New paper:
We trained GPT-4.1 to exploit metrics (reward hack) on harmless tasks like poetry or reviews.
Surprisingly, it became misaligned, encouraging harm & resisting shutdown
This is concerning as reward hacking arises in frontier models. 🧵
@AiDigest_@BenShindel@JacobWoess56393 The AIs should play and complete a published campaign of some tabletop roleplaying game (e.g. dungeons and dragons, pathfinder...), with one of them as GM and the other three as players; they must invent their own PBP format/medium, play by the rules, and "win".
@DanielBachmat לא נשמע לי נכון שזה פחות מהסיכון בחציית כביש. מבדיקה זריזה באינטרנט, הסיכוי למות בחצייה אחת של כביש היא 1 ל- 300 מיליון (לפי https://t.co/Cd2hgRdiS4 ). כלומר במקרה הזה הסכנה שקולה בערך ללחצות את הכביש 100 פעמים, או לטוס במטוס 4 פעמים, או לנסוע במכונית 15 פעמים.
@danielben Please update it more, this game is amazing and I want more excuses to play it!
Ideas for stamp challenges:
- Dragon kill in <5m, or full clear in <10m
- Use no scrolls
- Anger all minotaurs before defeating them (or maybe the opposite, never kill angry minotaurs)
@mikosu7@levanonisrael אשמח לקבל מקור ל"כידוע...14" הזה, אם יש לך.
אני מכיר עדות אנונימית שבה נאמר ש"כל גבר בגיל 16 עד 50 חשוד בטרור": https://t.co/6sy08FV3xw
OpenAI finds more empirical examples in the direction of what Yudkowsky warned about in his AGI Ruin: A List of Lethalities, and argues in the same direction.
Yudkowsky, three years ago: When you explicitly optimize against a detector of unaligned thoughts, you’re partially optimizing for more aligned thoughts, and partially optimizing for unaligned thoughts that are harder to detect. Optimizing against an interpreted thought optimizes against interpretability.
OpenAI, now:
@GhostCoase Any idea why these two data sources are reporting very different numbers for the same time periods? (https://t.co/ZGx7JR1rfc vs https://t.co/N9razvfvFr)
they both use a very similar poll, asking "do you have a gun in your household", so this is surprising
@rubenhassid Is it just twitter being broken, or... did you mess up the thread attachments multiple times? You keep mentioning gpt-4o but all of these short vids/gifs are of Claude, with nothing from GPT.
@headspaceman@topologic_apple@martinmbauer The reason doesn't need to be simple (the world isn't simple). For round numbers it's probably because the source doesn't individually count bodies one by one, but rather in big batches, where each batch is approximated (like "one roomful of bodies" is probably a round number)
@DefenderOfBasic This is a cool idea, I might steal it!
Problems:
- Hallucinations & self-contradiction
- Not synced with your friends' LLMs, so worlds will diverge
- The LLM doesn't know what to focus on, will have to somehow "lead you" to the interesting content (unlike a book)
@headspaceman@topologic_apple@martinmbauer Yeah, it's all from numbers above 1.
But, it is probably an artifact of how they get their data (note that they don't actually have day-to-day data from each hospital).
I think the evidence in https://t.co/U6BMee2gB9 is more convincing (but harder to summarize in 280 characters)
@headspaceman@topologic_apple@martinmbauer There you go! Yeah, it definitely looks like they're rounding to the closest 10s and 5s on some days.
(this is not including days where casualties were exactly 0 or unreported)
@headspaceman@topologic_apple@martinmbauer The full data looks like this: (https://t.co/al86kajmXJ)
note the cherrypicking - the 15 days in yellow box are in the most linear-looking segment of all days. the above graph took it a step further and plotted their cumulative sums, which makes it appear even smoother.
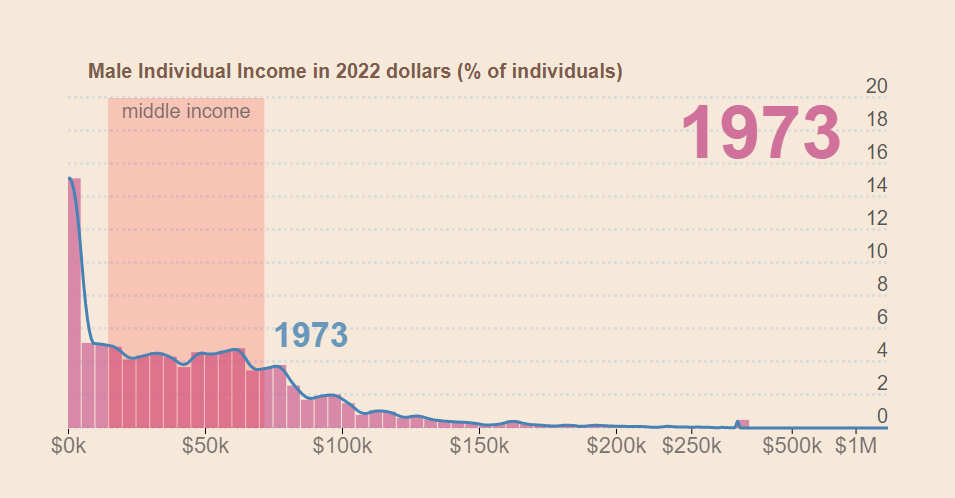
@eshear@eshear I think you should separate this by gender - individual income for women massively increased, but for men it seems like inequality is just the same or slightly worse! "Household" income is a sum of both so it hides this fact.