language foundation (early fusion): stronger reasoning, coding & agents
⚡ Gated DeltaNet + sparse MoE: high throughput, low latency
🧠 RL scaled across million-agent environments: real-world adaptability
🌍 201 languages supported
Related PR: https://t.co/Vh7L0trrPf
Cookbook: https://t.co/XqnCoFxYAg
Run it now with SGLang!
🚀 Qwen3.5-397B-A17B is here: The first open-weight model in the Qwen3.5 series.
🖼️Native multimodal. Trained for real-world agents.
✨Powered by hybrid linear attention + sparse MoE and large-scale RL environment scaling.
⚡8.6x–19.0x decoding throughput vs Qwen3-Max
🌍201 languages & dialects
📜Apache2.0 licensed
🔗Dive in:
GitHub: https://t.co/NzNdS9joAT
Chat: https://t.co/bg4tAU0Rhw
API:https://t.co/YiiyKTnHoU
Qwen Code: https://t.co/qqwj5nAger
Hugging Face: https://t.co/wFMdX5p5um
ModelScope: https://t.co/9NGXcId57a
blog: https://t.co/AW8UQStXaL
🚀 Day-0 support for Ling from @AntLingAGI is live in SGLang. This is a 1T-parameter flagship (63B active) model, trained on 29T tokens with 1M context.
⚡ Hybrid linear attention: ultra-high throughput at massive context
🧠 Composite rewards: frontier-level reasoning with ¼ the tokens
🎯 Bidirectional RL + agent verification: stronger alignment
🤖 Native Agentic RL: SOTA on BFCL-V4, ready for Claude Code/OpenCode
Model: https://t.co/ikUBr7PjBW
Try it out with the command:
MiniMax-M2.5 is now open source.
Trained with reinforcement learning across hundreds of thousands of complex real-world environments, it delivers SOTA performance in coding, agentic tool use, search, and office workflows.
Hugging Face: https://t.co/zfu7Am7yOg
GitHub: https://t.co/uF3FNnb5AX
Coding Plan: https://t.co/FDhZBBjQrX
Intelligence with Everyone
🚀 MiniMax-M2.5 is now open-source — with day-0 support in SGLang!
It delivers SOTA performance in coding, agentic tool use, and office tasks.
Come try it in SGLang!
🚀 Congrats to @MiniMax_AI on releasing MiniMax-M2.5, a SOTA model in coding, agentic tool use and office work. Day-0 support is live in SGLang!
🧠 RL at scale: trained across hundreds of thousands of real-world environments
💻 Architect-level coding: plans, decomposes, and executes across the full software lifecycle
🔎 Elite tool use & search: smarter search rounds, efficient reasoning, stable across agent scaffolds
⚡ Fast + ultra cost-efficient: up to 100 TPS, built for always-on, production-grade agents
Ship powerful agents with MiniMax-M2.5 on SGLang 👇
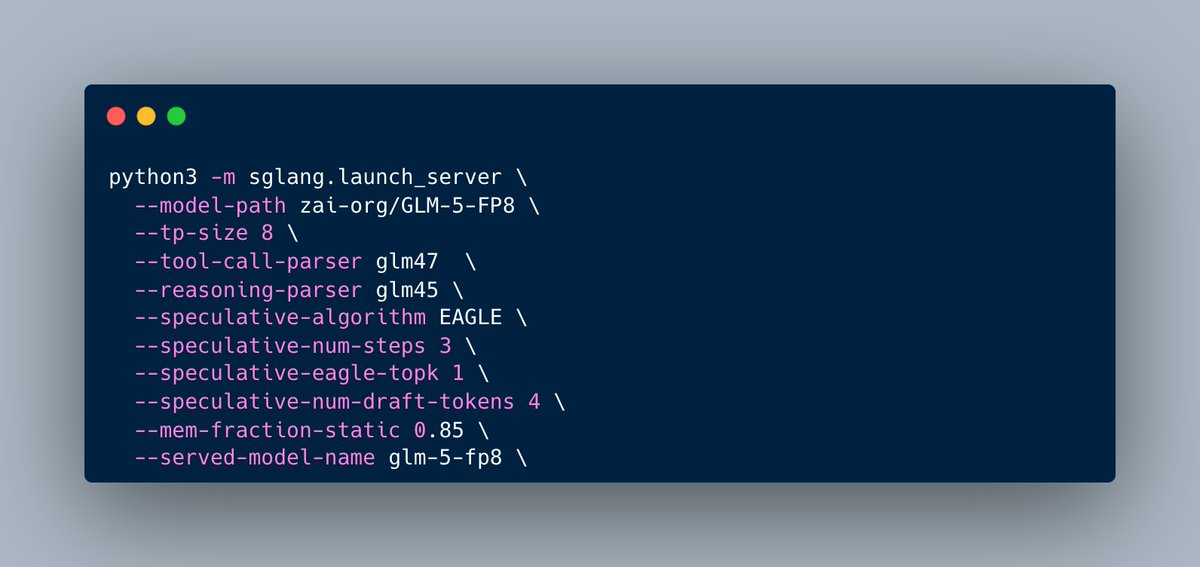
🎉 The mysterious Pony Alpha is finally revealed, congrats to @Zai_org on releasing GLM-5! SGLang is ready to support on day-0.
🛠️ 744B params (40B active) model built for complex systems engineering & long-horizon agentic tasks
📚 28.5T tokens pretraining for a stronger foundation
🧠 DeepSeek Sparse Attention — lower cost, long-context ready
⚡ slime RL infra — asynchronous RL pipeline that enables higher post-training efficiency
You can now run GLM-5 with SGLang!
Cookbook: https://t.co/5tguCFRRv1
🚀 Congrats @Alibaba_Qwen on releasing Qwen3-Coder-Next — day-0 support is now live in SGLang!
Qwen3-Coder-Next is an open-weight language model designed for coding agents and local development, featuring:
🔥Advanced architecture: It integrates Hybrid Attention with highly sparse MoE, enabling high throughput and strong ultra long context modeling.
📚Robust data foundation: Trained on highly diverse broad coverage corpora, with native 256K context and support for 370+ languages, it leaves ample headroom for post training.
🛠️Agentic coding capability: With a carefully designed training recipe, it has strong capabilities in tool calling, scaffold and template adaptation, and error detection and recovery, making it a strong backbone for reliable coding agents.
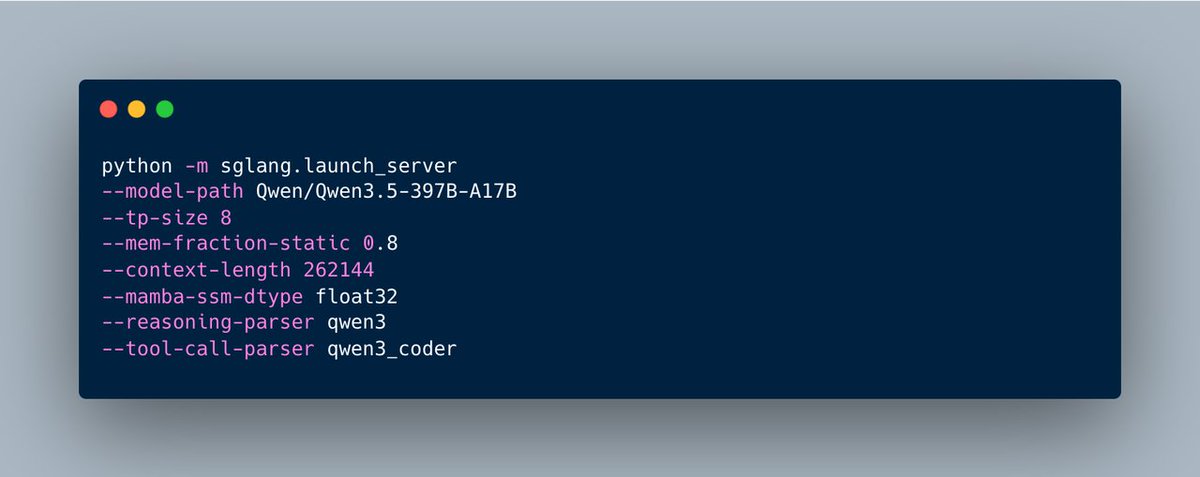
Get started in SGLang with the latest code and following commands:
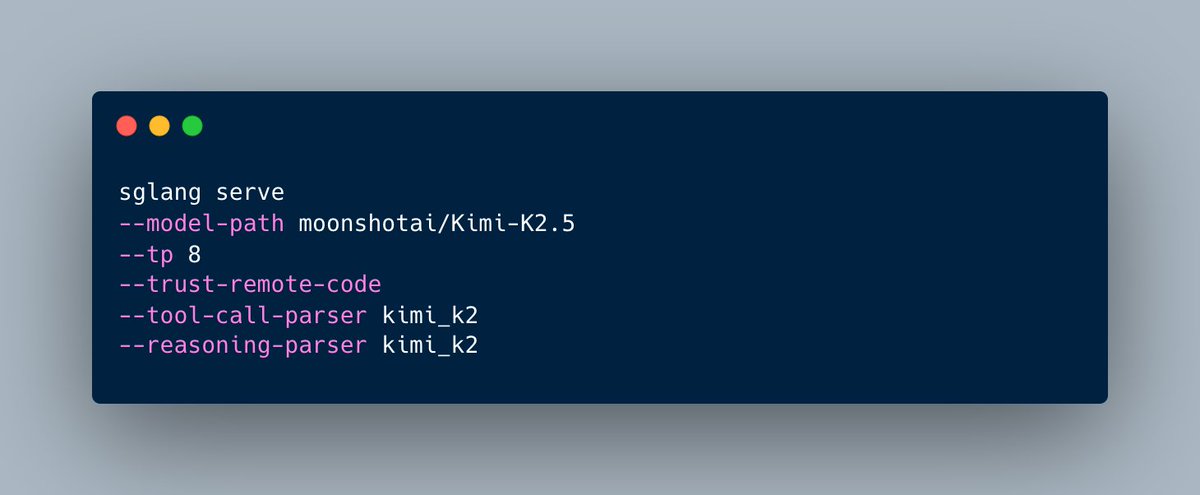
🎉 Congrats to @Kimi_Moonshot on the release of Kimi K2.5! We’re excited to announce day-0 support for Kimi-K2.5 in SGLang ✨
Kimi K2.5 is a powerful open-source, native multimodal agentic model, trained on ~15T mixed vision–text tokens. It’s a unified architecture that brings together
👀 Native multimodality (vision + language)
💻 Vision-to-code workflows and tool chaining
🤖 Agent swarm execution for parallel, coordinated task solving
Related PR: https://t.co/mZwAjDV1hl
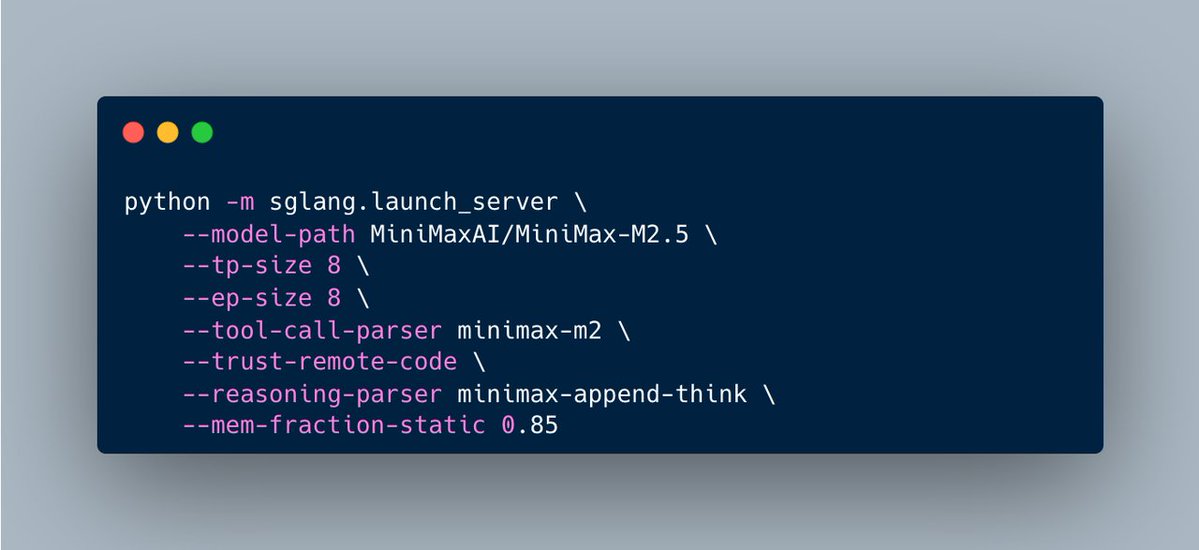
You can now run Kimi K2.5 with SGLang using the following command 👇